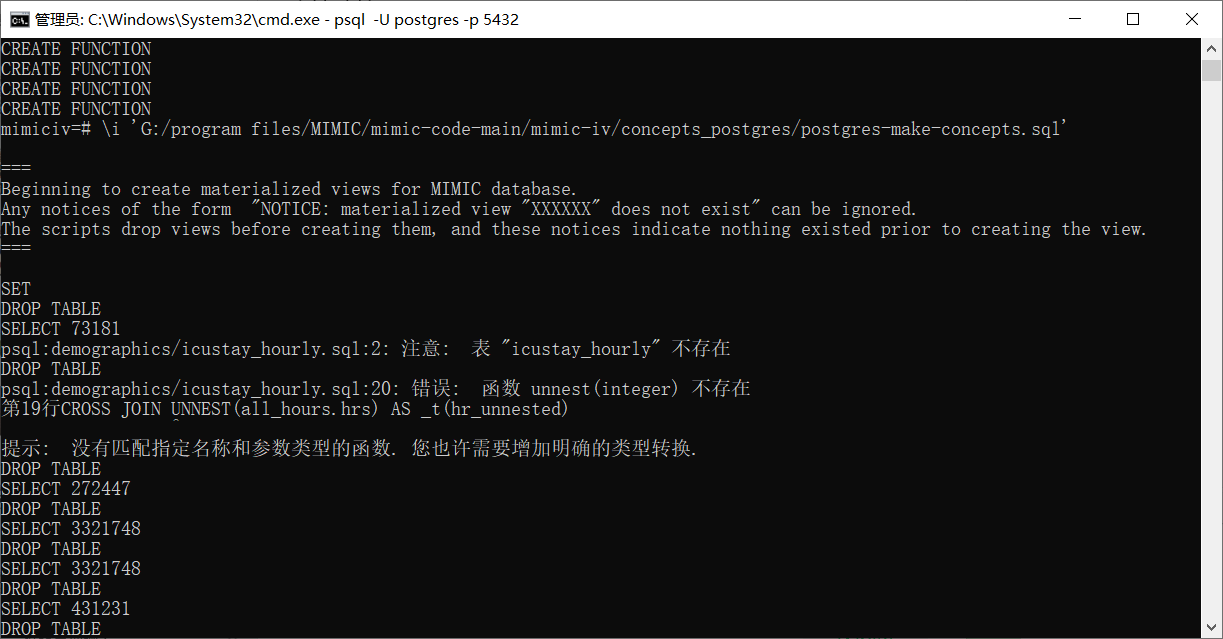
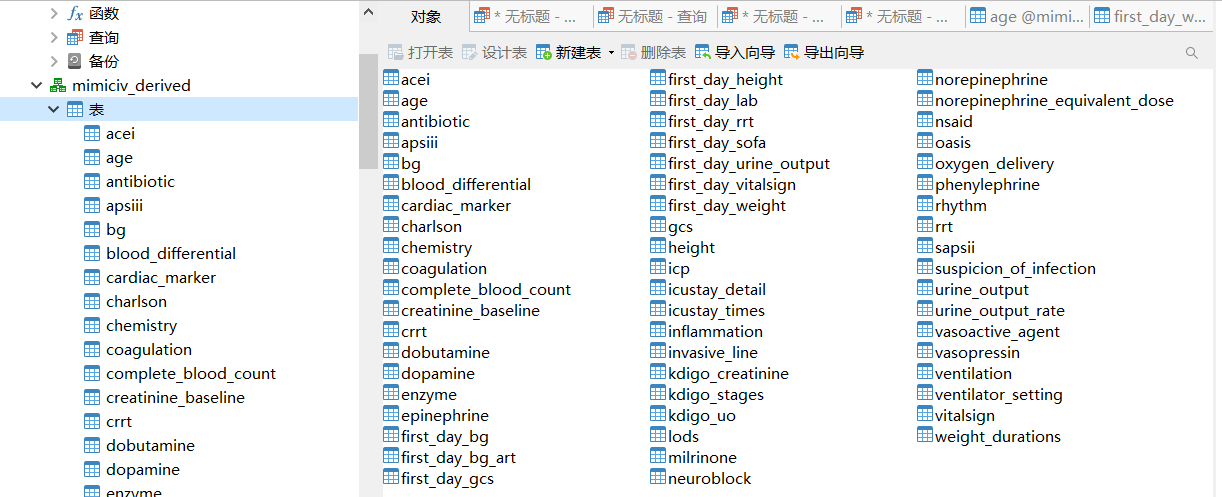
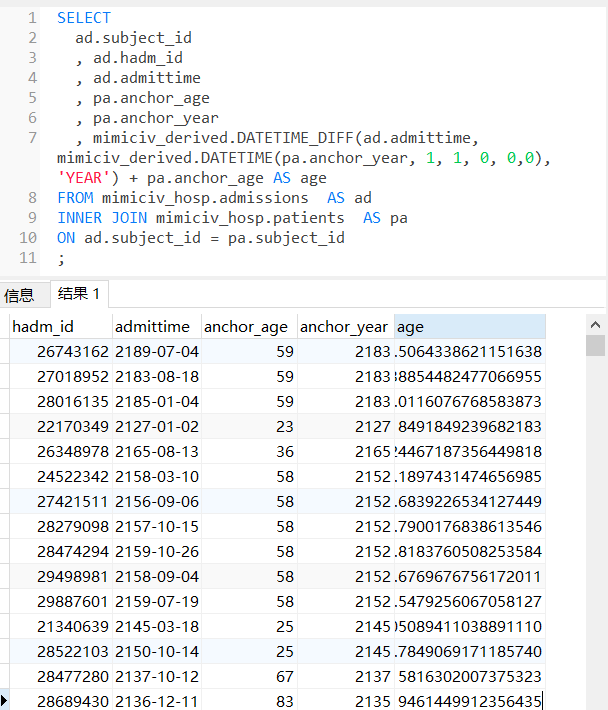
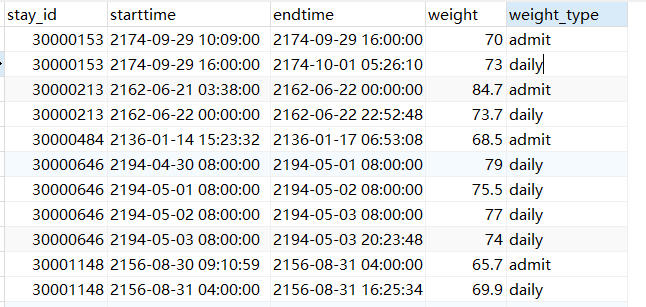
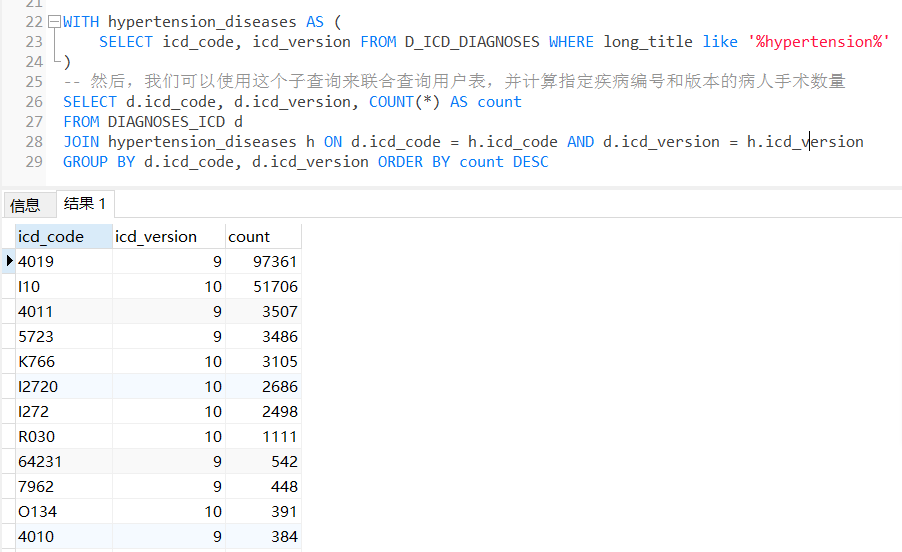
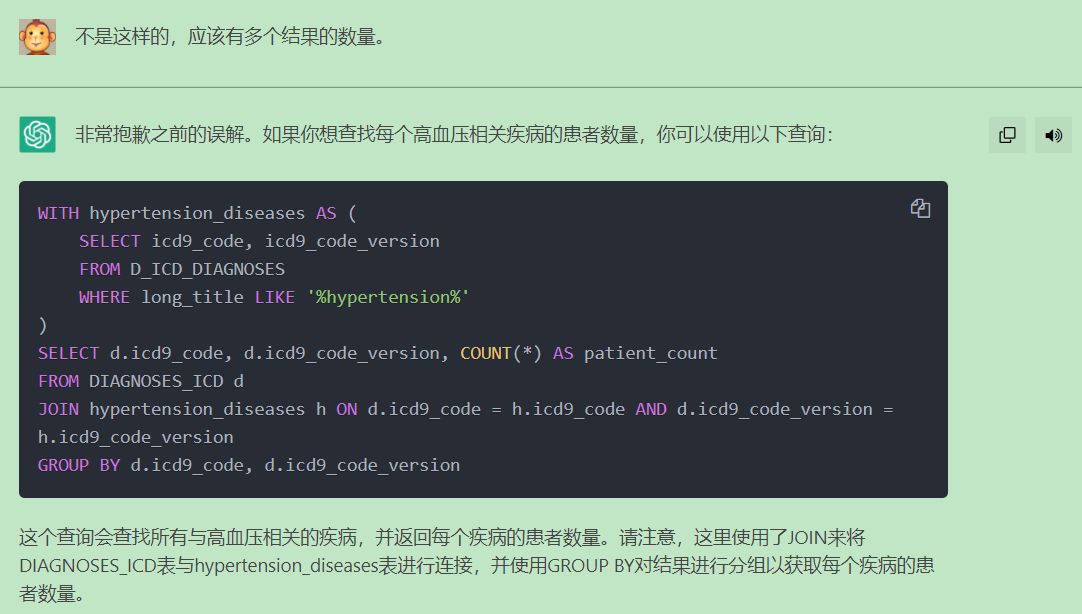
-- THIS SCRIPT IS AUTOMATICALLY GENERATED. DO NOT EDIT IT DIRECTLY.
DROP TABLE IF EXISTS mimiciv_derived.icustay_hourly; CREATE TABLE mimiciv_derived.icustay_hourly AS
/* This query generates a row for every hour the patient is in the ICU. */ /* The hours are based on clock-hours (i.e. 02:00, 03:00). */ /* The hour clock starts 24 hours before the first heart rate measurement. */ /* Note that the time of the first heart rate measurement is ceilinged to */ /* the hour. */ /* this query extracts the cohort and every possible hour they were in the ICU */ /* this table can be to other tables on stay_id and (ENDTIME - 1 hour,ENDTIME] */ /* get first/last measurement time */
WITH all_hours AS (
SELECT
it.stay_id,
CASE
WHEN DATE_TRUNC('HOUR', it.intime_hr) = it.intime_hr
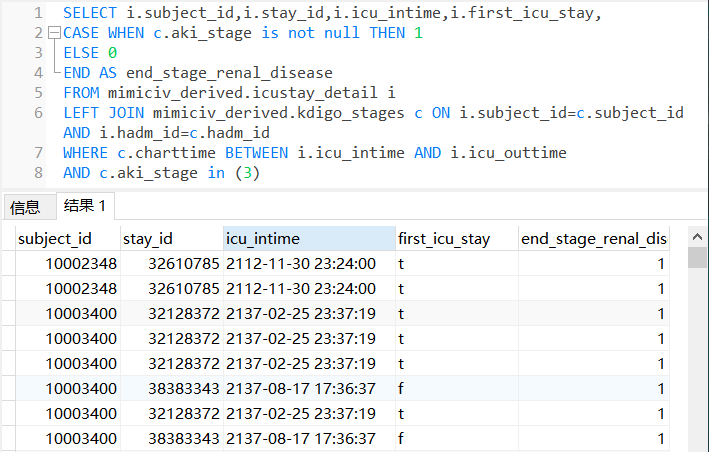
LODS(Logistic Organ Dysfunction Score):逻辑器官功能紊乱评分,是一种用于评估重症患者多器官功能停滞的评分体系。LODS通过测量患者的生理指标和临床数据,如血压、呼吸频率、血液学指标等,来评估患者器官功能的紊乱程度。该评分体系可用于评估患者的病情严重程度和疾病预后,并用于重症监护和临床研究中。
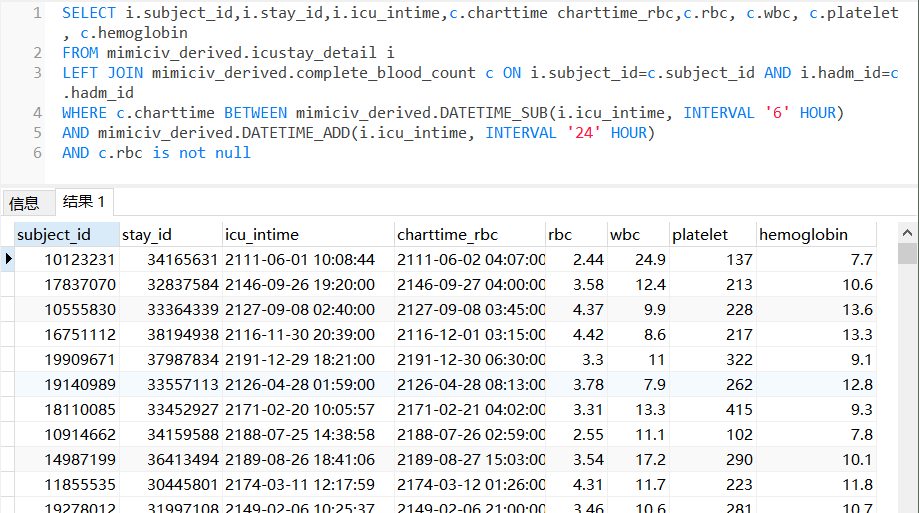
LEFT JOIN mimiciv_derived.chemistry c ON i.subject_id=c.subject_id AND i.hadm_id=c.hadm_id
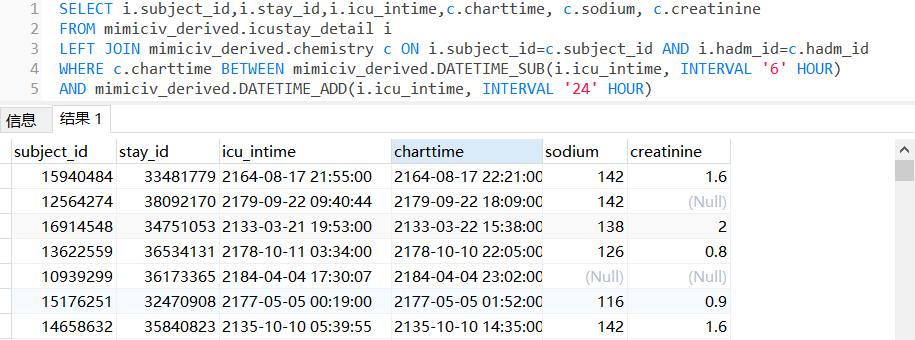
WHERE c.charttime BETWEEN mimiciv_derived.DATETIME_SUB(i.icu_intime, INTERVAL '6' HOUR)
AND mimiciv_derived.DATETIME_ADD(i.icu_intime, INTERVAL '24' HOUR)
复制代码
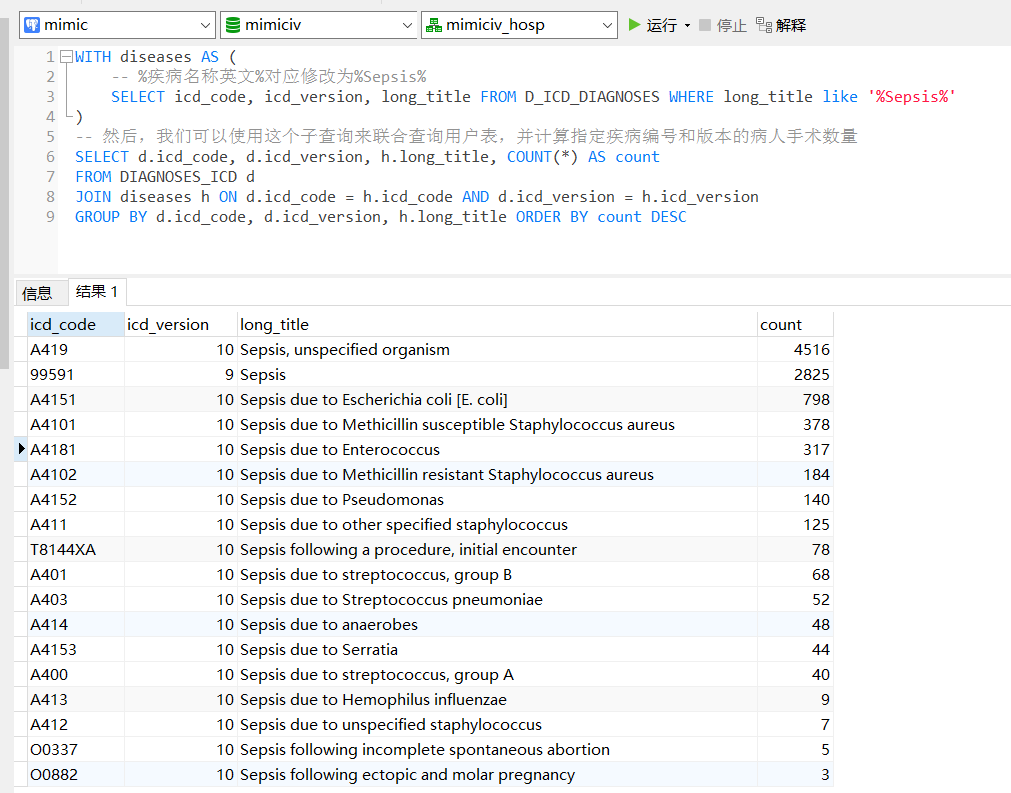
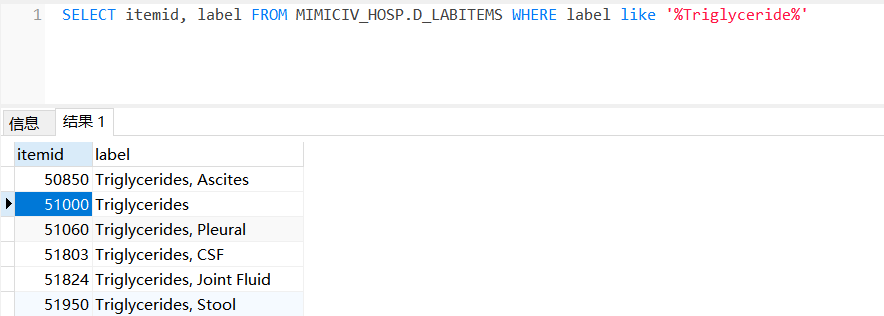
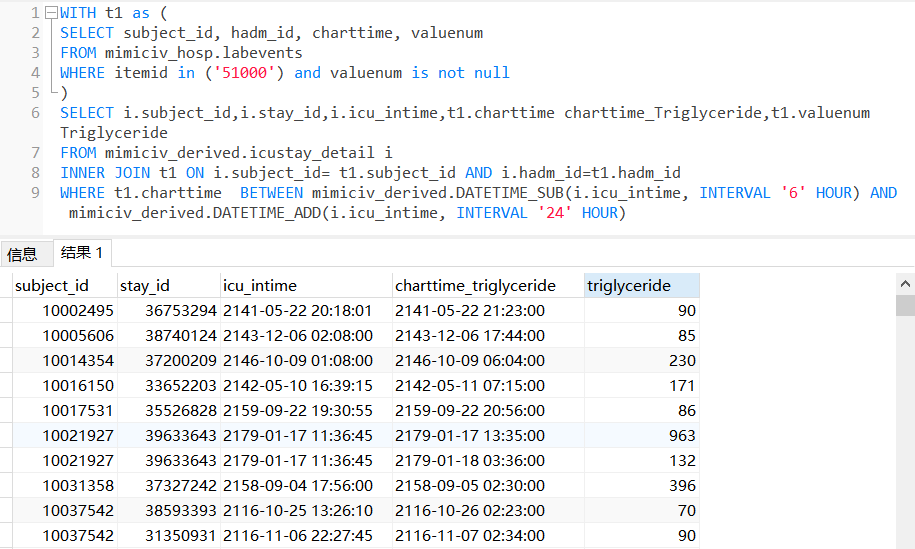
(15)甘油三脂
首先,甘油三酯的编号,在MIMICIV_HOSP.D_LABITEMS中查找,为51000。
SELECT itemid, label FROM MIMICIV_HOSP.D_LABITEMS WHERE label like '%Triglyceride%'
复制代码
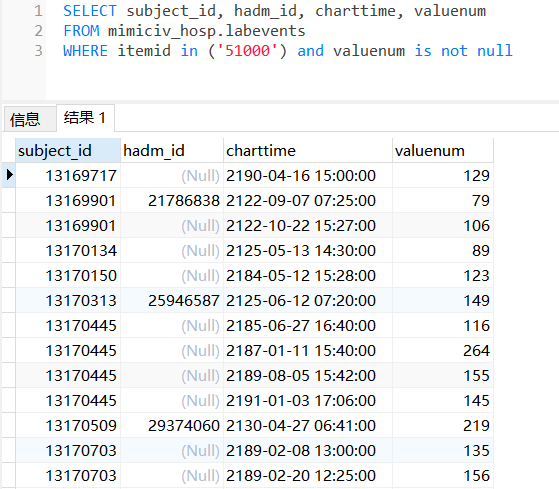
接着,查找查验表labevents,甘油三酯的检测值。
SELECT subject_id, hadm_id, charttime, valuenum
FROM mimiciv_hosp.labevents
WHERE itemid in ('51000') and valuenum is not null
复制代码
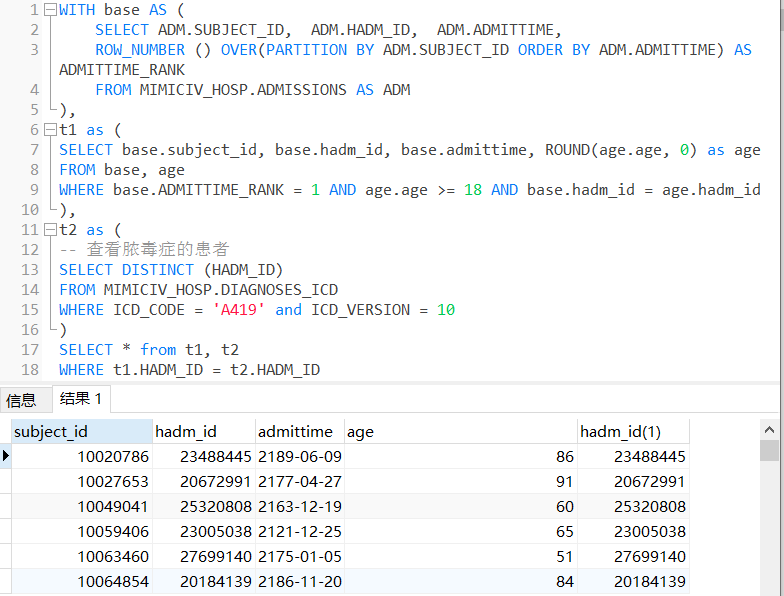
继续,获取ICU病人的数据信息。
WITH t1 as (SELECT subject_id, hadm_id, charttime, valuenum
FROM mimiciv_hosp.labevents
WHERE itemid in ('51000') and valuenum is not null)SELECT i.subject_id,i.stay_id,i.icu_intime,t1.charttime charttime_Triglyceride,t1.valuenum TriglycerideFROM mimiciv_derived.icustay_detail iINNER JOIN t1 ON i.subject_id= t1.subject_id AND i.hadm_id=t1.hadm_idWHERE t1.charttime BETWEEN mimiciv_derived.DATETIME_SUB(i.icu_intime, INTERVAL '6' HOUR) AND mimiciv_derived.DATETIME_ADD(i.icu_intime, INTERVAL '24' HOUR)
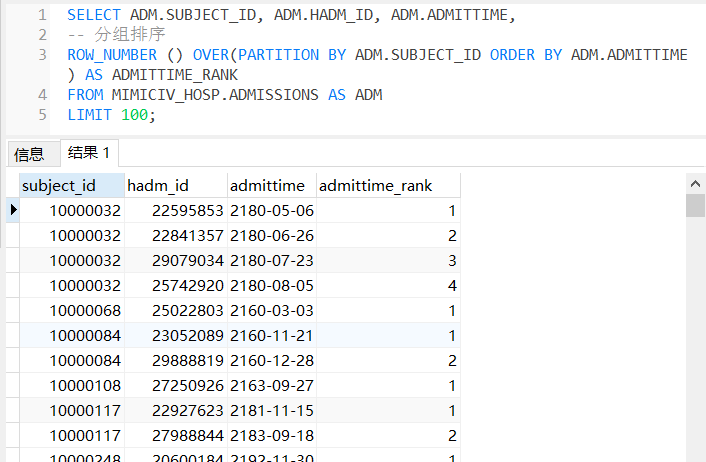
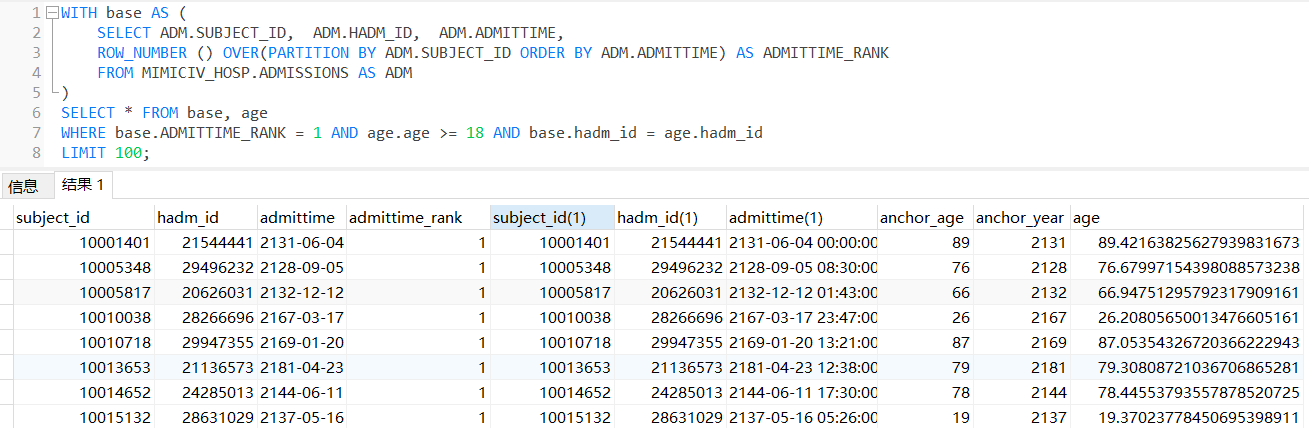
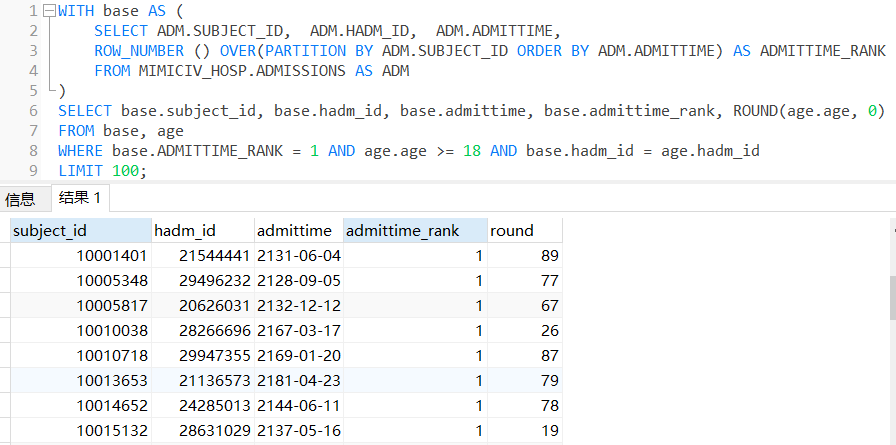
WHERE base.ADMITTIME_RANK = 1 AND age.age >= 18 AND base.hadm_id = age.hadm_id;
),
t2 as (
-- 查看脓毒症的患者
SELECT DISTINCT (HADM_ID)
FROM MIMICIV_HOSP.DIAGNOSES_ICD
WHERE ICD_CODE = 'A419' and ICD_VERSION = 10
)
SELECT * from t1,t2
WHERE t1.HADM_ID = t2.HADM_ID
复制代码
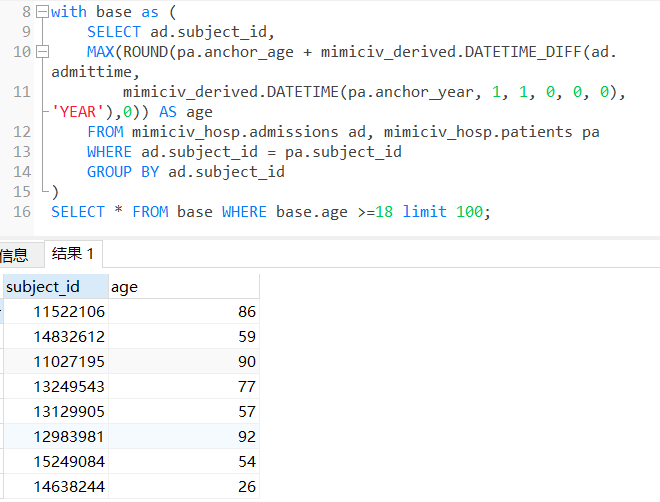
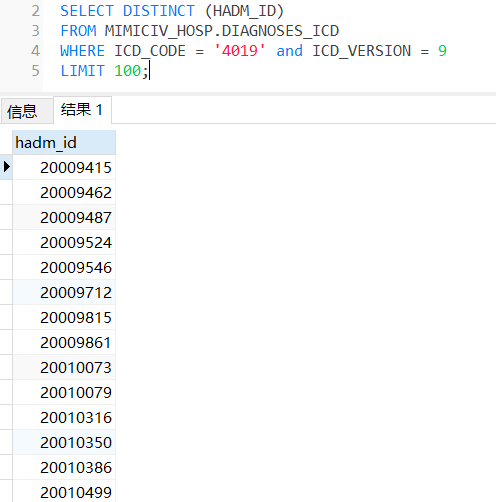
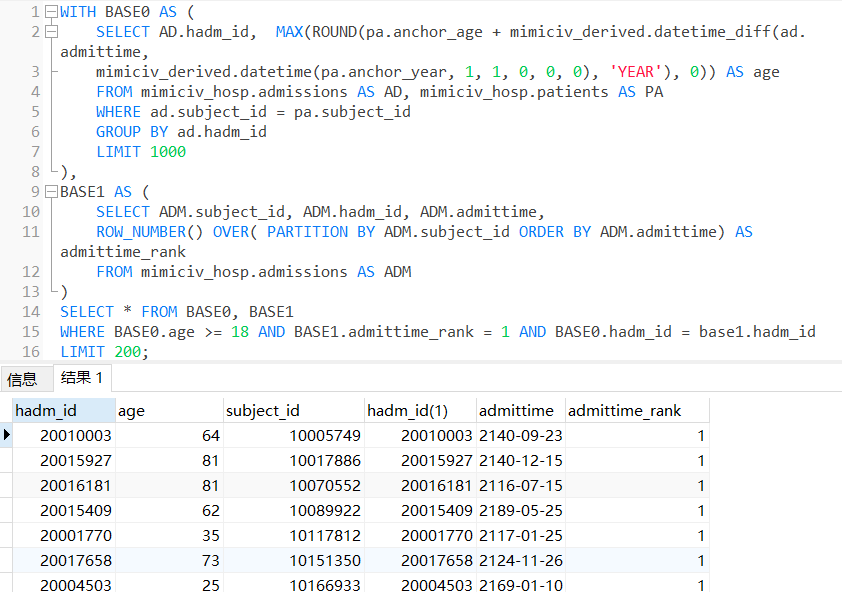
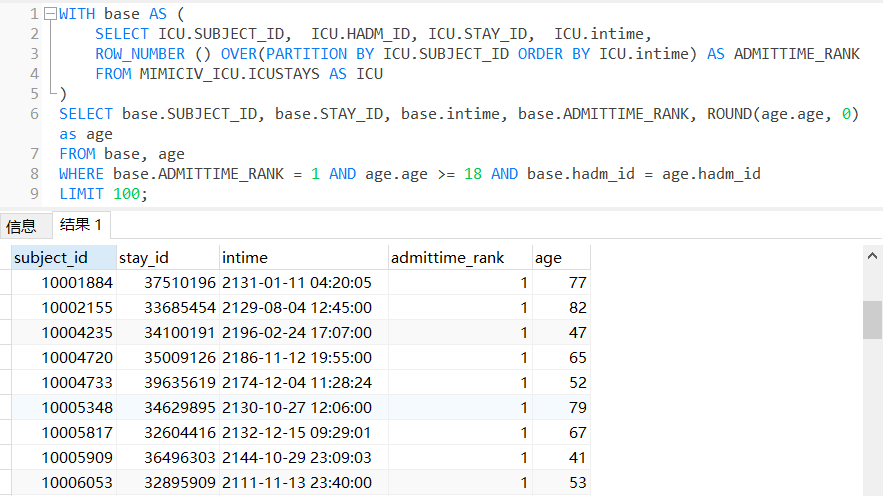
(4)首次进ICU时年龄不小于18岁的高血压患者
with t1 as(
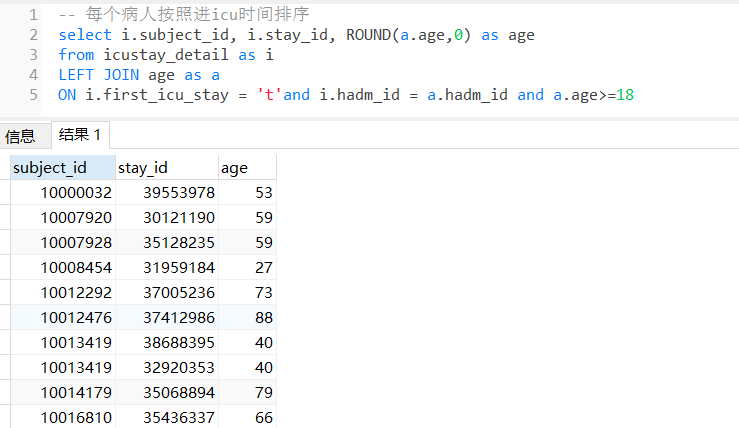
-- 用age和icustay_detail两个物化视图
select i.subject_id, i.hadm_id, i.stay_id, ROUND(a.age,0) as age
from icustay_detail as i
LEFT JOIN age as a
ON i.first_icu_stay = 't'and i.hadm_id = a.hadm_id and a.age>=18
),
t2 as (
-- 查看高血压的患者
SELECT DISTINCT (HADM_ID)
FROM MIMICIV_HOSP.DIAGNOSES_ICD
WHERE ICD_CODE = '4019' and ICD_VERSION = 9
)
SELECT * from t1,t2
WHERE t1.HADM_ID = t2.HADM_ID
复制代码
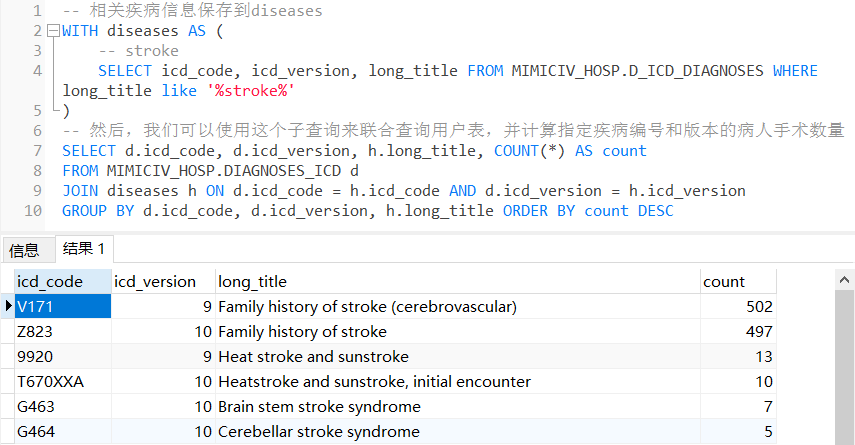
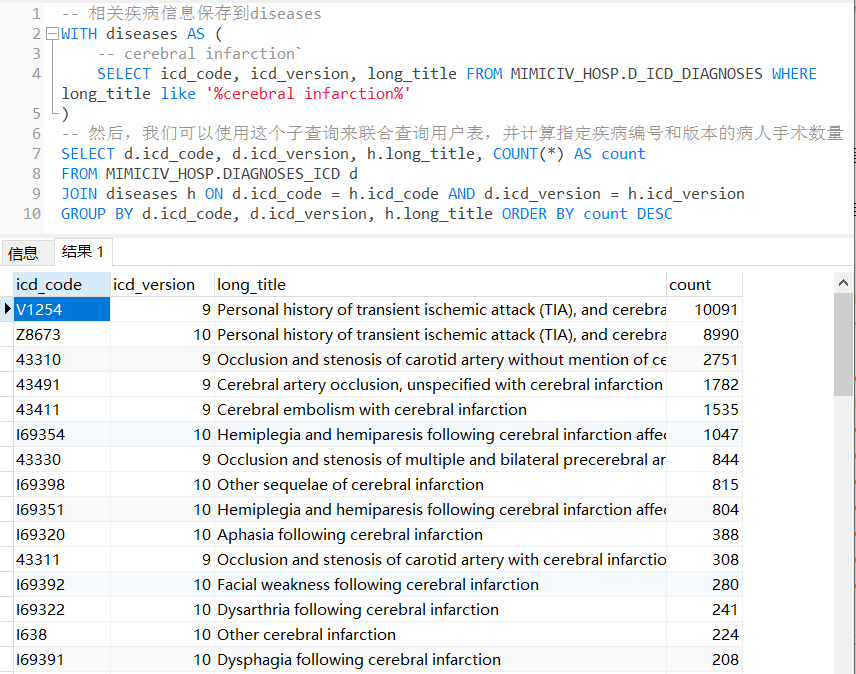
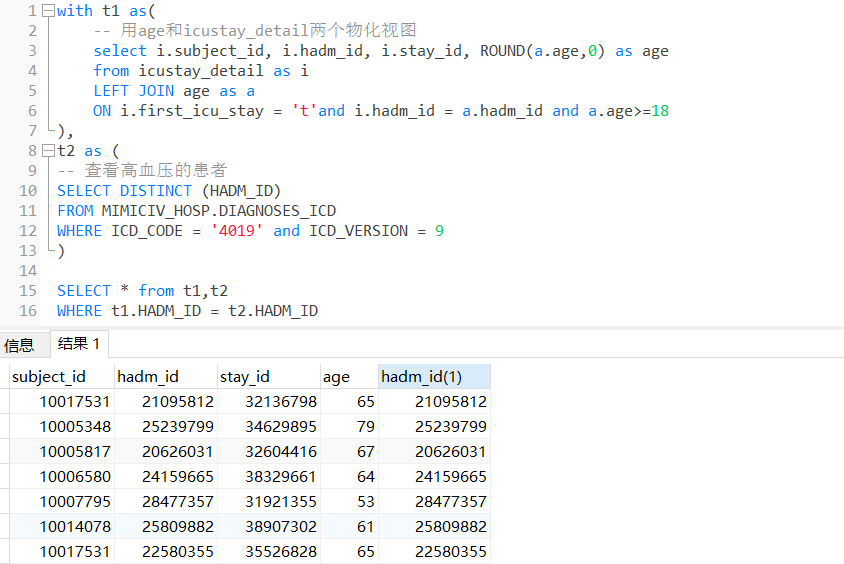
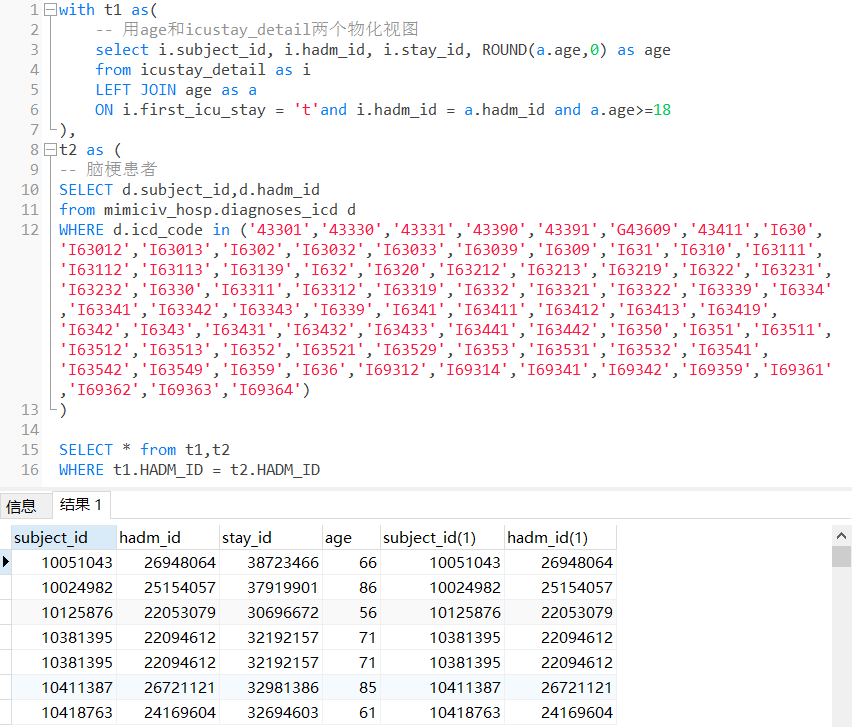
(5)首次进ICU时年龄不小于18岁的脑梗患者
with t1 as(
-- 用age和icustay_detail两个物化视图
select i.subject_id, i.hadm_id, i.stay_id, ROUND(a.age,0) as age
from icustay_detail as i
LEFT JOIN age as a
ON i.first_icu_stay = 't'and i.hadm_id = a.hadm_id and a.age>=18
),
t2 as (
-- 脑梗患者
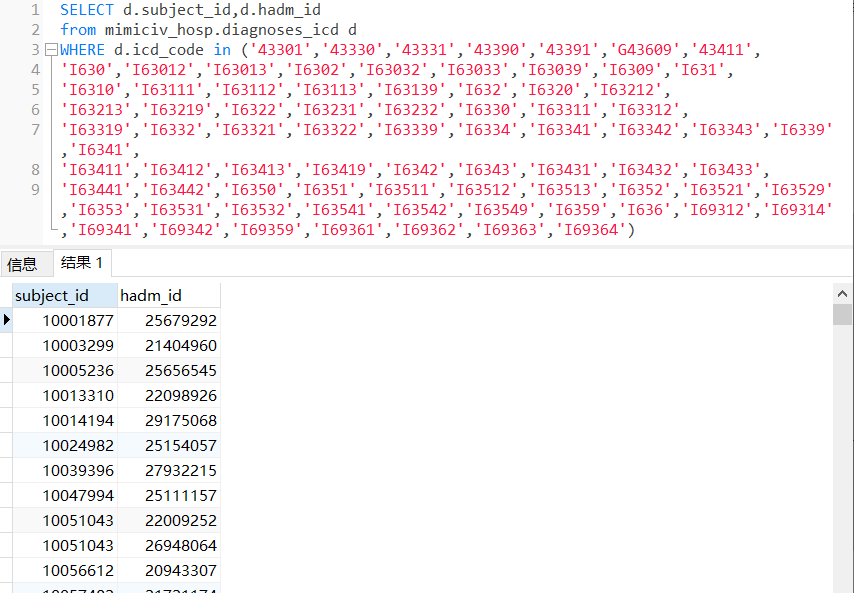
SELECT d.subject_id,d.hadm_id
from mimiciv_hosp.diagnoses_icd d
WHERE d.icd_code in ('43301','43330','43331','43390','43391','G43609','43411','I630','I63012','I63013','I6302','I63032','I63033','I63039','I6309','I631','I6310','I63111','I63112','I63113','I63139','I632','I6320','I63212','I63213','I63219','I6322','I63231','I63232','I6330','I63311','I63312','I63319','I6332','I63321','I63322','I63339','I6334','I63341','I63342','I63343','I6339','I6341','I63411','I63412','I63413','I63419','I6342','I6343','I63431','I63432','I63433','I63441','I63442','I6350','I6351','I63511','I63512','I63513','I6352','I63521','I63529','I6353','I63531','I63532','I63541','I63542','I63549','I6359','I636','I69312','I69314','I69341','I69342','I69359','I69361','I69362','I69363','I69364')
)
SELECT t1.* from t1,t2
WHERE t1.HADM_ID = t2.HADM_ID
复制代码
保存到一个表里。
-- 创建并保存到新表icu_ci
CREATE TABLE icu_ci as (
with t1 as(
-- 用age和icustay_detail两个物化视图
select i.subject_id, i.hadm_id, i.stay_id, ROUND(a.age,0) as age
from mimiciv_derived.icustay_detail as i
LEFT JOIN mimiciv_derived.age as a
ON i.first_icu_stay = 't'and i.hadm_id = a.hadm_id and a.age>=18
),
t2 as (
-- 脑梗患者
SELECT d.subject_id,d.hadm_id
from mimiciv_hosp.diagnoses_icd d
WHERE d.icd_code in ('43301','43330','43331','43390','43391','G43609','43411','I630','I63012','I63013','I6302','I63032','I63033','I63039','I6309','I631','I6310','I63111','I63112','I63113','I63139','I632','I6320','I63212','I63213','I63219','I6322','I63231','I63232','I6330','I63311','I63312','I63319','I6332','I63321','I63322','I63339','I6334','I63341','I63342','I63343','I6339','I6341','I63411','I63412','I63413','I63419','I6342','I6343','I63431','I63432','I63433','I63441','I63442','I6350','I6351','I63511','I63512','I63513','I6352','I63521','I63529','I6353','I63531','I63532','I63541','I63542','I63549','I6359','I636','I69312','I69314','I69341','I69342','I69359','I69361','I69362','I69363','I69364')