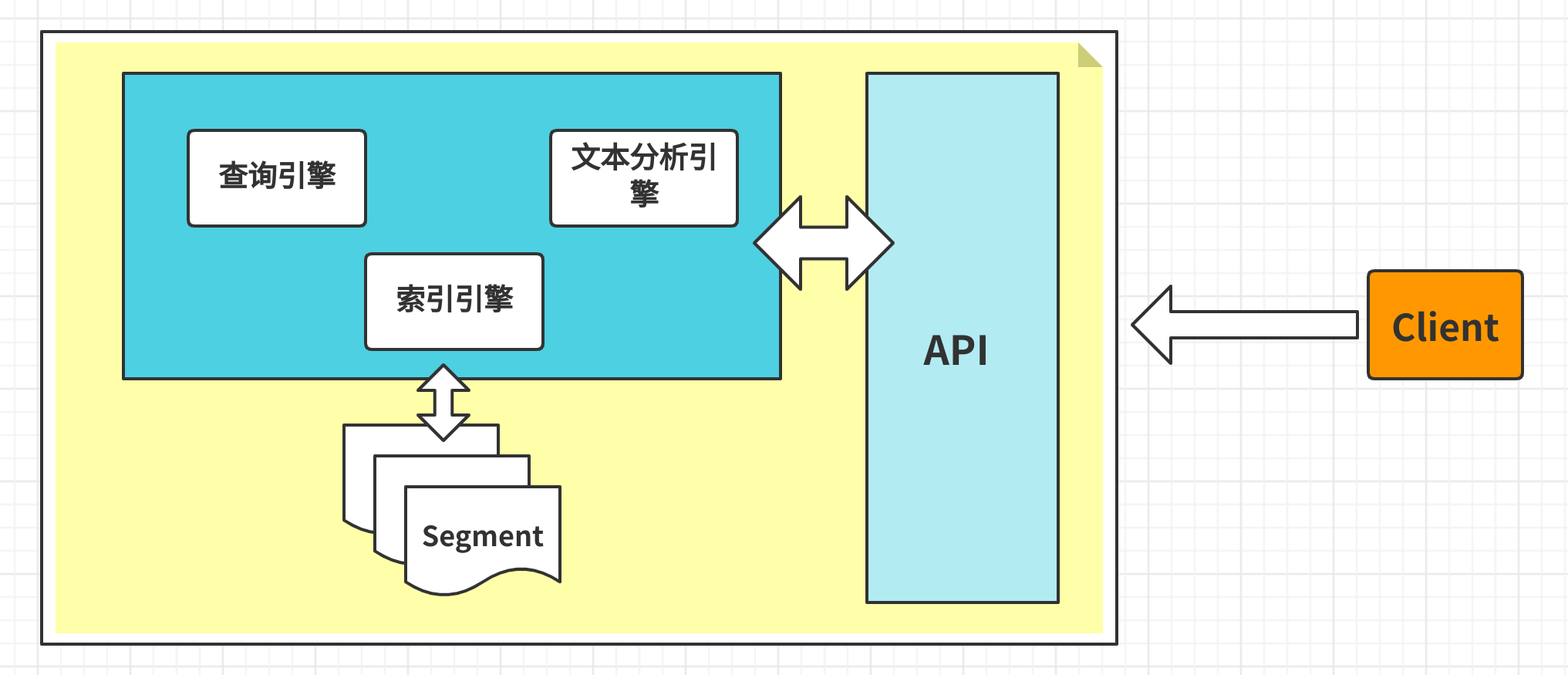
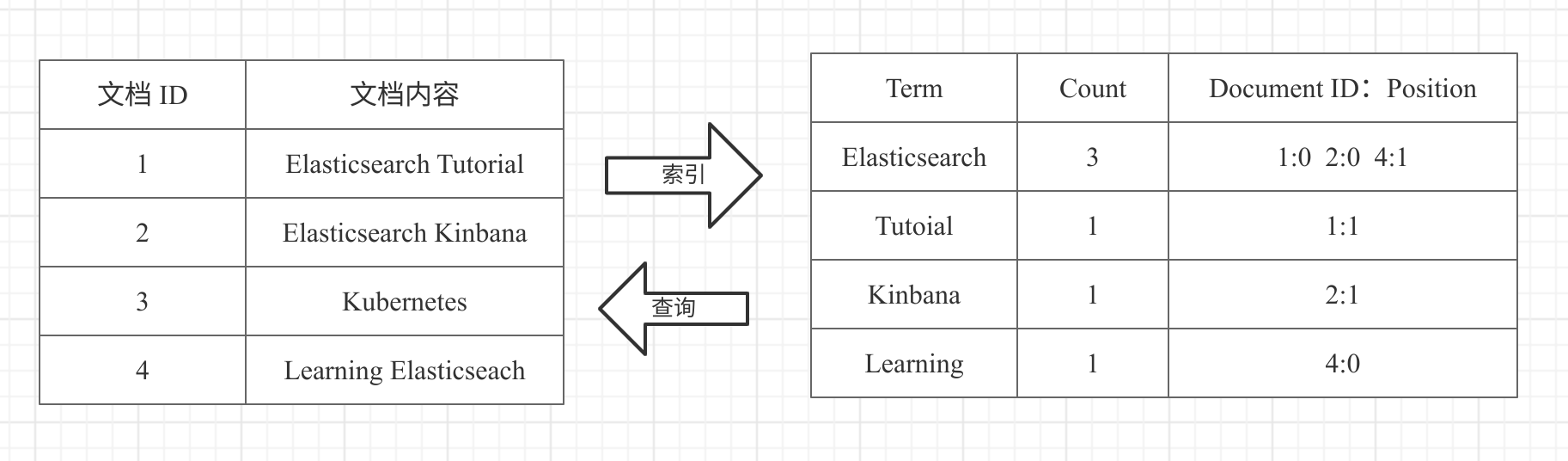
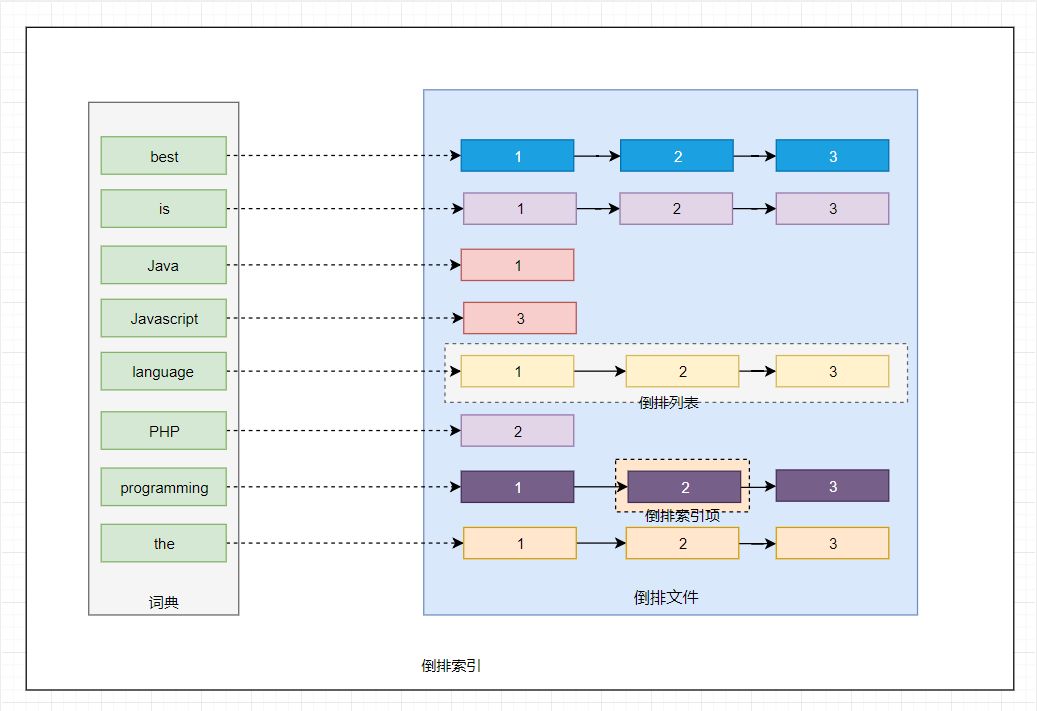
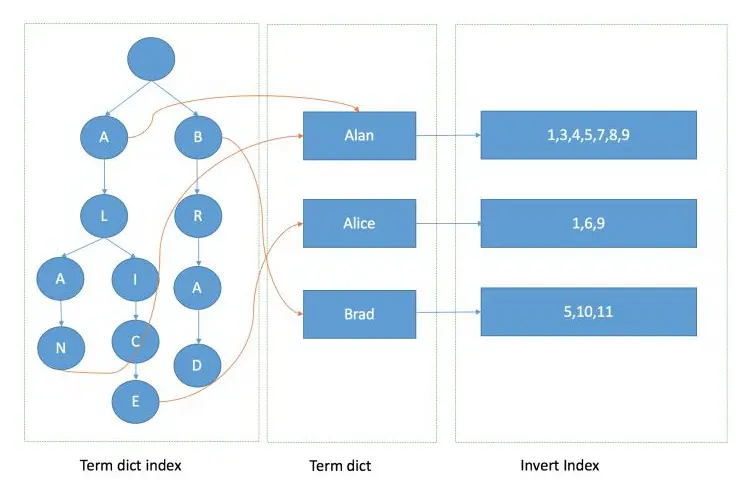
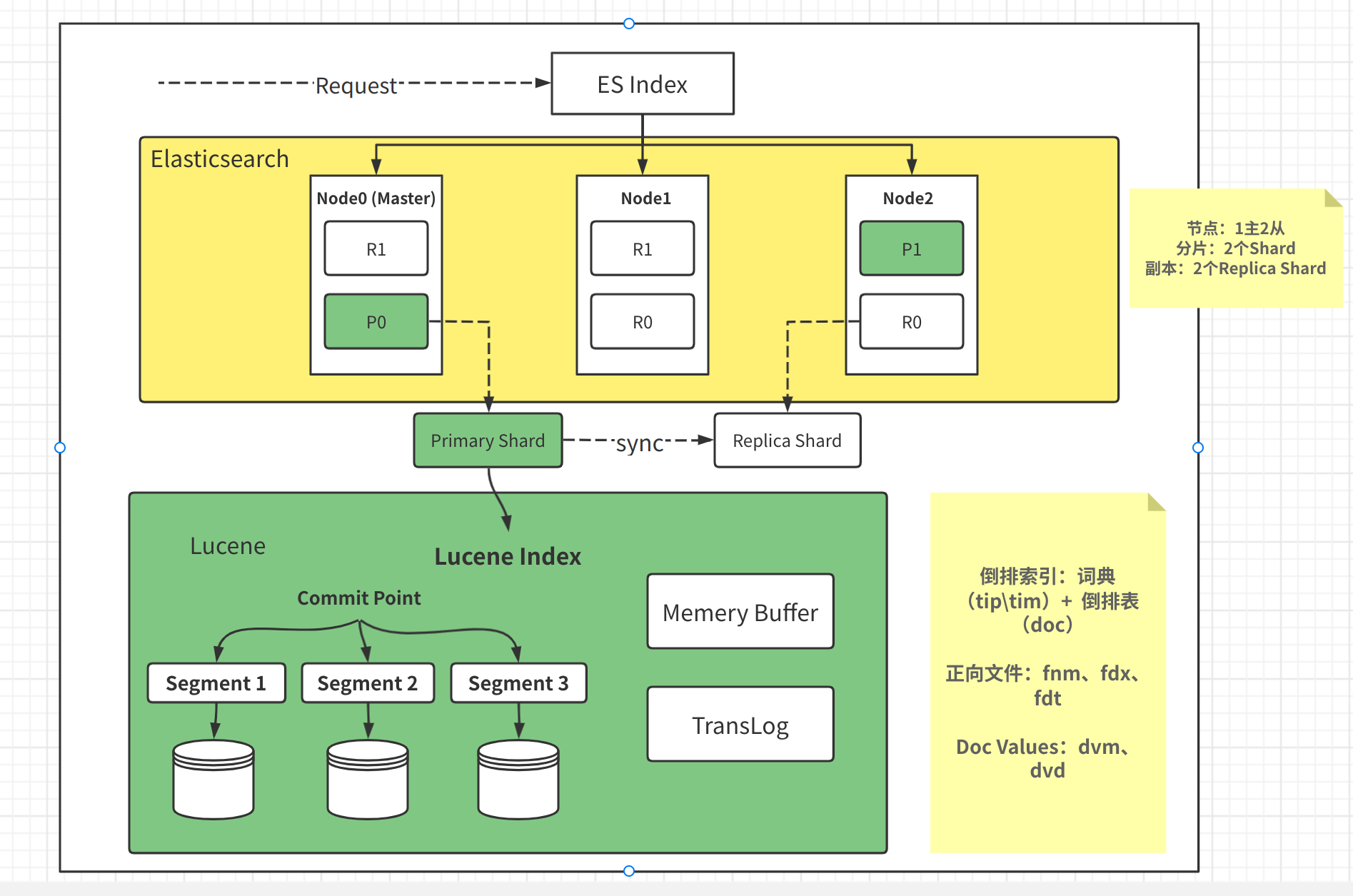
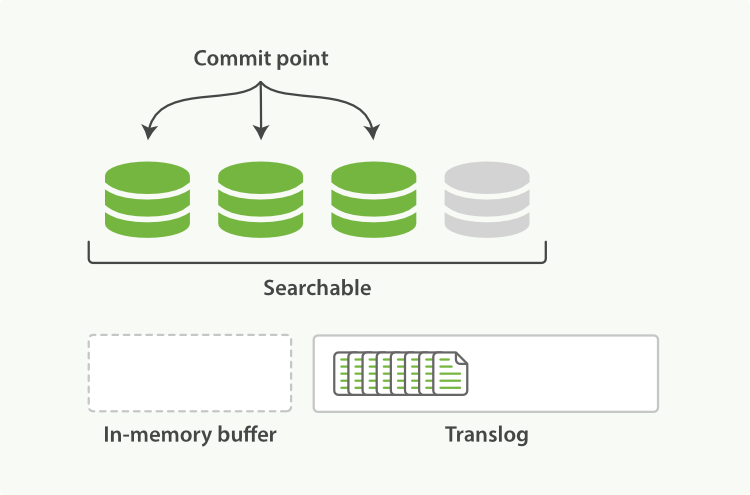
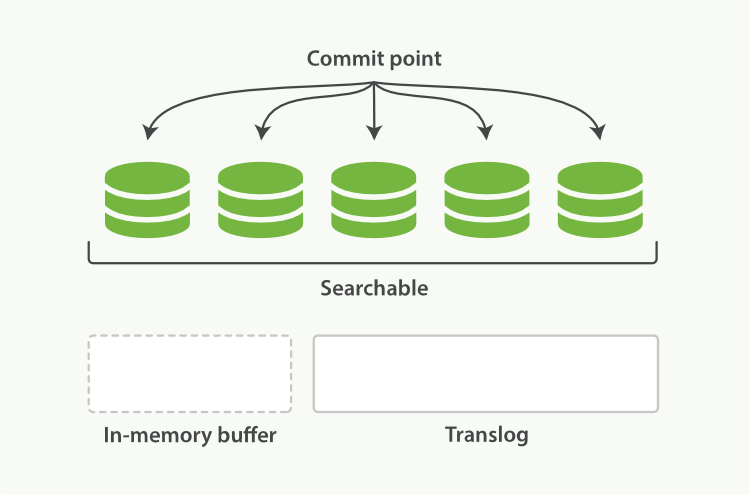
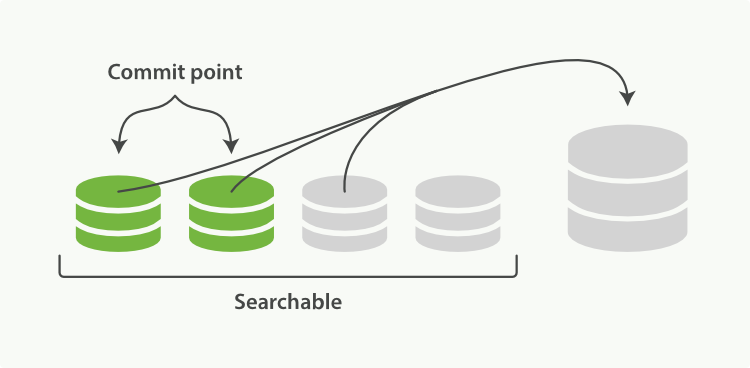
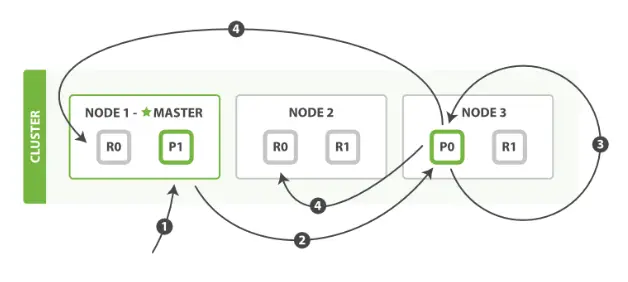
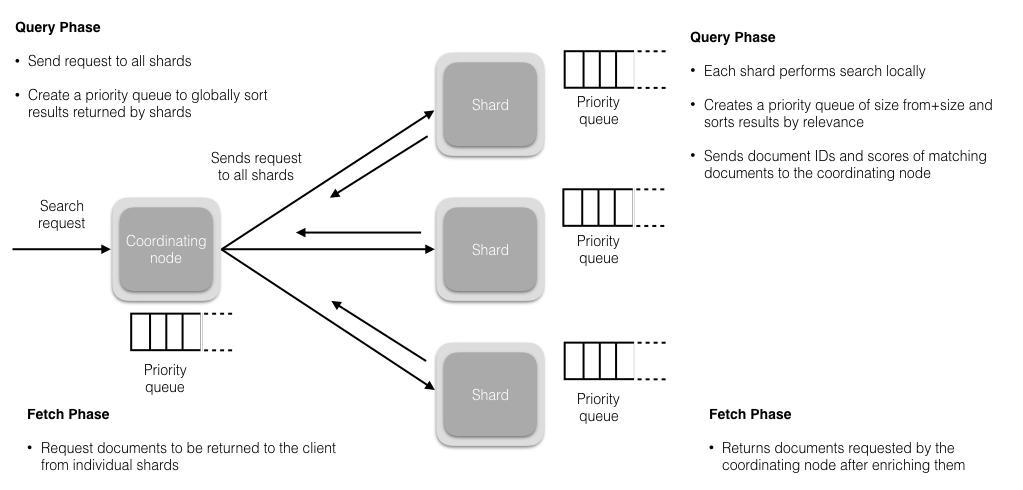
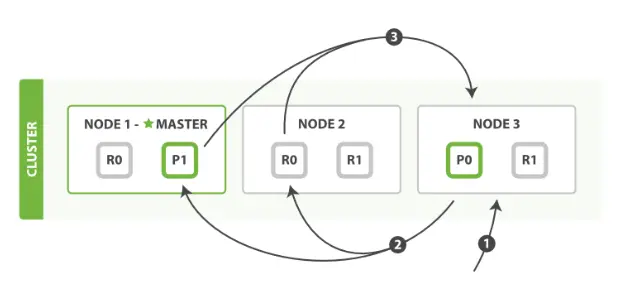
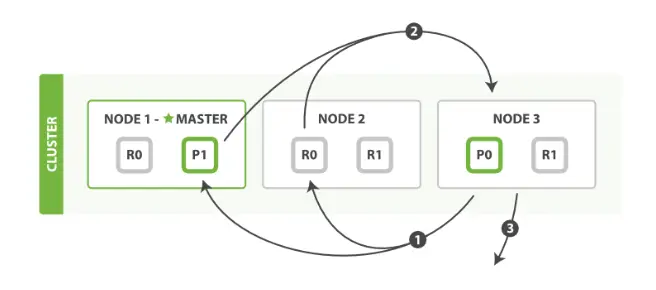
解决方案1:服务端缓存 Scan and scroll API
为了返回某一页记载,其实我们抛弃了其他的大部分已经排好序的效果。那么简单点就是把这个效果缓存起来,下次就可以用上了。根据这个思绪,ES提供了Scroll API。它概念上有点像传统数据库的游标(cursor)。
scroll调用本质上是及时创建了一个快照(snapshot),然后保持这个快照一个指定的时间,这样,下次请求的时候就不需要重新排序了。从这个方面上来说,scroll就是一个服务端的缓存。既然是缓存,就会有下面两个问题:
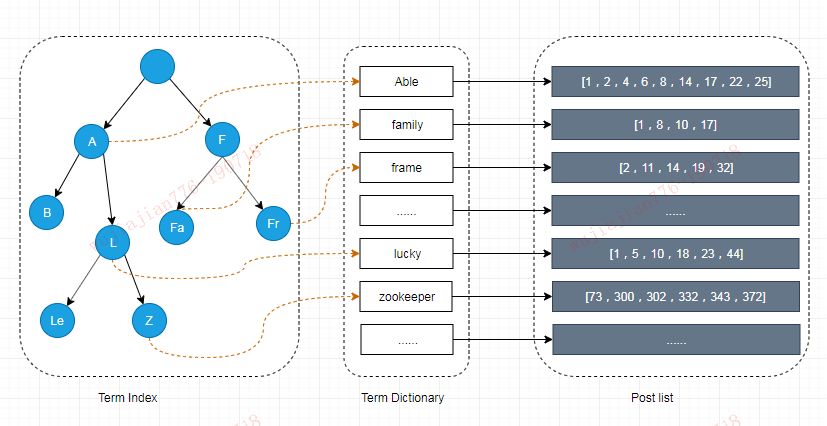
Elasticsearch 为了能快速找到某个 Term,先将全部的 Term 排个序,然后根据二分法查找 Term,时间复杂度为 logN,就像通过字典查找一样,这就是 Term Dictionary。
现在再看起来,似乎和传统数据库通过 B-Tree 的方式类似。但是假如 Term 太多,Term Dictionary 也会很大,放内存不实际,于是有了 Term Index。
就像字典里的索引页一样,A 开头的有哪些 Term,分别在哪页,可以理解 Term Index是一棵树。
这棵树不会包含全部的 Term,它包含的是 Term 的一些前缀。通过 Term Index 可以快速地定位到 Term Dictionary 的某个 Offset,然后从这个位置再今后顺序查找。
在内存中用 FST 方式压缩 Term Index,FST 以字节的方式存储全部的 Term,这种压缩方式可以有效的缩减存储空间,使得 Term Index 足以放进内存,但这种方式也会导致查找时需要更多的 CPU 资源。
对于存储在磁盘上的倒排表同样也采用了压缩技能减少存储所占用的空间。
调解设置参数
调解设置参数建议如下:
给每个文档指定有序的具有压缩良好的序列模式 ID,制止随机的 UUID-4 这样的 ID,这样的 ID 压缩比很低,会明显拖慢 Lucene。
对于那些不需要聚合和排序的索引字段禁用 Doc values。Doc Values 是有序的基于 document=>field value 的映射列表。
不需要做模糊检索的字段利用 Keyword 类型代替 Text 类型,这样可以制止在建立索引前对这些文本举行分词。