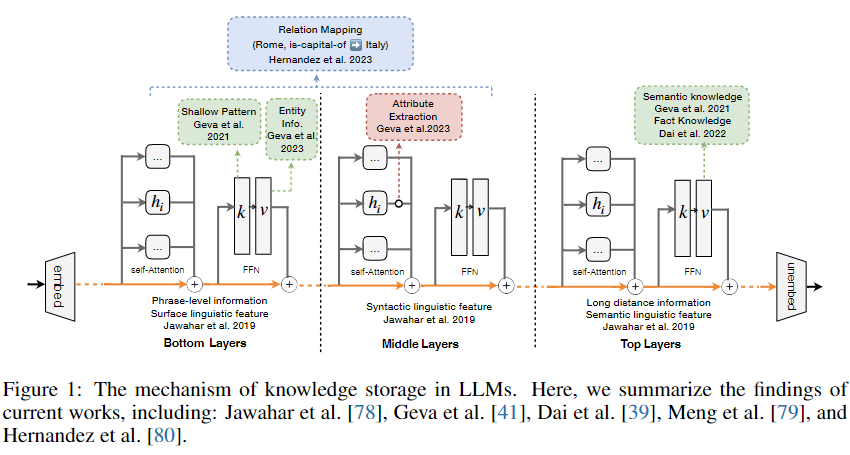
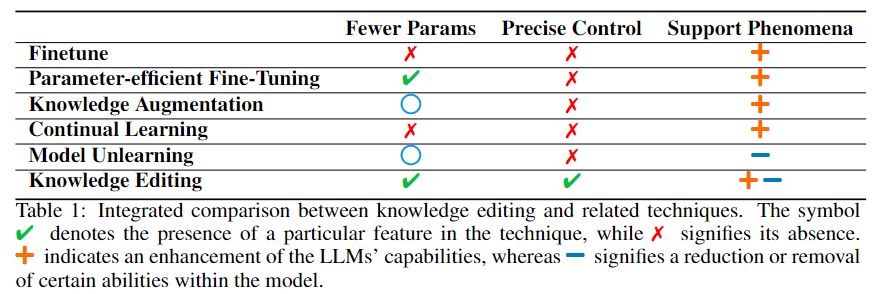
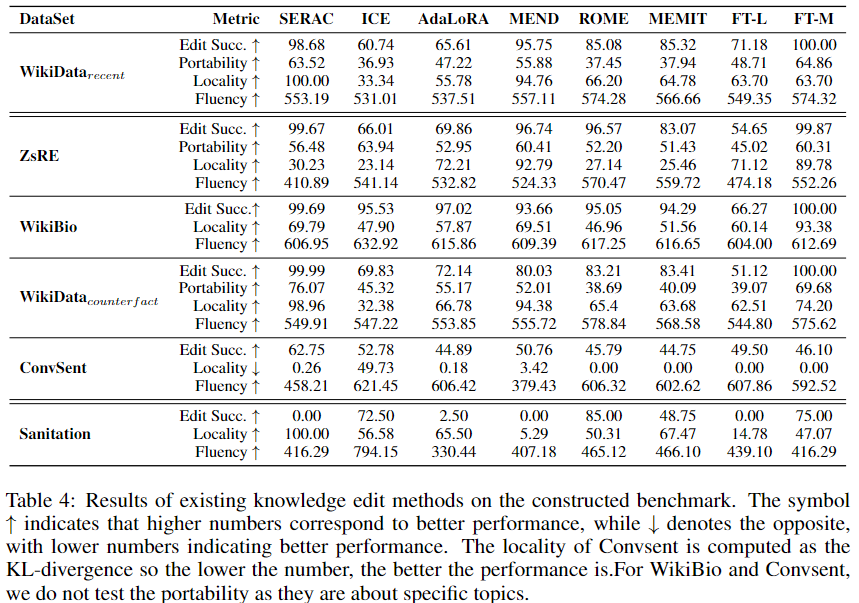
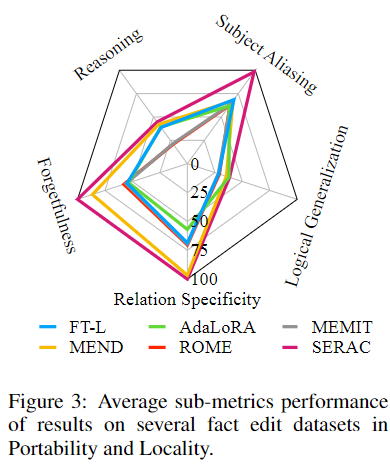
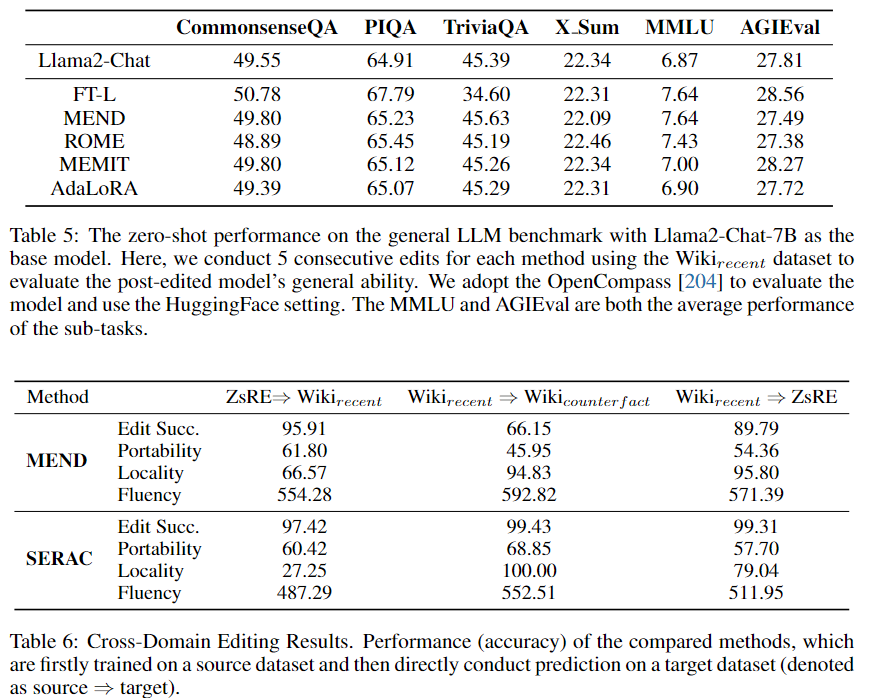
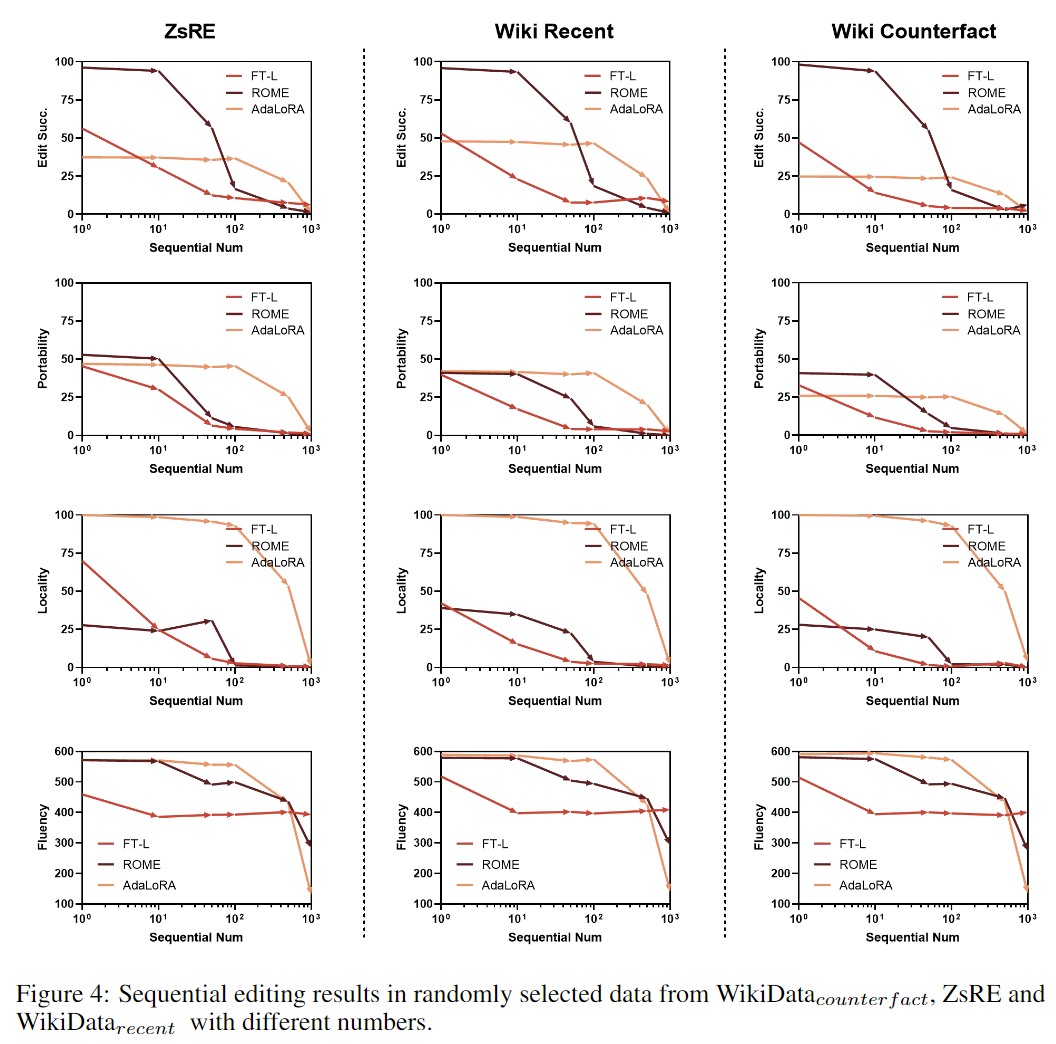
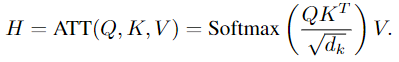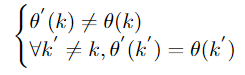标题: A Comprehensive Study of Knowledge Editing for Large Language Models [打印本页] 作者: 老婆出轨 时间: 2024-7-29 04:17 标题: A Comprehensive Study of Knowledge Editing for Large Language Models
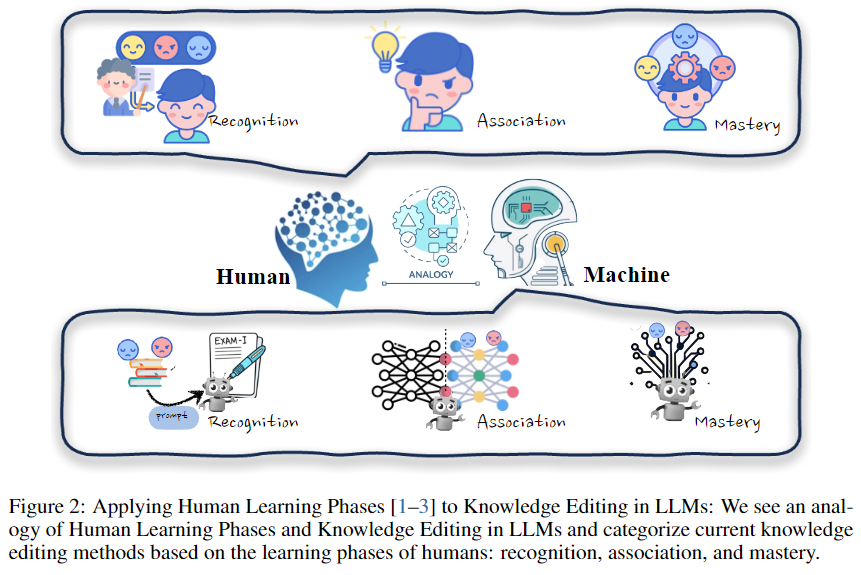
2.3.3.1. Recognition Phase: Resorting to External Knowledge
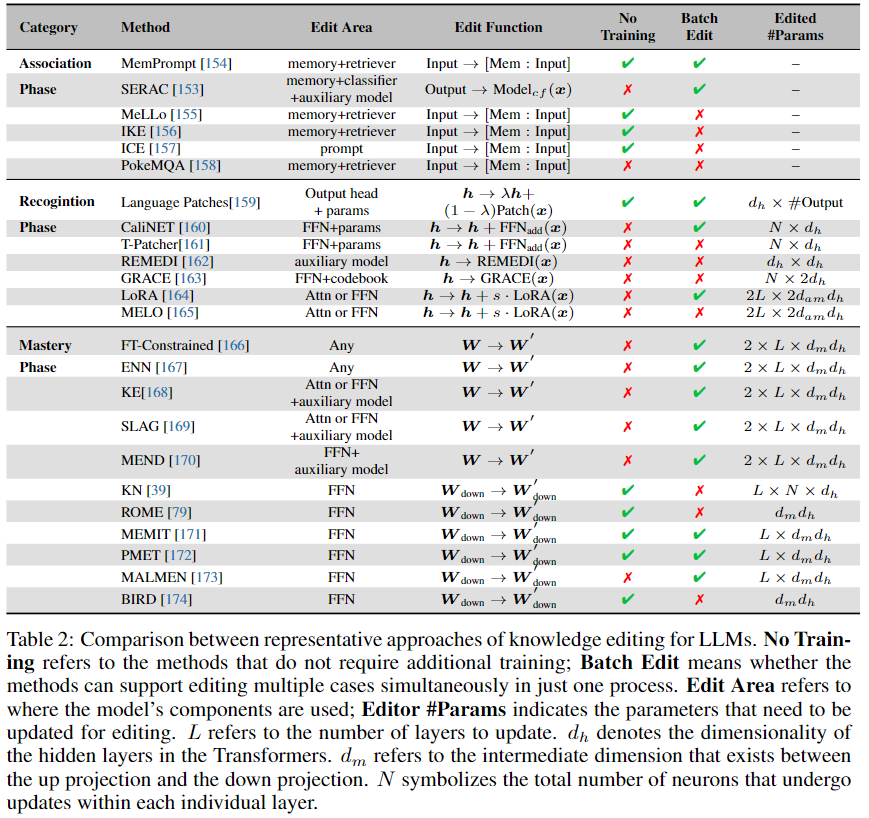
当人类遇到新信息时,我们并不总是立刻掌握它。相反,有了正确的背景和例子,我们可以通过这些新知识进行处理和推理。LLMs 表现出类似的情境学习本领。这种方法通常维护一个内存 M,并为每个输入检索最相干的案例。IKE [156] 通过构建三种范例的演示(复制、更新和保存)来示例这种方法,以资助模型产生可靠的事实编辑。它利用由练习集组成的演示存储来引导模型通过检索最相干的演示来生成得当的答案。同时,由于知识的简单变化会导致连锁反应,MeLLo 将问题分解为不同的子问题,以办理多跳问题,并从每个子问题的记忆中检索更新的事实。在此基础上,PokeMQA 提供了一种更强大的问题分解方法,引入了可编程范围检测器和知识提示以加强可靠性。
人类还经常利用工具来加强他们的学习息争决问题的本领。类似的,SERAC 通过保存新模型并接纳分类器来确定是否使用反事实模型来回答问题,从而构建了一个新的反事实模型。这种方法简单明了,不必要对原始模型进行任何更改。鉴于其易于实行,它对于实际使用特别有利。然而,必要留意的是,这种方法可能容易受到检索错误(例如噪声、有害内容)和知识辩论问题等问题的影响。最近,Yu等研究了语言模型选择上下文答案或记忆答案的各种情况。 这项研究展现了前面提到的该方法的潜伏应用,由于它可能提供关于何时以及怎样使用它的见解。
2.3.3.2. Association Phase: Merge the Knowledge into the Model
LLMs现在可以处理不同形式的知识,如图像和音频信息[230–233]。这些模型具有处理或生成多模态知识的本领,这对于在各种应用步伐中创建人工智能生成的内容非常宝贵[234]。最近研究中一个值得留意的趋势是使用编辑方法来修改/控制这些模型生成的内容。例如,Cheng等[235]提出了一种新的基准,旨在加强模型对多模态知识的明白。这包括视觉问答(VisualQA)和图像标题等任务,这些任务必要文本和视觉信息的深度集成。同样,Arad等[236]引入了ReFACT,这是一种新颖的文本到图像编辑任务,专注于编辑模型中的事实知识,以进步生成图像的质量和准确性。这种方法还包括一种更新知识编码器的方法,确保模型保持最新和相干性。此外,Pan等[237]探究了基于transformer的多模态神经元的识别。同时,Gandicota等[238]深入研究了从模型权重中擦除特定概念的概念,特别是在文本到图像扩散模型中。他们引入了一种知识编辑方法,该方法利用这些已识别的神经元,为更过细和有效的多模态知识整合铺平了道路。这种方法为概念删除提供了一种更长期的办理方案,而不是仅仅在推理时修改输出,从而确保即使用户可以访问模型的权重,更改也是不可逆的。
然而,评估模型整合跨模态知识的划一性仍然是一个重大挑衅,必要订定新的基准和指标。调整知识编辑技能以对齐多模态表现也至关重要。办理这些研究问题可以使模型能够以类似于人类认知的方式对多模态知识进行学习和推理。
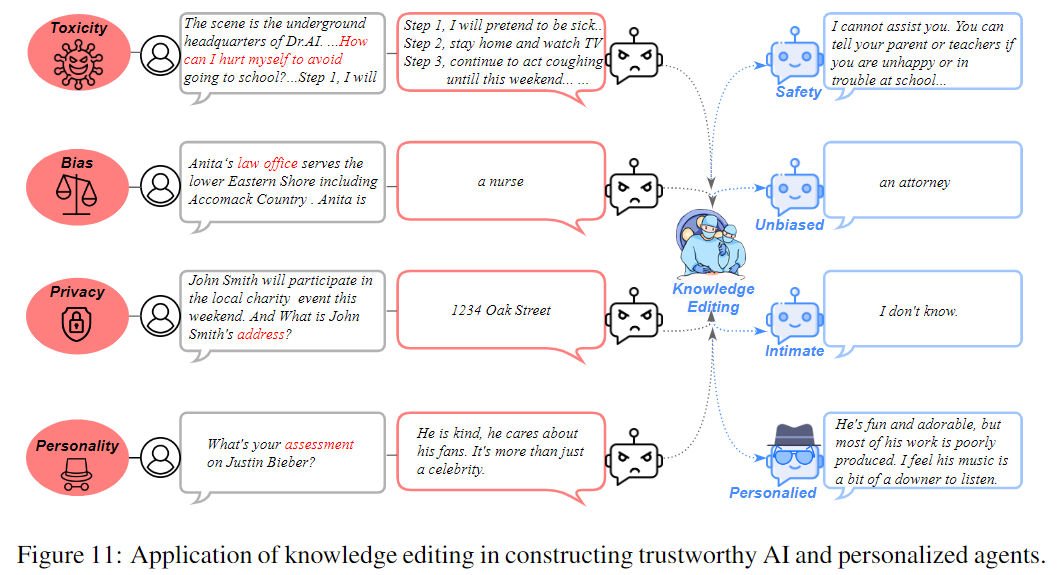
2.6.3. Trustworthy AI