ES 使用的布局是倒排索引,接纳 Lucene倒排索引作为底层,这种布局实用于全文搜索,一个索引由文档中全部不重复的列表构成,对于每一个词,都有一个包罗它的文档列表。
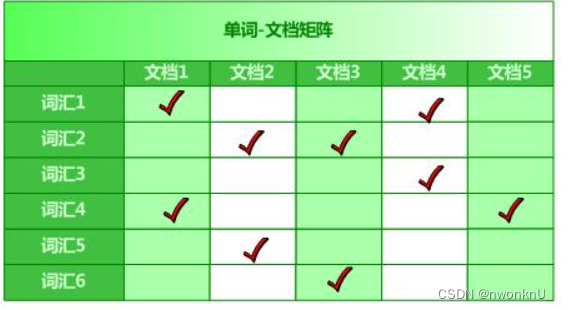
倒排索引是实现“单词-文档矩阵”的一种具体存储情势,通过倒排索引,可以根据单词快速获取包罗这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词-文档矩阵就是一个矩阵,列是文档,行是单词,然后若文档包罗此单词,就进行标记。然后根据指定的单词数组进行匹配,匹配水平越高的代表权重越大,在 ES 中就是 _score。
term 做精确查询可以用它来处理数字,布尔值,日期以及文本。查询数字时问题不大,但是当查询字符串时会有问题。 term 查询的寄义是 termQuery 会去倒排索引中探求确切的 term,但是它并不知道分词器的存在。term 表示查询字段里含有某个关键词的文档,terms表示查询字段里含有多个关键词的文档。
也就是说直接对字段进行 term 本质上还是模糊查询,只不过不会对搜索的输入字符串进行分词处理罢了。如果想通过 term 查到数据,那么 term 查询的字段在索引库中就必须有与 term 查询条件相同的索引词,否则无法查询到结果。
即 elasticsearch 里默认的 IK分词器是会将每一个中文都进行了分词的切割,以是你直接想查一整个词,或者一整句话是无返回结果的。
11.0.1.1、关于 keyword