
| 图 1 研究路线图 |

| 图 2 Flume配置文件 |

| 图 3 hive中创建表格展示 |

| 图 4 大数据分析源码 |


| 图 5 sqoop导出数据源码 |

| 图 6 淘宝店家数据分析 |

| 图 7 某时刻用户购物情况分析 |

| 图 8 购买次数大于2的与总人数比率 |

| 图 9 店肆的跳失率 |

| 图 10 淘宝用户举动分析 |
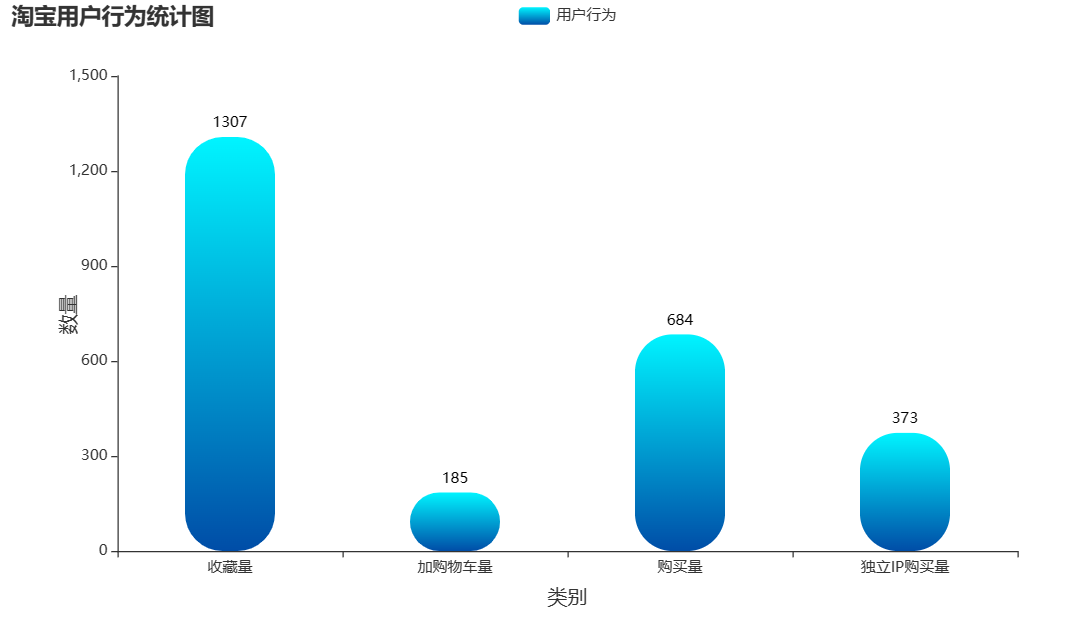
| 图 11 用户购物情况分析 |

| 图 12 用户地理位置购买情况 |

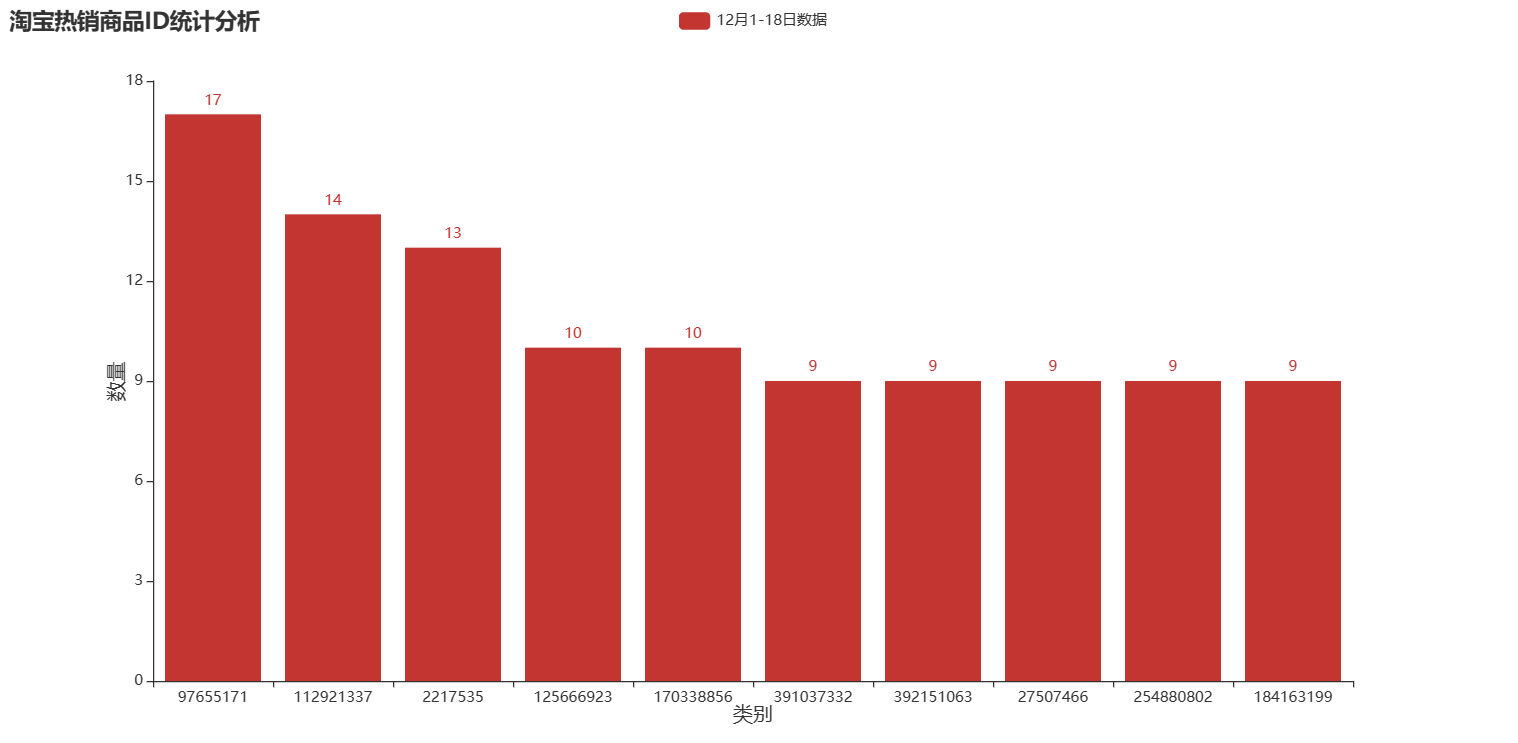
| 图 13 淘宝热销商品ID统计分析 |
| 图 14 淘宝商品类目统计 |

| 图 15 12月1日-12月18用户活跃度分析 |

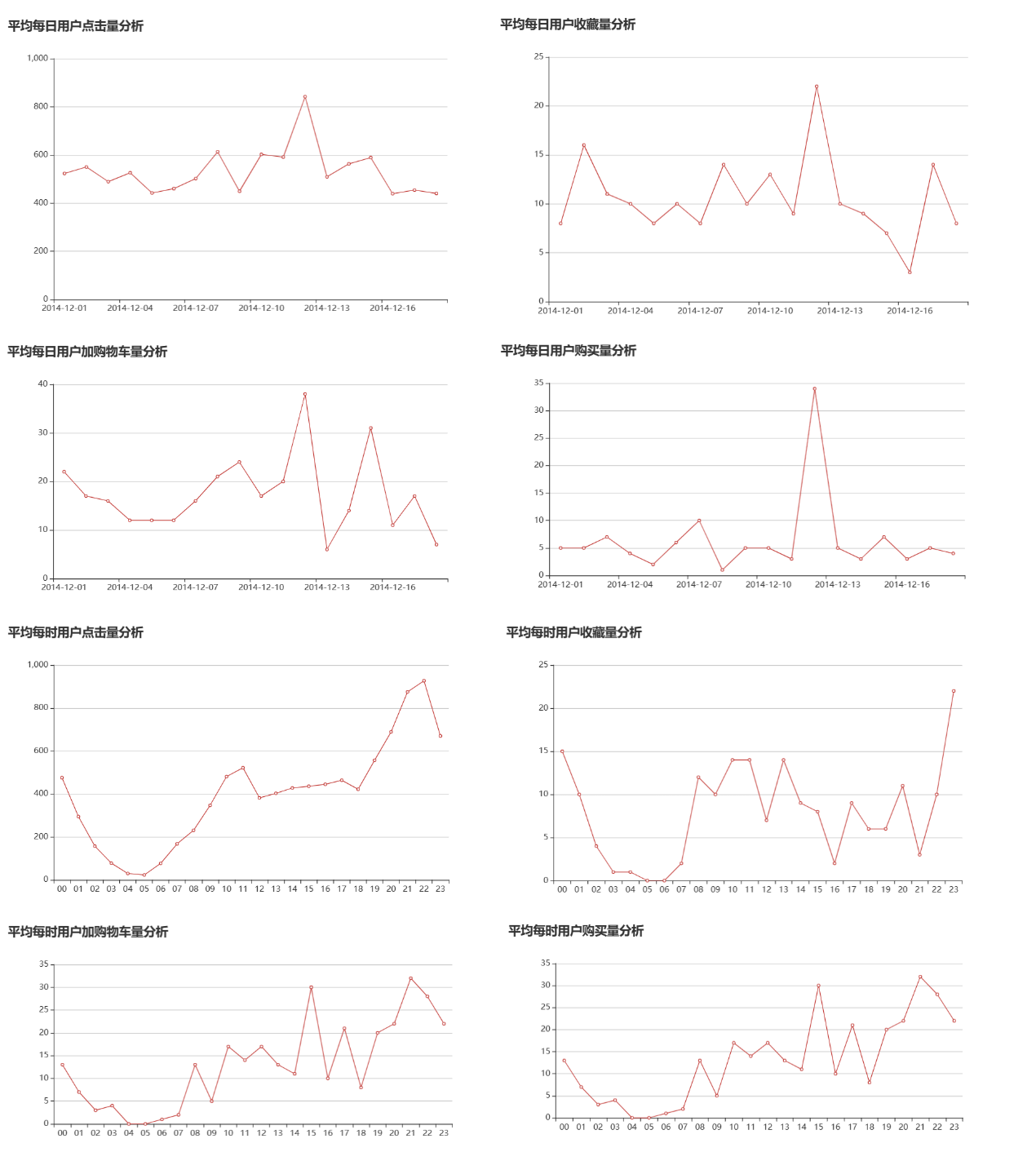
| 图 16 均匀每日用户点击量分析 |

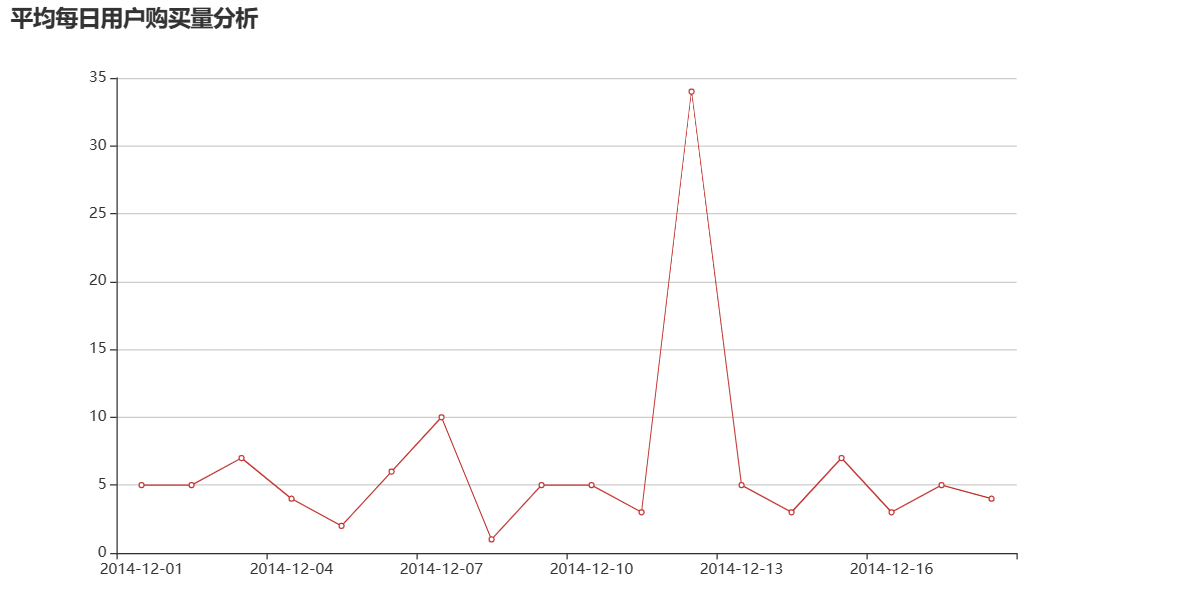
| 图 17 均匀每日用户购买量分析 |
| 图 18 均匀每日用户加购物车量分析 |

| 图 19 均匀每日用户收藏量分析 |

| 图 20 均匀每日用户活跃度分析 |


| 图 21 均匀每时用户点击量分析 |

| 图 22 均匀每时用户购买量分析 |
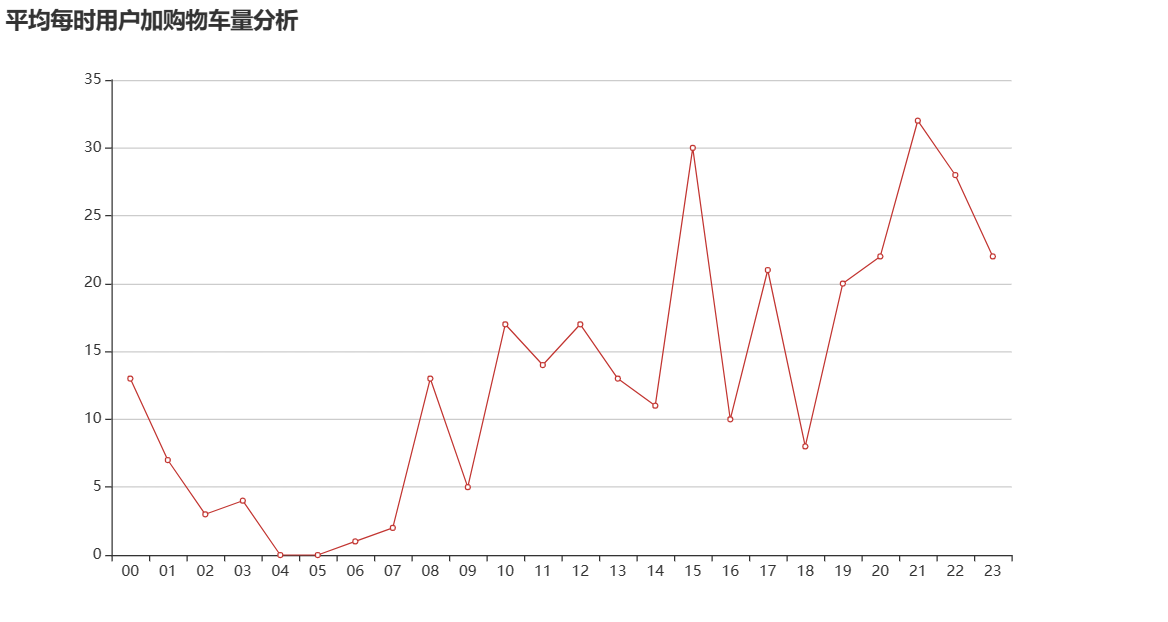
| 图 23 用户每时加购物车量分析 |

| 图 24 均匀每时用户收藏量分析 |
| 图 25 可视化大屏1 |

| 图 26 大屏可视化2 |

| 图 27 大屏可视化3 |
| 图 28 大屏可视化 |

| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |