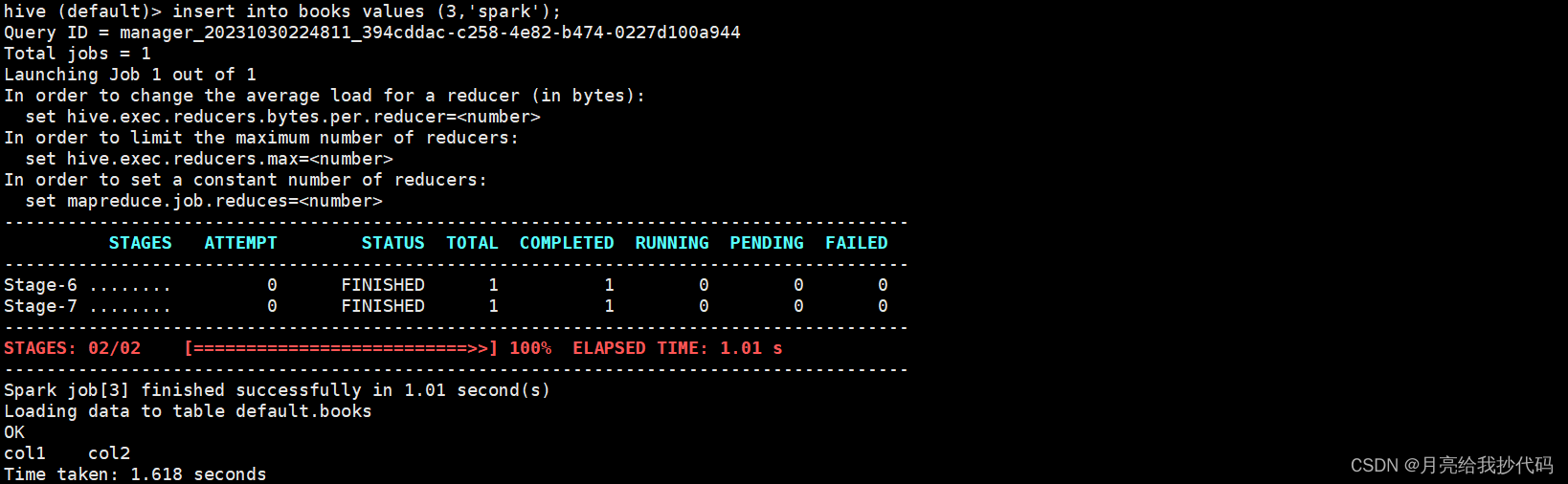
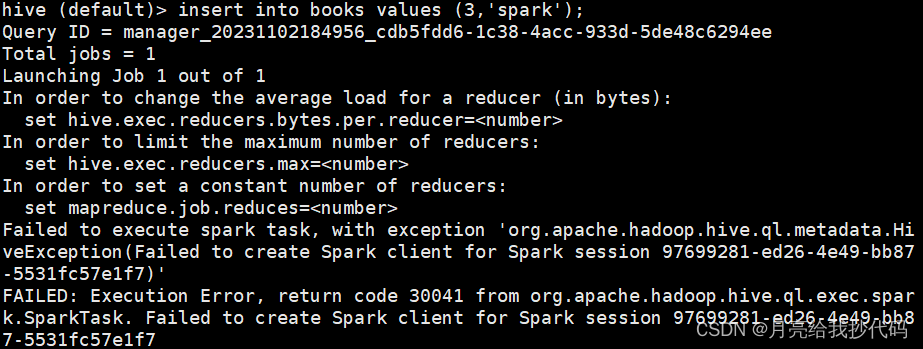
当我们在 Hive On Spark 模式下同时启用多个 Hive 客户端举行操作时,会发现,后启动的多个 Hive 执行任务时(大概)会卡住,如下所示:
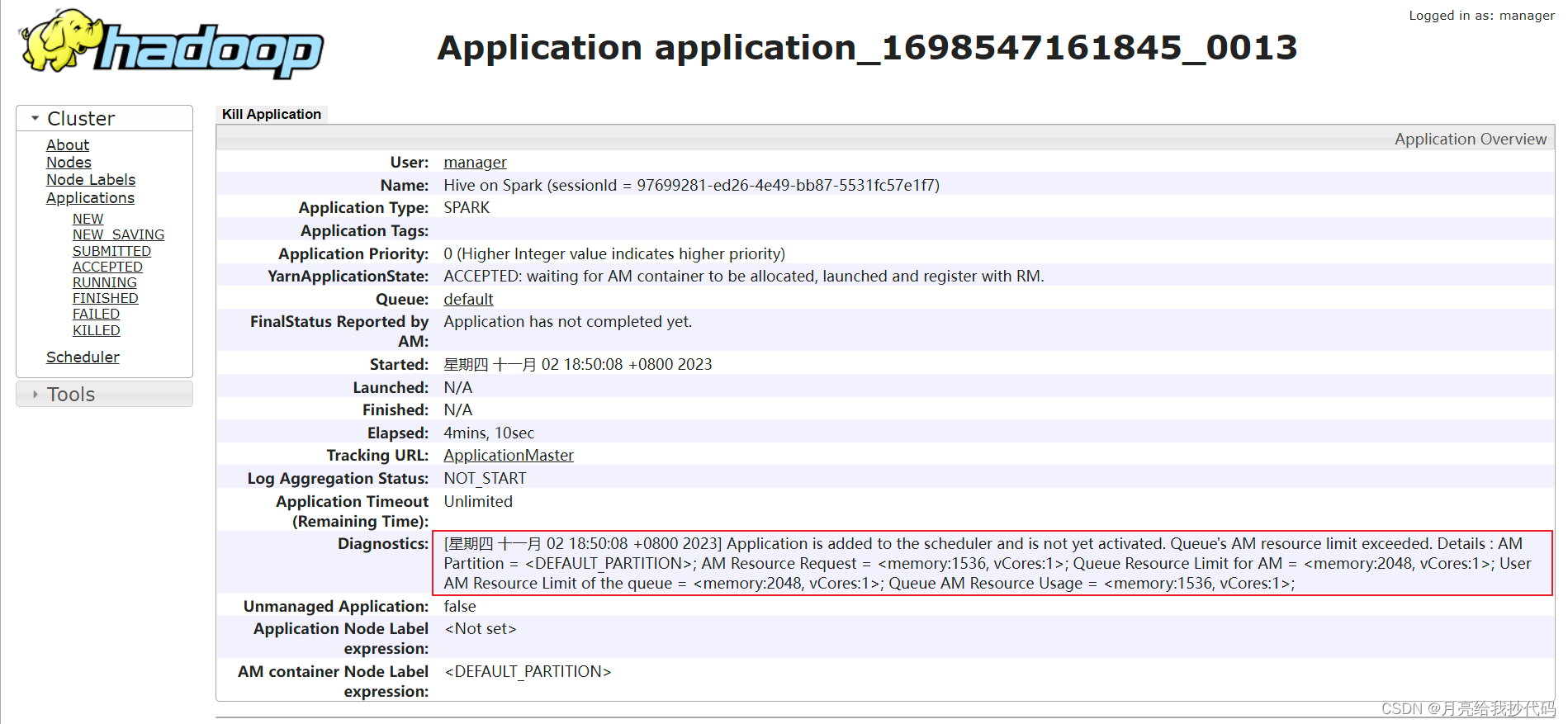
进入历史服务器,查察该任务的执行详情,会发现如下提示:
提示任务已经添加但是未激活,缘故原由是 AM 资源溢出。
Yarn 默认使用的是容量调理器 Capacity Scheduler(队列),该队列的总容量默认为 Yarn 总资源的 %10(1024的倍数),当前我的 Yarn 集群环境分配的总资源为 18G,所以这里队列的最大容量为 2048MB,也就是 2G。
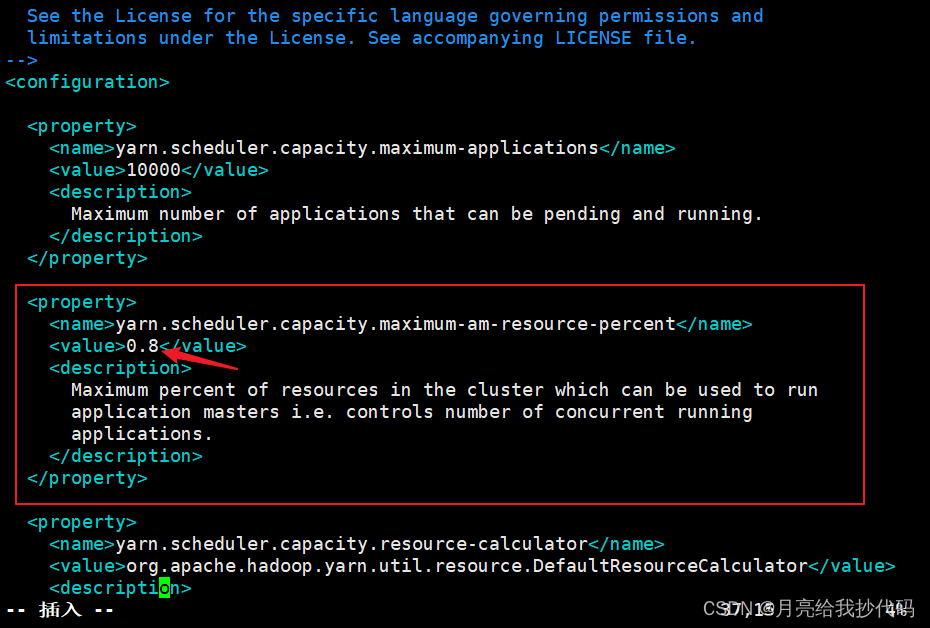
我启动第一个 Hive 客户端运行步伐后,Yarn 成功的为其分配了 AM 资源,当我又启动了其它的 Hive 客户端运行步伐时,就会导致 AM 资源分配失败,因为两个 AM 的总资源相加已经达 3G 左右,所以会导致任务卡顿或失败。 办理方法:进步 Yarn 为队列分配的总资源,修改 Hadoop 配置文件目录下的 capacity-scheduler.xml 文件,调解资源分配比例,默认为 0.1,对学习环境不太友爱,建议调解为 0.8。
cd $HADOOP_HOME/etc/hadoop
vim capacity-scheduler.xml
复制代码
修改完成后,留意将该文件同步到集群中的其它呆板,然后重启 Yarn 即可。
办理依赖辩论题目
当我们在使用 Hive On Spark 时,大概会发生如下依赖辩论题目:
Job failed with java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.<init>()V from class org.apache.hadoop.mapreduce.lib.input.FileInputFormat
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:262)
at org.apache.hadoop.hive.shims.Hadoop23Shims$1.listStatus(Hadoop23Shims.java:134)
at org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:217)
at org.apache.hadoop.mapred.lib.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:75)
at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileInputFormatShim.getSplits(HadoopShimsSecure.java:321)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getCombineSplits(CombineHiveInputFormat.java:444)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getSplits(CombineHiveInputFormat.java:564)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:200)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:253)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:251)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:251)
at org.apache.spark.rdd.RDD.getNumPartitions(RDD.scala:267)
at org.apache.spark.api.java.JavaRDDLike$class.getNumPartitions(JavaRDDLike.scala:65)
at org.apache.spark.api.java.AbstractJavaRDDLike.getNumPartitions(JavaRDDLike.scala:45)
at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generateMapInput(SparkPlanGenerator.java:215)
at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generateParentTran(SparkPlanGenerator.java:142)
at org.apache.hadoop.hive.ql.exec.spark.SparkPlanGenerator.generate(SparkPlanGenerator.java:114)
at org.apache.hadoop.hive.ql.exec.spark.RemoteHiveSparkClient$JobStatusJob.call(RemoteHiveSparkClient.java:359)
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:378)
at org.apache.hive.spark.client.RemoteDriver$JobWrapper.call(RemoteDriver.java:343)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause.