IT评测·应用市场-qidao123.com
标题:
Linux dd工具使用(测试性能流程)
[打印本页]
作者:
莱莱
时间:
2024-7-24 08:27
标题:
Linux dd工具使用(测试性能流程)
Linux dd工具使用(测试性能流程)
1 先容及参数阐明
Linux dd 命令用于读取、转换并输出数据。
常被用来测试磁盘读写性能。
dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。
if=文件名:输入文件名,默认为标准输入。即指定源文件。
of=文件名:输出文件名,默认为标准输出。即指定目的文件。
# if(input) 输入设备,/dev/zero可无穷无尽的提供0
# if=/dev/zero (输入数据全为0)
# of(output)输出设备,将数据输出到哪个位置,of
# of=/root/bucket-331/1G_{}.txt
## /dev/zero与/dev/null关系
## 1. /dev/null 无敌洞(可以向他输出任何数据)
## 2. /dev/zero 可以产出无穷无尽的零
ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
bs=bytes:同时设置读入/输出的块大小为bytes个字节。
cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
conv=<关键字>,关键字可以有以下11种:
conversion:用指定的参数转换文件。
ascii:转换ebcdic为ascii
ebcdic:转换ascii为ebcdic
ibm:转换ascii为alternate ebcdic
block:把每一行转换为长度为cbs,不足部分用空格填充
unblock:使每一行的长度都为cbs,不足部分用空格填充
lcase:把大写字符转换为小写字符
ucase:把小写字符转换为大写字符
swap:交换输入的每对字节
noerror:出错时不停止
notrunc:不截短输出文件
sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
--help:显示帮助信息
--version:显示版本信息
复制代码
2 常用配套命令
2.1 测试硬盘读写速度
# 通过下面两个命令输出的命令执行时间,可以计算出硬盘的读、写速度。
dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file
dd if=/root/1Gb.file bs=64k | dd of=/dev/null
复制代码
2.2 确定硬盘最佳块大小
# 根据下面命令显示的执行时间,确定系统最佳块大小
dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file
dd if=/dev/zero bs=2048 count=500000 of=/root/1Gb.file
dd if=/dev/zero bs=4096 count=250000 of=/root/1Gb.file
dd if=/dev/zero bs=8192 count=125000 of=/root/1Gb.file
复制代码
2.3 dd命令拷贝磁盘
dd if=/dev/sda of=/dev/sdb bs=4096
复制代码
2.4 创建磁盘的镜像文件
# 创建一个名为image.iso的CDROM镜像文件
dd if=/dev/cdrom of=image.iso
复制代码
2.5 构造数据:指定大小、指定个数、指定位置、指定并发数
# seq 20表明生成1-20序列
# xargs -I{} 表示用1-20各个序列替换后面的1G_{}.txt中的{},即实现输出1G_1.txt、1G_2.txt...
# -P 20 表示并发数,即:同一时刻最多有20个dd进程并发
# -n 1 每执行一次就会消耗一个seq 20传入的参数,每次取结果中的一个数字
# if=/dev/zero 数据输入来源/dev/zero(全是0),dev/zero为输入设置,它可无穷无尽提供0
# bs(block size)=1G:指定dd中的块大小为1G
# count=1指定块数量为1 块大小bs*块数量count=最终的文件大小(1G*1=1G,我这里是生成1G文件)
# 2>&1: 将dd命令的错误输出(标准错误流stderr)重定向到与标准输出相同的文件,这样正常输出和错误信息都会被记录到同一个日志文件中
seq 20 | xargs -I{} -P 20 -n 1 bash -c 'dd if=/dev/zero of=/root/test/1G_{}.txt bs=1G count=1 > dd_{}.log 2>&1'
复制代码
上面命令表示:
天生1-20个1G文件
并发数为20
天生文件路径为/root/test目次
将dd的日志输出到当前执行目次下
3 实战:测试文件读写
最近接到一个需求,客户必要我们将S3对象桶挂载为文件体系,同时实现POSIX语义。
为了验证方案可行性,必要测试挂载后的读写性能。
3.1 dd构造数据
# seq 20表明生成1-20序列
# xargs -I{} 表示用1-20各个序列替换后面的1G_{}.txt中的{},即实现输出1G_1.txt、1G_2.txt...
# -P 20 表示并发数,即:同一时刻最多有20个dd进程并发
# -n 1 每执行一次就会消耗一个seq 20传入的参数,每次取结果中的一个数字
# if=/dev/zero 数据输入来源/dev/zero(全是0),dev/zero为输入设置,它可无穷无尽提供0
# bs(block size)=1G:指定dd中的块大小为1G
# count=1指定块数量为1 块大小bs*块数量count=最终的文件大小(1G*1=1G,我这里是生成1G文件)
# 2>&1: 将dd命令的错误输出(标准错误流stderr)重定向到与标准输出相同的文件,这样正常输出和错误信息都会被记录到同一个日志文件中
seq 20 | xargs -I{} -P 20 -n 1 bash -c 'dd if=/dev/zero of=/root/test/1G_{}.txt bs=1G count=1 > dd_{}.log 2>&1'
复制代码
上面命令表示:
天生1-20个1G文件
并发数为20
天生文件路径为/root/test目次
将dd的日志输出到当前执行目次下
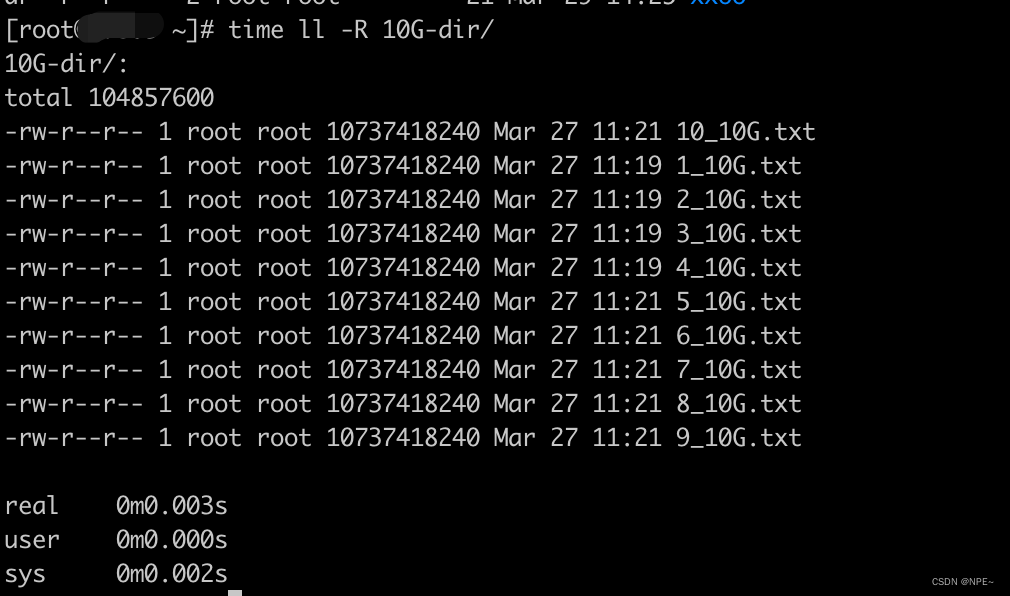
3.2 time ll -R:测试list速度
# ll测试读取目录,time用于获取命令执行所耗时间
time ll -R 10G-dir
复制代码
3.2 time mv xxx xxxx-new:测试rename速度
# 挂载为S3后,修改对象key即为rename操作
time mv test-dir test-dir-new
复制代码
3.3 watch -n 2 ls -l -h /root/bucket01:观察写入文件变革
# 观察挂载目录写入情况
# watch -n 2 每隔2s输出后面命令执行结果,ctrl+C退出持续查看
watch -n 2 ls -l -h /root/bucket01
复制代码
3.4 dstat -n :查看网络带宽
# 查看当前客户端网络带宽
dstat -n
复制代码
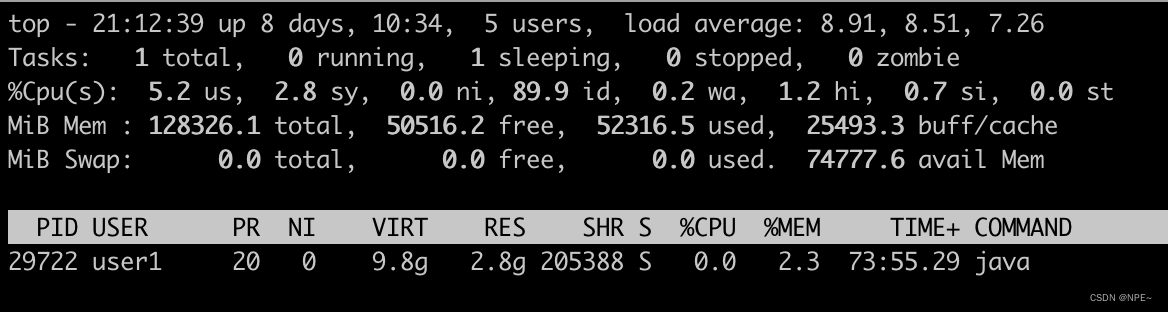
3.5 top -p pid:查看程序所耗资源
# 获取程序pid
ps -ef | grep xxx
# 根据pid过滤进程所耗资源
top -p xxx
# %CPU:CPU使用情况
# %MEM:内存使用情况
复制代码
3.6 安装ab(http压测)工具
因为必要测试日志滚动,所以必要手动构造大量哀求。这里采用ab(Apache bench)工具。
# 安装ab工具(Apache bench)
yum install httpd-tools
# -n 1000 总共请求1000次
# -c 10 开启10个并发请求
ab -n 1000 -c 10 http://127.0.0.1:80/
复制代码
3.7 通过vdbench造数据
rw_fs配置文件:
threads=128:128并发写数据
depth=1,width=100,files=10000:目次深度为1、目次宽度为100(一个目次下有100个子目次)、每个子目次下有10000个文件
size=4k:每个文件大小为4k
elapsed=3000:取样时间
data_errors=1,messagescan=no,create_anchors=yes,debug=25
fsd=fsd1,anchor=/root/bucket01/4k-100w-parallel,depth=1,width=100,files=10000,size=4k,openflags=o_direct
fwd=fwd1,operation=write,fsd=fsd1,xfersize=4k,fileio=sequential,fileselect=sequential,threads=128
rd=rd1,fwd=fwd*,fwdrate=max,format=restart,elapsed=3000,interval=1
复制代码
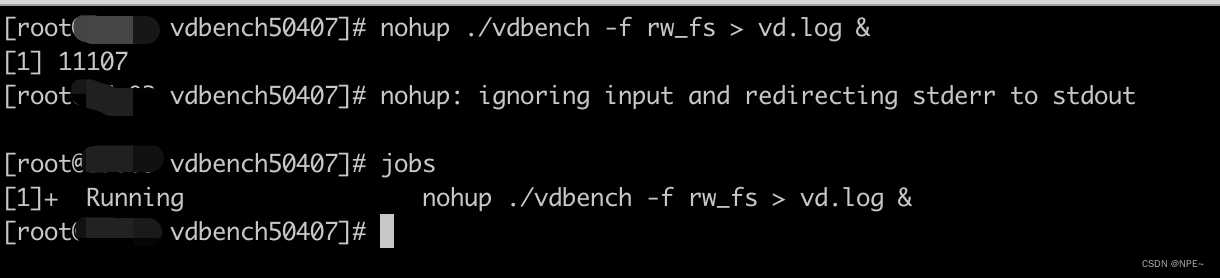
后台运行vdbench:
nohup ./vdbench -f rw_fs > vd.log &
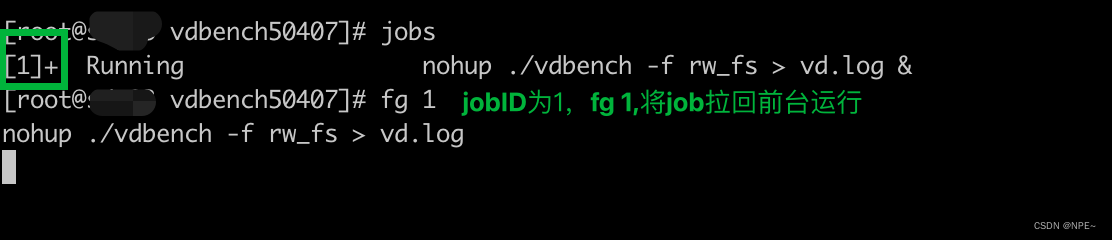
# 检查后台jobID
jobs
# 将后台进程拉回到前台
fg jobID
复制代码
3.8 echo $?:查看后台运行job是否有异常发生
# 返回上一个命令的状态,0表示没有错误,其它任何值表明有错误
echo $?
#echo $! 返回后台运行的最后一个进程的进程ID号
复制代码
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/)
Powered by Discuz! X3.4