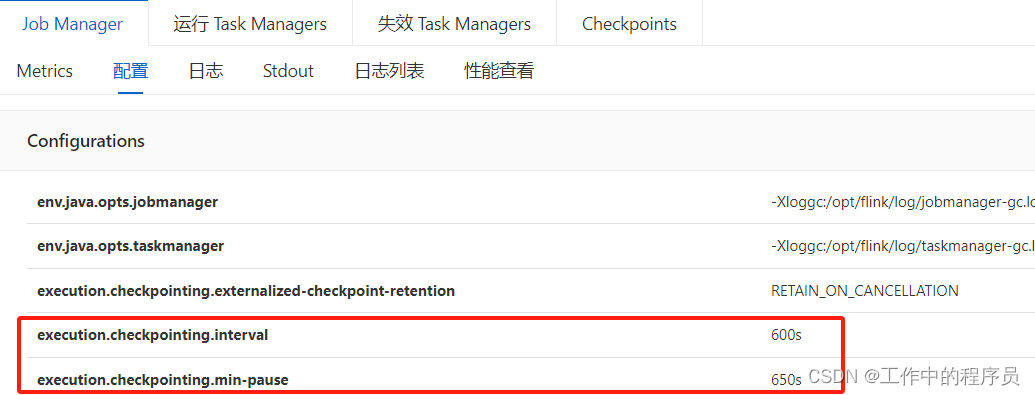
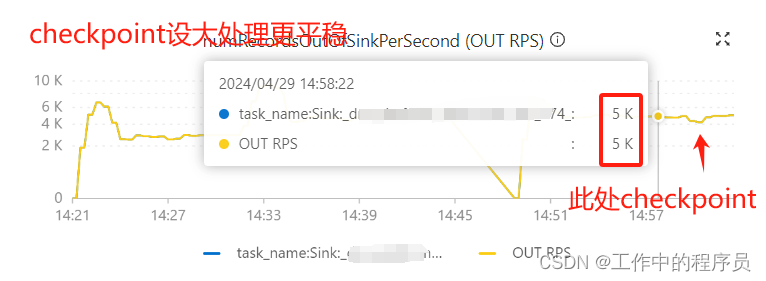
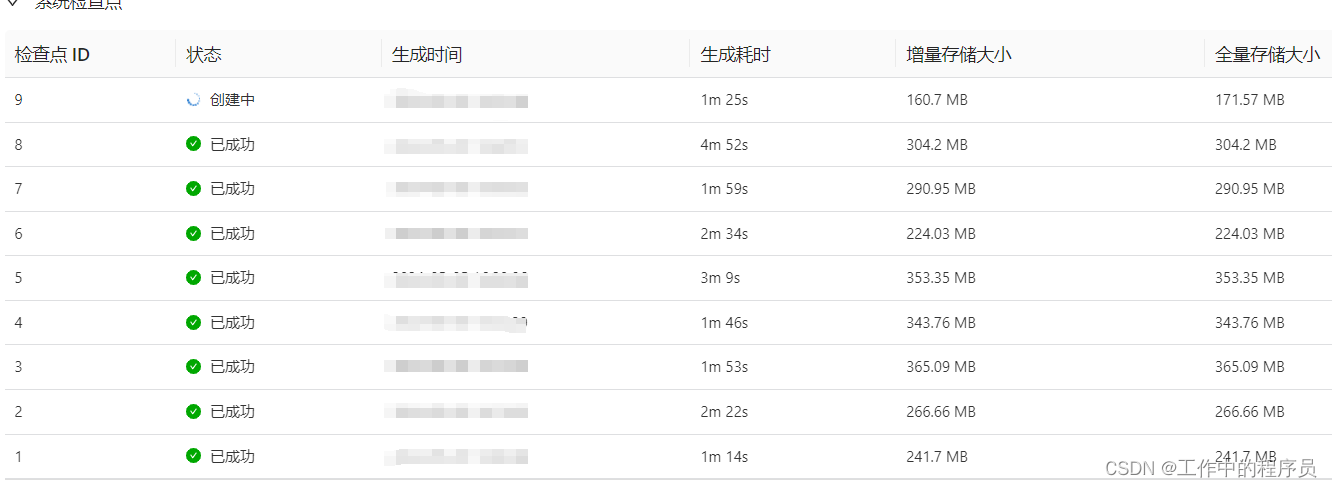
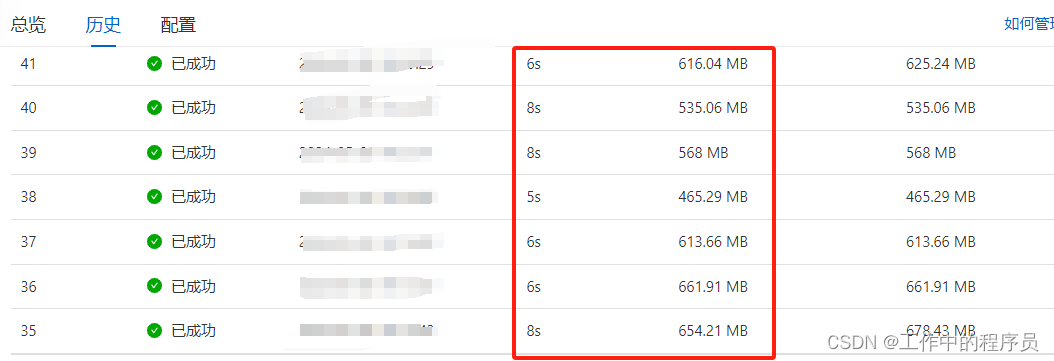
1).调大checkpoint生成时间
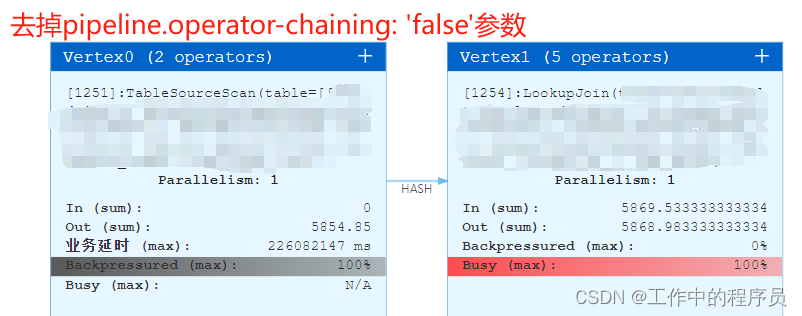
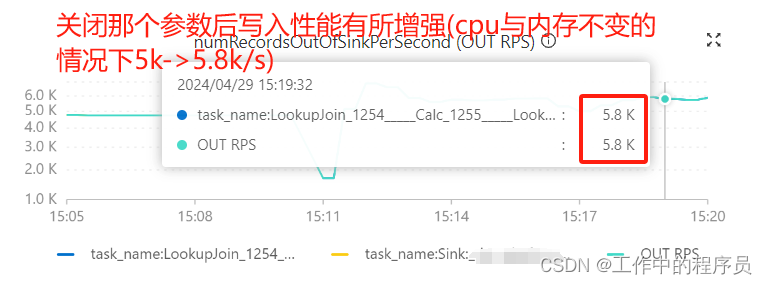
2).去掉参数:pipeline.operator-chaining: ‘false’
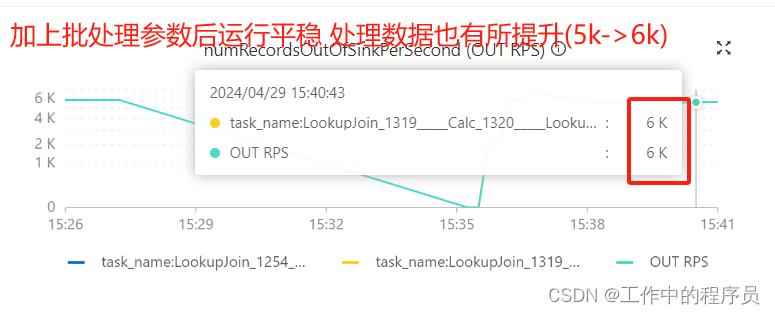
3).加攒批参数

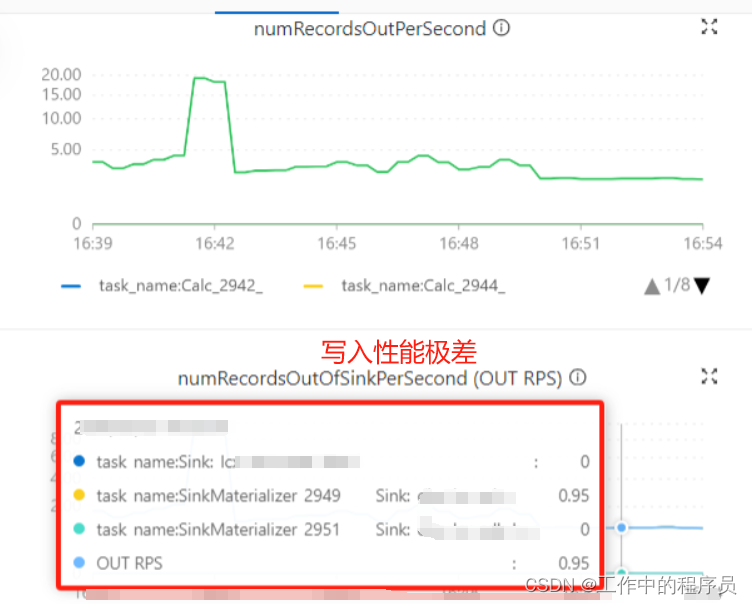
4).由于full GC导致job性能过差(排查)
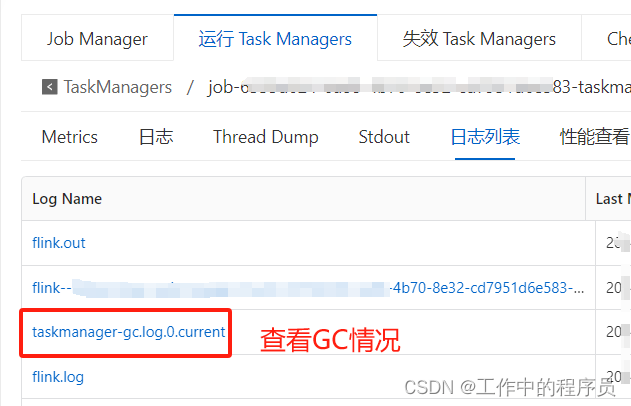
查看gc日志:
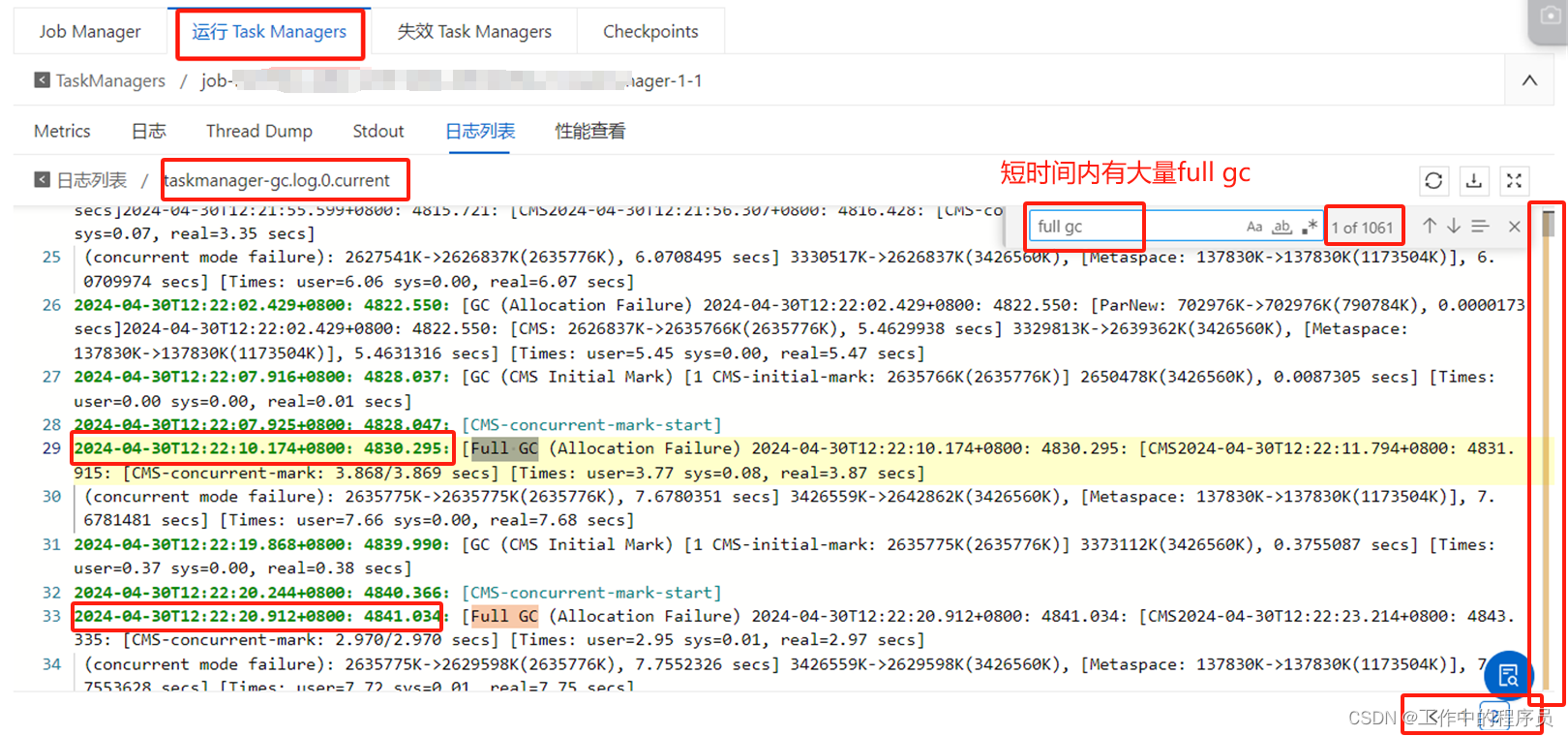
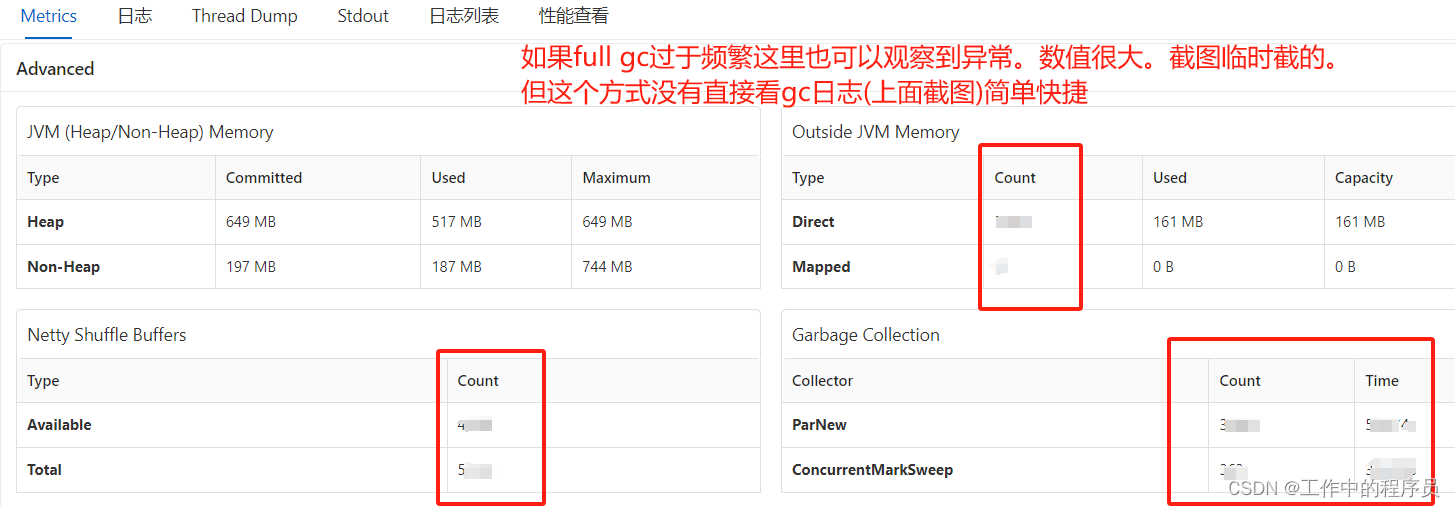
解决方案:对taskmanager增加内存(jobmanager略,因为它很少会出现频仍full gc)。
 flink 双流join) 默认资源配置(taskmanager 1cpu,4Bb内存,1个槽位,1个并行度)
flink 双流join) 默认资源配置(taskmanager 1cpu,4Bb内存,1个槽位,1个并行度)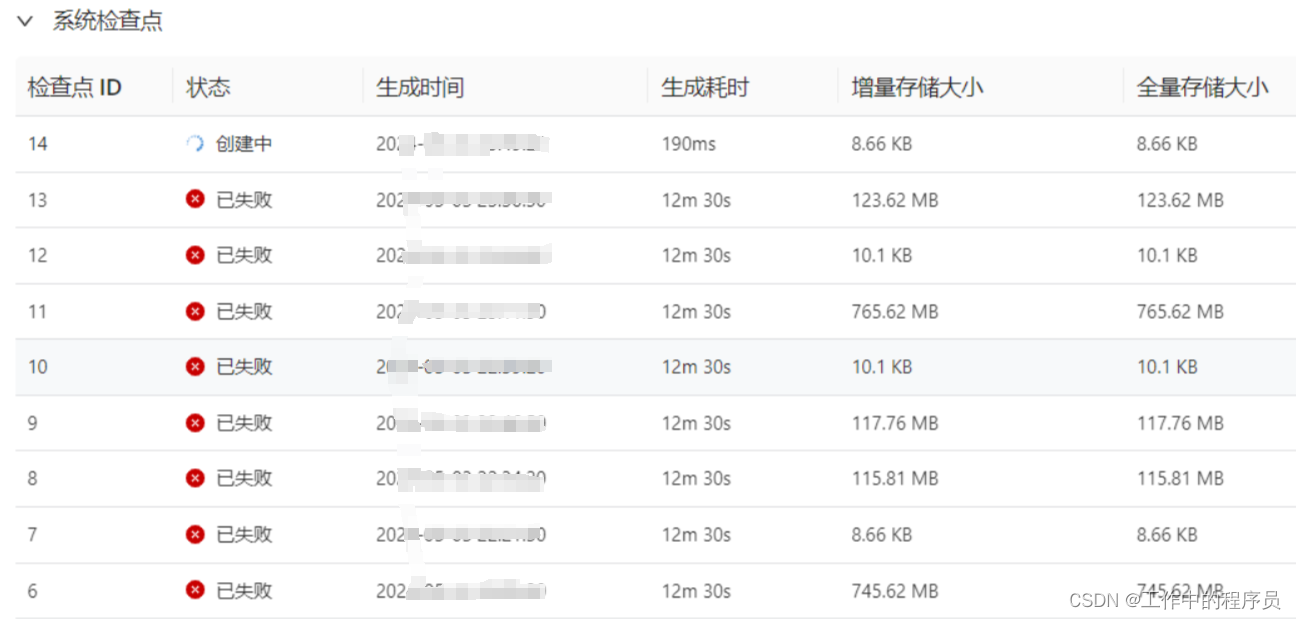


| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |