Linux 基金会的 Delta Lake
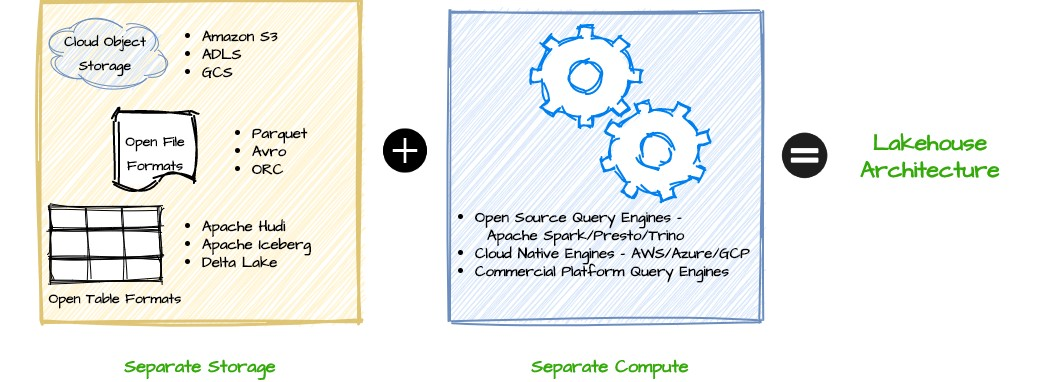
Databricks 将 Delta Lake 作为一个内部项目启动,厥后在 Linux 基金会下将其开源。它通常被称为用于构建 Lakehouse 架构的开源存储框架。 Delta Lake 为数据湖提供元数据层和 ACID 功能。它还提供时间回溯、schema 推演以及审计跟踪记录等功能。
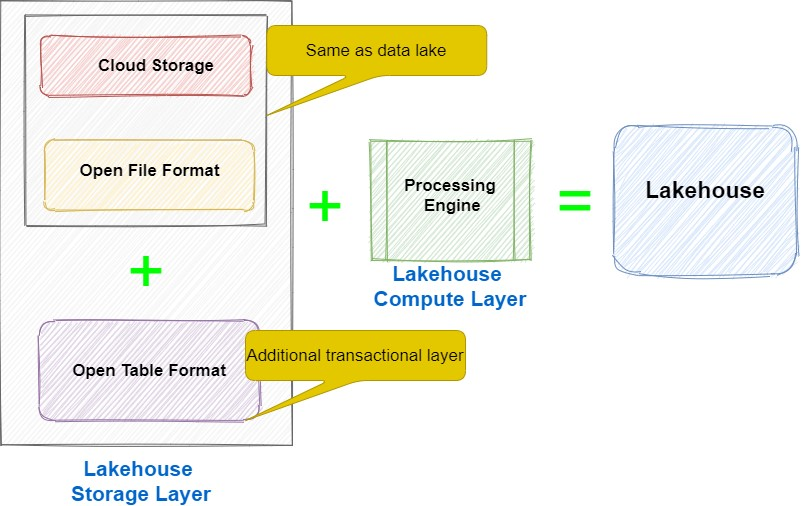
计算层
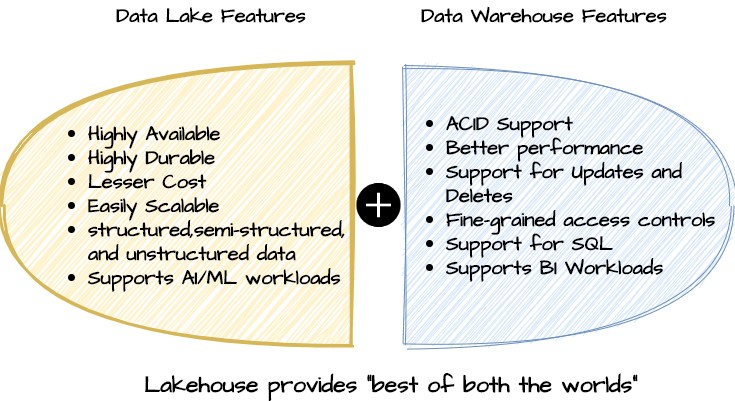
Lakehouse 架构的主要优点之一是其开放性以及可由任何兼容处理引擎直接访问或查询的能力。它不需要任何特定的专有引擎来运行 BI 工作负载或交互式分析。这些计算引擎可以是开源的,也可以是专为 Lakehouse 架构设计的专用商业查询引擎。