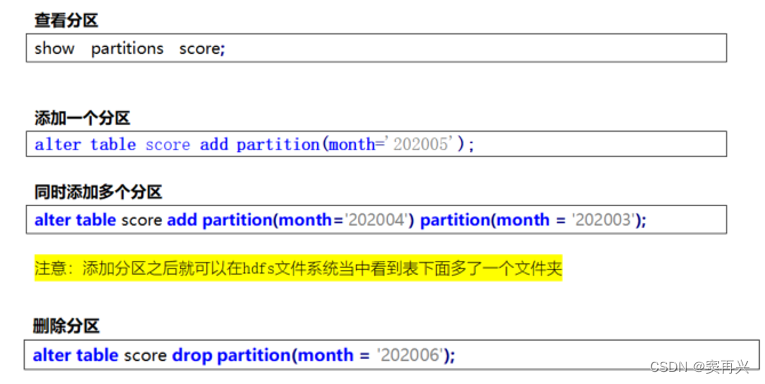
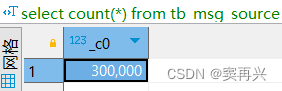
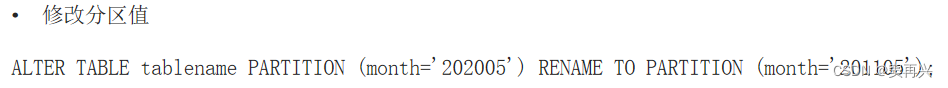在 Navicat 中打开 Hive 数据库,然后执行下面的 SQL
-- 在Hive的MySQL元数据库中执行
use hive;
-- 修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
-- 修改表注释字符集
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
-- 修改分区表参数,以支持分区键能够用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
-- 修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
Hive 根本使用
起首需要启动 Metastore 服务
在前台启动 Hive 后,可以创建表,很像 SQL
create table test(
id int,
name string,
gender string
);
这里的数据类型和 MySQL 的关键字不同,但是寄义是一样的
插入数据
insert into test values(1,'lyj','male');
你会发现插入速率很慢,还会打印很多日志
hive> insert into test values(1,'lyj','male');
Query ID = hadoop_20240412171222_01bc3760-4c15-40d2-b73d-a6b09c6aedc0
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1712909011549_0001, Tracking URL = http://node1:8089/proxy/application_1712909011549_0001/
Kill Command = /export/server/hadoop/bin/mapred job -kill job_1712909011549_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2024-04-12 17:13:31,441 Stage-1 map = 0%, reduce = 0%
2024-04-12 17:14:03,733 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.89 sec
2024-04-12 17:14:15,768 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.09 sec
MapReduce Total cumulative CPU time: 6 seconds 90 msec
Ended Job = job_1712909011549_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://node1:8020/user/hive/warehouse/test/.hive-staging_hive_2024-04-12_17-12-22_145_7390953200422943167-1/-ext-10000
Loading data to table default.test
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.09 sec HDFS Read: 16364 HDFS Write: 276 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 90 msec
OK
Time taken: 117.948 seconds
慢是由于现实执行的是 MapReduce,http://node1:8088/,来访问这个,也能看到 Yarn 中的使命
内转外
alter table 表名 set tblproperties('EXTERNAL'='TRUE'); -- 留意单词不要写错,必须大写
外转内
alter table 表名 set tblproperties('EXTERNAL'='FALSE');
数据导入
将文件数据导入表中
load data [local] inpath '文件路径' [overwrite] into table 表名;
local:数据是否在当地,在 Linux 上需要使用 file://路径;假如在 HDFS 可以不消写 local
overwrite:是否覆盖旧数据,不覆盖就是追加
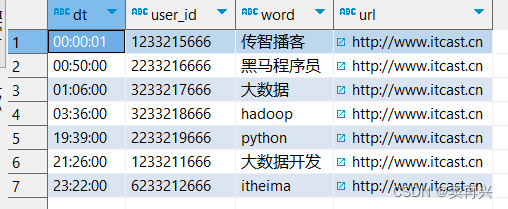
测试表结构
CREATE TABLE myhive.test_load(
dt string comment '时间(时分秒)',
user_id string comment '用户ID',
word string comment '搜索词',
url string comment '用户访问网址'
) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
从 Linux 中加载数据到表中
把资料中的 search_log.txt 上传到 /home/hadoop(Linux 路径),执行
load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load;
可以看到数据正确加载了,由于资料中数据的结构和表结构完全对应
从 HDFS 中加载数据
起首把表删除了,然后通过 web 将刚才的文件上传到 HDFS 的 /tmp 目录下,执行
load data inpath '/tmp/search_log.txt' overwrite into table myhive.test_load;
数据也可以正常加载,不过在 HDFS 的 /tmp/search_log.txt 文件消失了,而是转移到了 /user/hive/warehouse/myhive.db/test_load 目录下
从其他表中导入数据
这种方式速率就慢很多,由于走 MapReduce
当数据量大的时候,load 和 这个方式差不多
再创建一个表,结构一样,名字不同
CREATE TABLE myhive.test_load2(
dt string comment '时间(时分秒)',
user_id string comment '用户ID',
word string comment '搜索词',
url string comment '用户访问网址'
) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
将查询出来的数据,插入到前面的表中 可以指定条件
追加
insert into table tbl1 select * from tbl2;
覆盖
insert overwrite table tbl1 select * from tbl2;
数据导出
有 local 就是导出到 Linux,没有就是导出到 HDFS
还是使用 MapReduce
使用 SQL
将查询结果导出到 Linux,使用默认的分隔符
insert overwrite local directory '/home/hadoop/export1'
select * from test_load ;
将查询的结果导出到当地 - 指定分隔符
insert overwrite local directory '/home/hadoop/export2'
row format delimited fields terminated by '\t'
select * from test_load;
将查询的结果导出到 HDFS 上 (不带 local 关键字)
insert overwrite directory '/tmp/export'
row format delimited fields terminated by '\t'
select * from test_load;
使用 Hive Shell
这样导出快很多
/export/server/hive/bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txt
create table tablename(...)
partitioned by (分区列 列类型, ......)
row format delimited fields terminated by '';
单层级分区
-- 按照月份进行分区
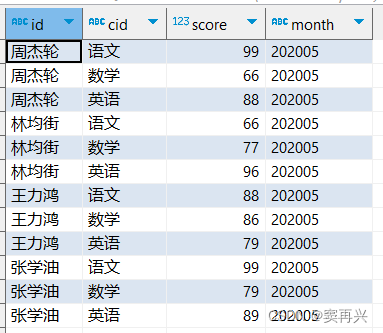
create table score(
id string,
cid string,
score int
) partitioned by (month string)
row format delimited fields terminated by '\t';
加载数据,但是数据中没有月份这个列,表中也没有
load data local inpath '/home/hadoop/score.txt'
into table score
partition(month='202005');
但是数据加载完毕后,会多出一列,在 HDFS 中以分区 month=202005 作为文件夹名称
多层级分区
create table score222(
id string,
cid string,
score int
) partitioned by (year string,month string,day string)
row format delimited fields terminated by '\t';
指定三个分区,那么在加载数据也需要指定三个,不能只有 year
load data local inpath '/home/hadoop/score.txt'
into table score222
partition(year='2024',month='04',day='13');
目录结构:/user/hive/warehouse/myhive.db/score222/year=2024/month=04/day=13
LOAD DATA LOCAL INPATH '/home/hadoop/itheima_users.txt' INTO TABLE itheima.users;
根本查询
根本条件查询和 SQL 一样,但是多了一些其他的
cluster by
distribute by
sort by
这种简单的查询出结果很快
这种用聚合函数的,就会走 MapReduce,很慢
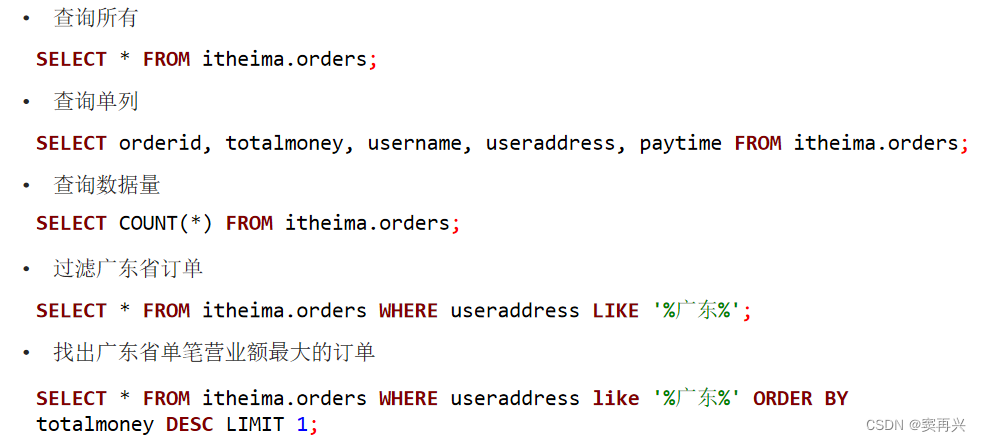
JOIN 订单表和用户表,找出用户名
SELECT o.orderid, o.userid, u.username, o.totalmoney, o.useraddress, o.paytime
FROM itheima.orders o JOIN
itheima.users u
ON o.userid = u.userid;
左外关联,订单表和用户表,找出用户名
SELECT o.orderid, o.userid, u.username, o.totalmoney, o.useraddress, o.paytime
FROM itheima.orders o LEFT JOIN
itheima.users u
ON o.userid = u.userid;
可以发现和 SQL 没有区别
RLIKE-正则表达式
正则表达式能匹配的字符和规则更多,功能更加强大
多个正则作为条件
-- 查询地点是广东,并且姓张的订单信息
SELECT *
FROM itheima.orders
WHERE useraddress RLIKE '.*广东.*'
AND username RLIKE '^张.*';
UNION-团结
就是和 SQL 的 UNION 一样,将两个查询结果合并为一张表(所以查询结果的结果需要一致)
默认去重,假如不想去重,就使用 UNION ALL
SELECT * FROM course WHERE t_id = '周杰轮'
UNION
SELECT * FROM course WHERE t_id = '王力鸿'
这样得到的结果可以作为暂时表,用来作为查询表、导入导出数据的表等
给列起别名不能用中文,但是表和列的注释可以
-- 假如创建表的数据是从查询结果得到的,需要有 as
create table xxx as
select ……
假如发现表的注释是乱码,在上面有解决方法,我做了之后是能够解决乱码问题
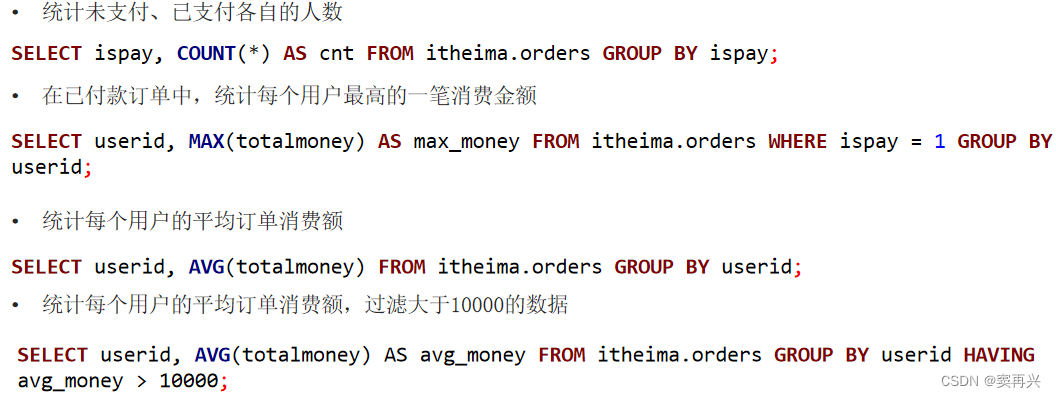
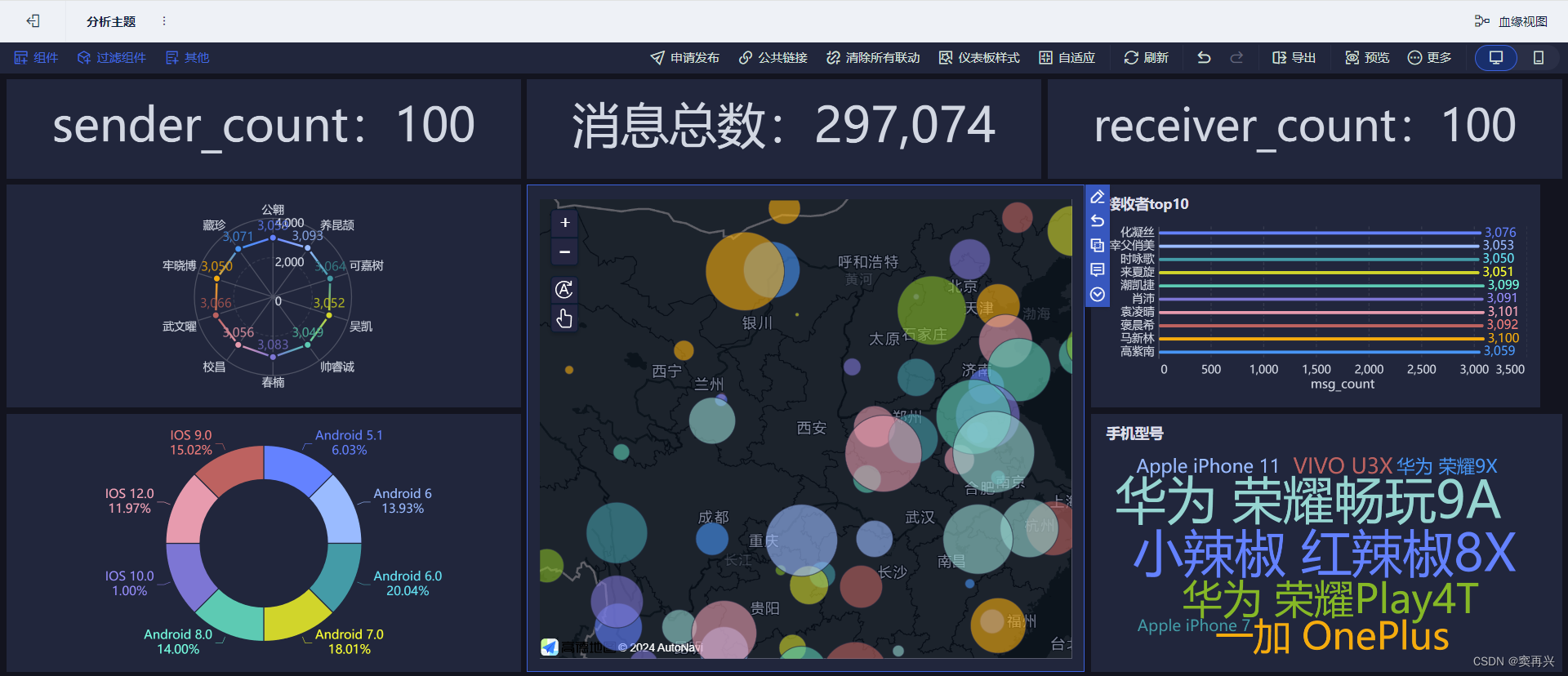
统计每天的总消息量
每天,所以需要把天这个字段查询出来;
消息量,需要用 count,由于是每天,所以用天数来分组,group by msg_day
CREATE table tb_everyday_msg_count
COMMENT "逐日消息总量" as
select msg_day ,
count(*) total_msg_count
from tb_msg_etl
group by msg_day ;
统计今日每小时消息量、发送和吸收用户数
显然要把小时查询出来,发送吸收用户数需要用 count,在 count 中写表达式去重;最后根据 hour 分组
create table tb_per_hour_sender_receiver_count as
select
msg_hour,
COUNT(*) msg_count ,
count(DISTINCT sender_name) sender_count,
count(DISTINCT receiver_name) receiver_count
from tb_msg_etl
group by msg_hour;
统计今日各地区发送消息数据量
这里是用经纬度来代替省份城市,那经纬度肯定要查出来,还有 count(*) msg_count 和天数,分组这里要根据三个字段来分组
create table tb_per_zone_msg_count
comment "今日各地区发送消息数据量" as
select
msg_day,
sender_lng,
sender_lat,
count(*) msg_count
from tb_msg_etl
group by msg_day, sender_lng, sender_lat;
统计今日发送消息和吸收消息的用户数
查询出天数,发送者和吸收者的数量,并去重,最后根据天数来分组
create table tb_today_sender_receiver_count as
select
msg_day,
count(DISTINCT sender_name) sender_count,
count(DISTINCT receiver_name) receiver_count
from tb_msg_etl
group by msg_day;
统计今日发送消息最多的 Top10 用户
查询出天数,发送者和消息的数量,根据天数和发送者名字分组,之后倒序排序消息数量,取 10 条数据
由于倒序了,所以前 10 条数据就是发送消息最多的用户
create table tb_send_msg_count_user_top10 as
select
msg_day,
sender_name,
count(*) msg_count
from tb_msg_etl
group by msg_day, sender_name
order by msg_count DESC
limit 10;
统计今日吸收消息最多的Top10用户
和上面类似,今天,吸收消息用户,最多
所以需要查询的字段肯定有 msg_day,receiver_name
由于要统计吸收消息数,所以肯定需要 count(*) msg_count,那这个统计谁的数量?这个来看表,每条消息都有吸收者的名字,所以这个统计的是吸收者的名字的数量
create table tb_receive_msg_count_top10 as
select
msg_day,
receiver_name,
count(*) msg_count
from tb_msg_etl
group by msg_day,receiver_name
order by msg_count DESC
limit 10;
统计发送人的手机型号分布环境
应该是统计每种手机的占比,推荐乘上 100,这样百分比悦目一些
字段:sender_phonetypecount(*)/3000 type_percent
create table tb_sender_phone_type_percent as
select
sender_phonetype,
count(*)/3000 type_percent
from tb_msg_etl
group by sender_phonetype;
统计发送人的装备操作系统分布环境
同上,统计每种操作系统的占比
字段:sender_oscount(*)/3000 type_percent
create table tb_sender_os_percent as
select
sender_os,
count(*)/3000 type_percent
from tb_msg_etl
group by sender_os