btn = browser.find_element(By.CSS_SELECTOR, 'body > app-root > app-sign-in-layout > div > div > app-sign-in > app-content-container > div > div > div > form > div > button')
btn.click()
# 可能要验证,睡眠一下手动过验证
time.sleep(10)
# 保存cookie
import json
cookies = browser.get_cookies()
with open('cnblog.json', 'w', encoding='utf-8') as f:
json.dump(cookies, f)
except Exception as e:
print(e)
finally: # 不管报不报错最后都关闭浏览器
# 等待2秒关闭浏览器
time.sleep(2)
browser.quit()
复制代码
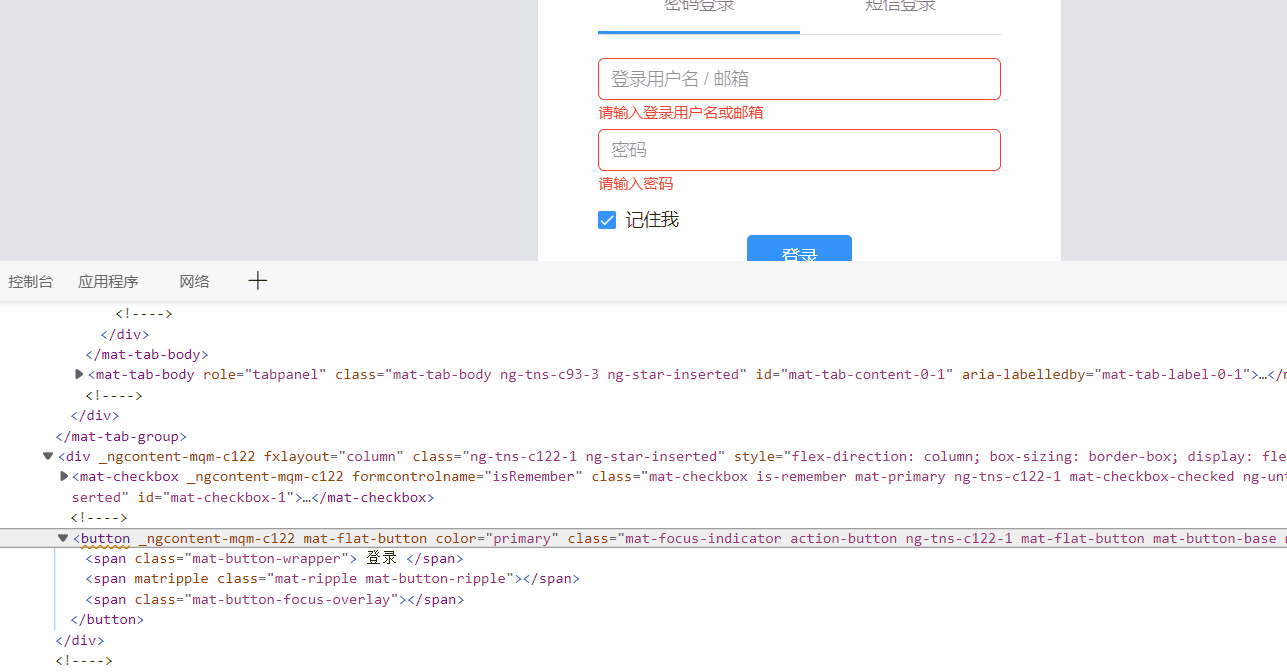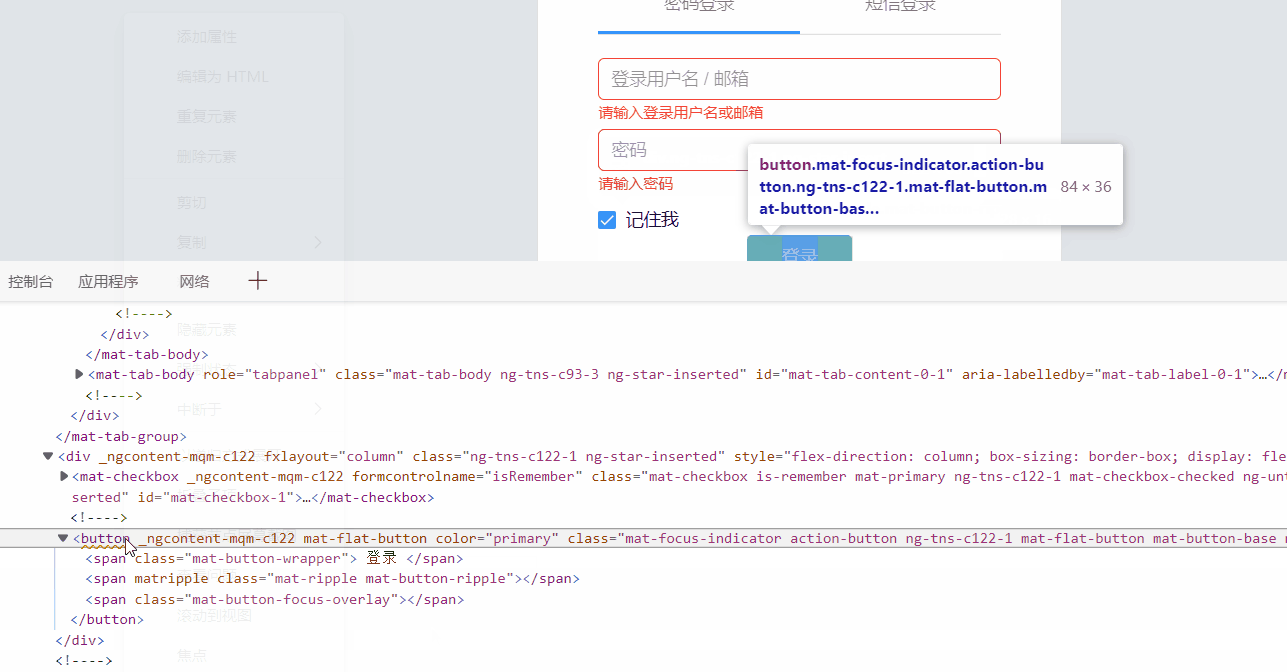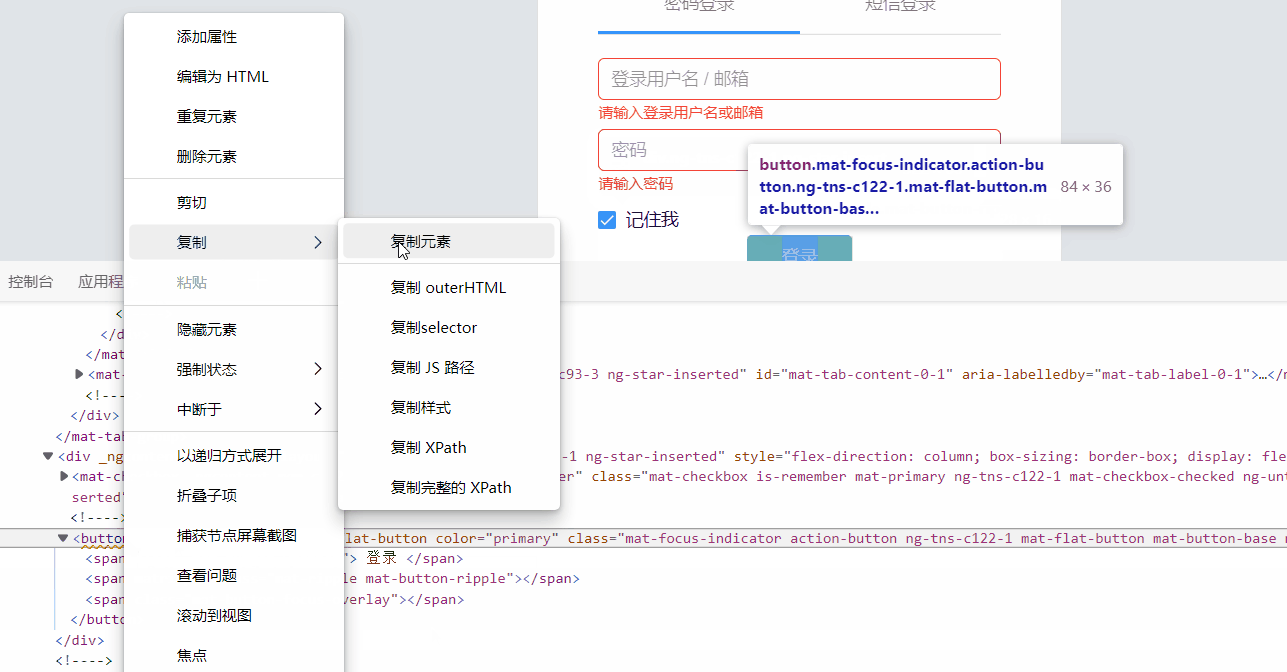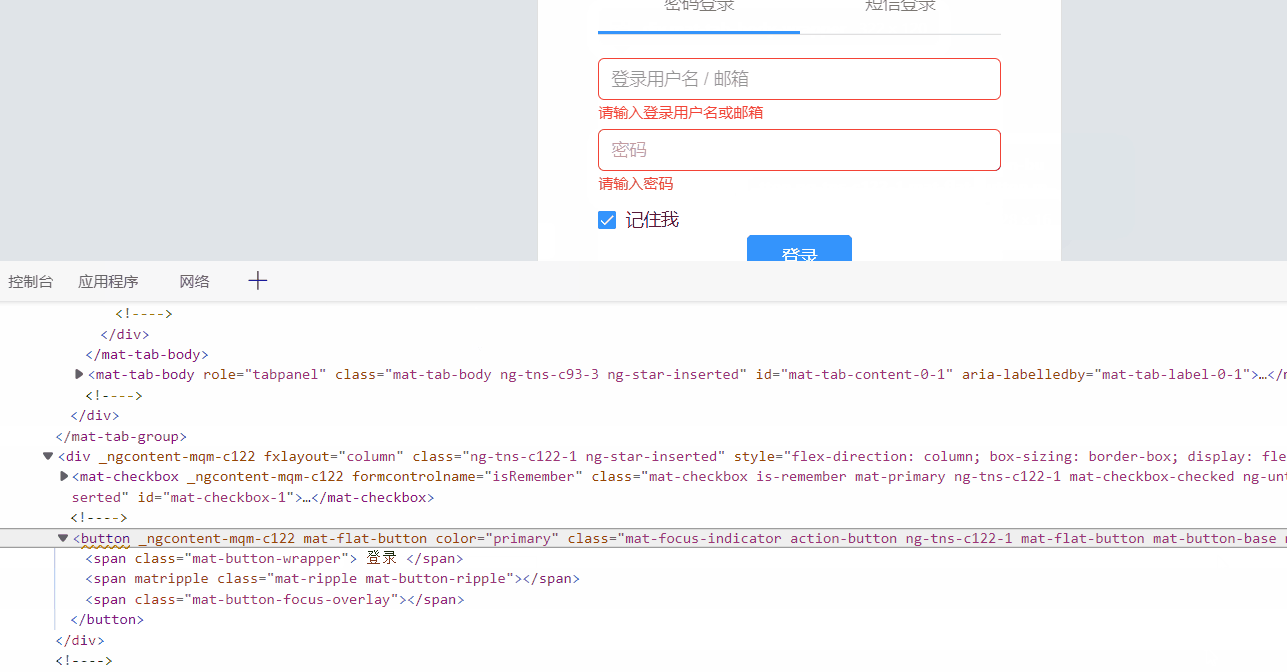
如果标签不好找出来,可以打开F12,找到标签位置,复制css选择器: 通过cookie达成登录效果
from selenium import webdriver
import time
# 打开浏览器
browser = webdriver.Chrome()
browser.implicitly_wait(2)
try:
# 进入博客园
browser.get('https://www.cnblogs.com/')
# 此时还不是登录后的状态
time.sleep(2)
# 拿出cookie
import json
with open('cnblog.json', 'r', encoding='utf-8') as f: