

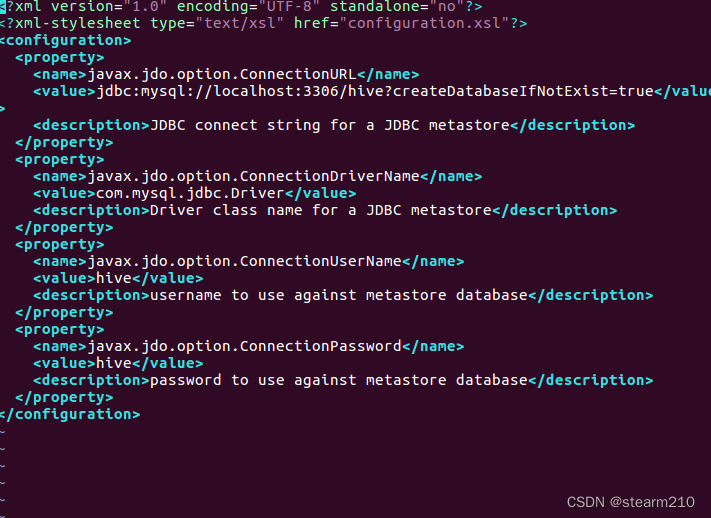


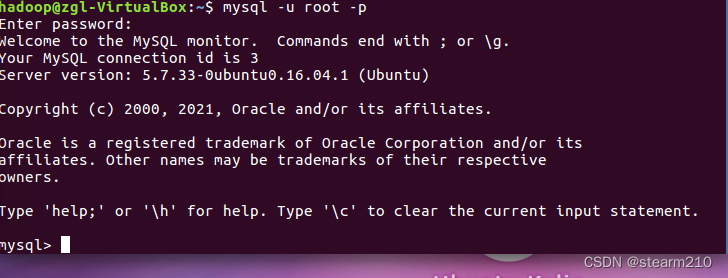
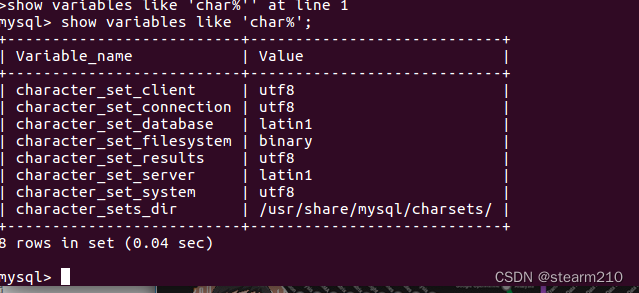

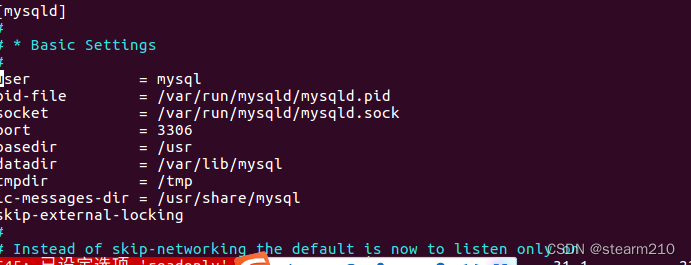
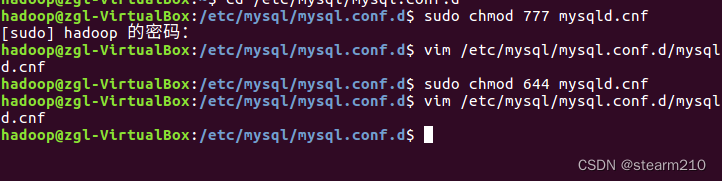
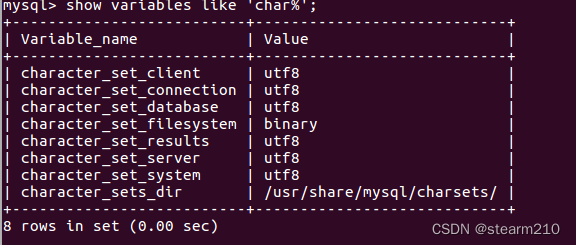

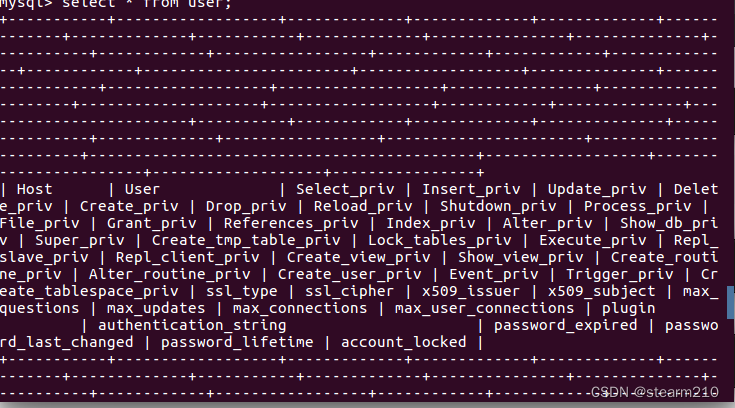
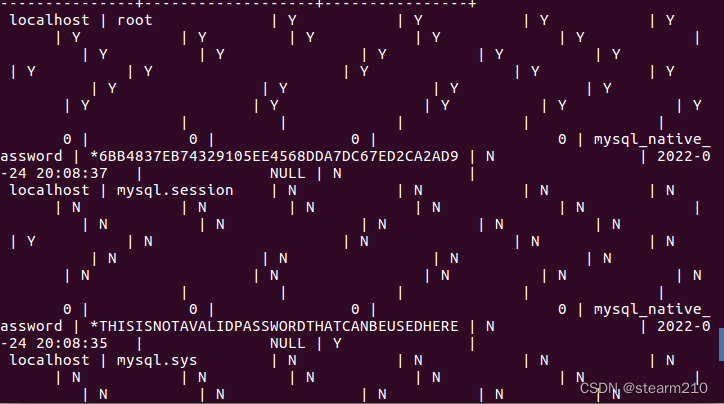
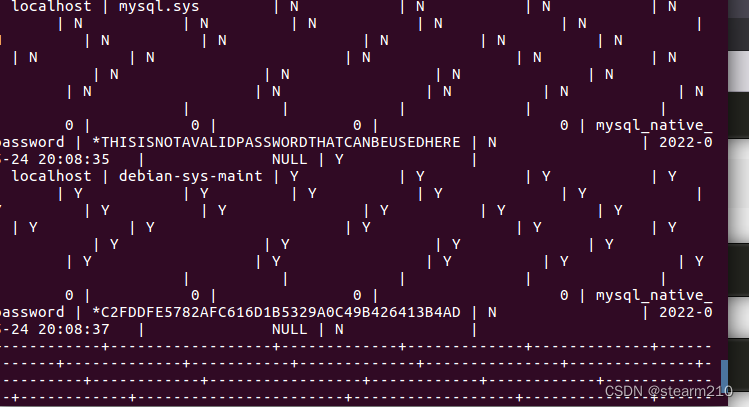
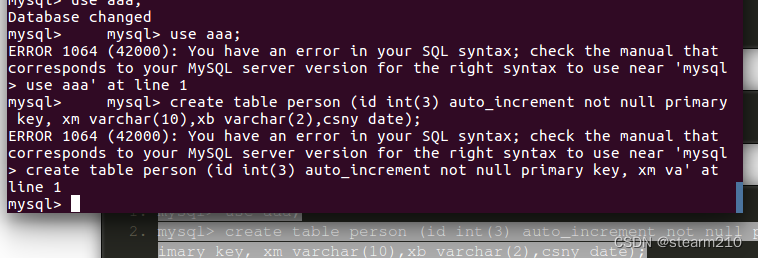






| TINYINT | 1B(8b)有符号整数 | 1 |
| SMALLINT | 2B(16b)有符号整数 | 1 |
| INT | 4B(32b)有符号整数 | 1 |
| BIGINT | 8B(64b)有符号整数 | 1 |
| FLOAT | 4B(32b)单精度浮点数 | 1.0 |
| BOUBLE | 8B(64b)双精度浮点数 | 1.0 |
| STRING | 字符串,可以指定字符串 | “smu” |
| TIMESTAMP | 整数、浮点数大概字符串 | 127383728193 |
| BINARY | 字节数组 | [0,1,0,1,0,1] |
| BOOLEAN | 布尔范例:true/false | true |
| ARRAY | 一组有序字段,字段范例必须相同 | Array(1,2) |
| MAP | 一组无序的键值对,键的范例必须是原子的,值可以是任何数据范例,同一个映射的健和值的范例必须相同 | Map(‘a’,1,2) |
| STRUCT | 一组命名的字段,字段的范例可以不同 | Struct(‘a’,1,1,0) |















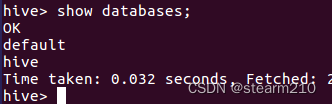
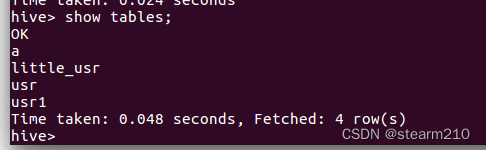


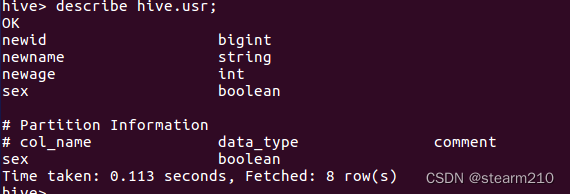

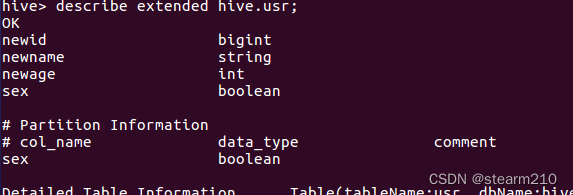

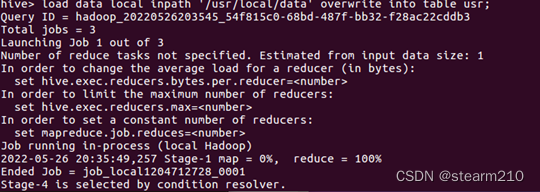
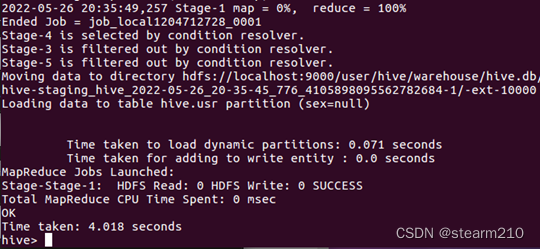
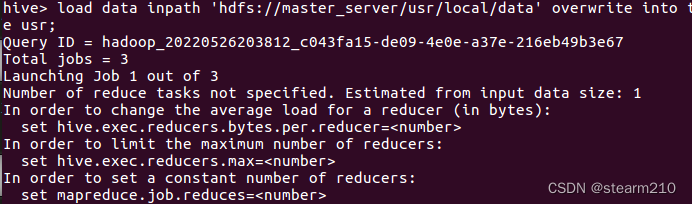
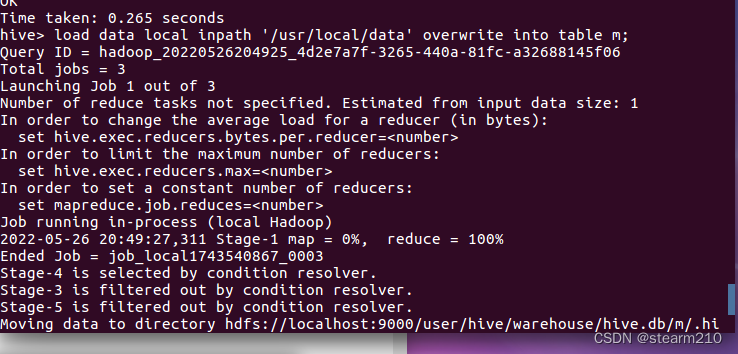
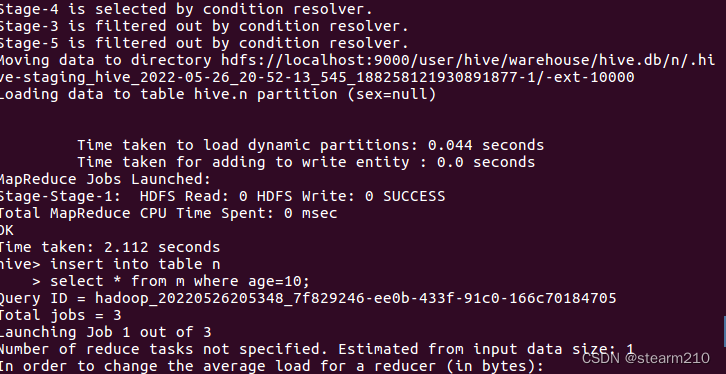
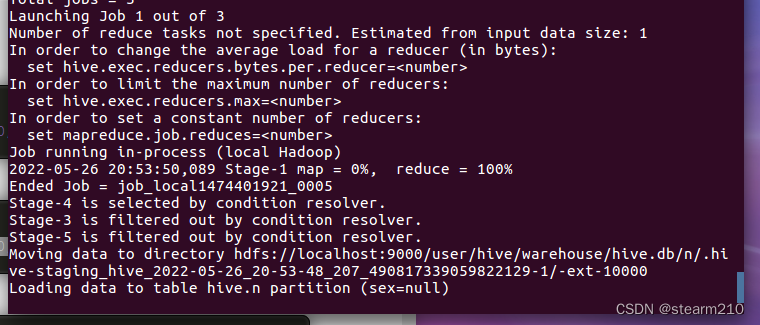

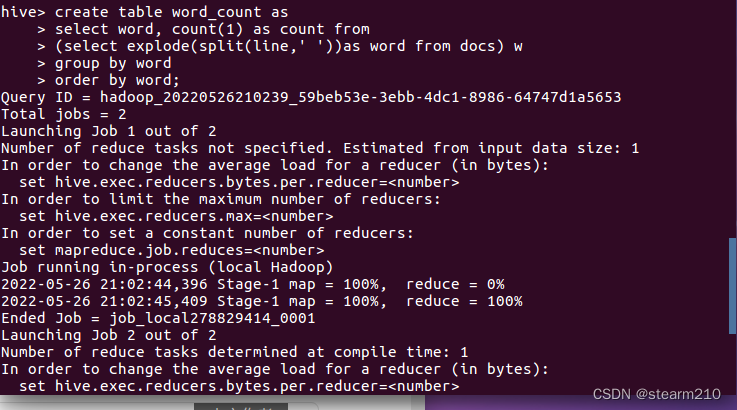
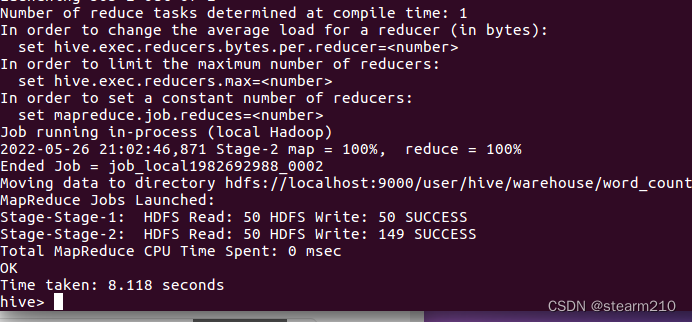




| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |