标题: AIGC-CVPR2024best paper-Rich Human Feedback for Text-to-Image Generati [打印本页] 作者: 天津储鑫盛钢材现货供应商 时间: 2024-8-5 08:33 标题: AIGC-CVPR2024best paper-Rich Human Feedback for Text-to-Image Generati Rich Human Feedback for Text-to-Image Generation斩获CVPR2024最佳论文!受大模子中的RLHF技能开导,团队用人类反馈来改进Stable Diffusion等文生图模子。这项研究来自UCSD、谷歌等。
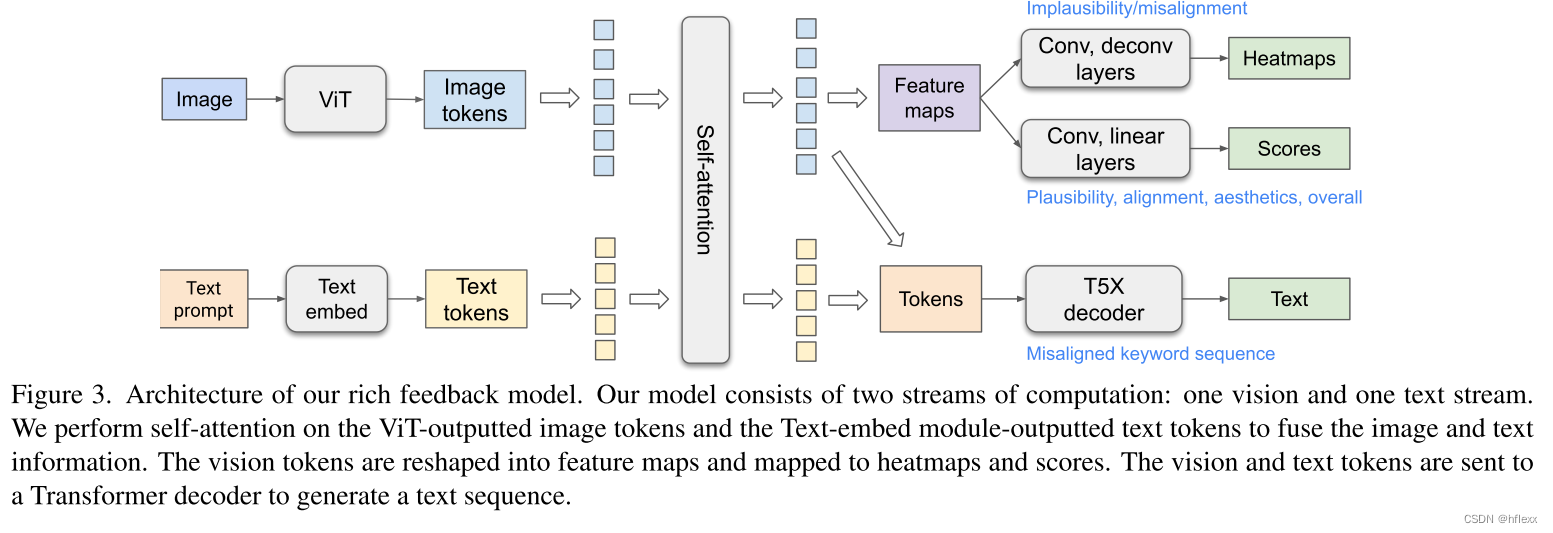
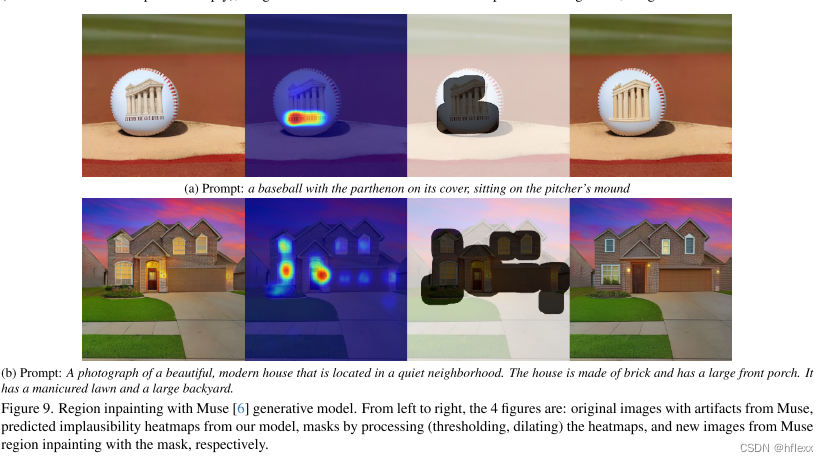
在本文中,作者通过标记不可信或与文本不对齐的图像区域,以及解释文本提示中的哪些单词在图像上被歪曲或丢失来丰富反馈信号。 在 18K 生成图像 (RichHF18K) 上收集如此丰富的人类反馈,并练习多模态转换器来自动预测丰富的反馈。 实验结果表明,可以利用预测的丰富人类反馈来改进图像生成,例如,通过选择高质量的练习数据来微调和改进生成模子,大概通过使用预测的热图创建mask来修复有问题的区域。 值得注意的是,除了用于生成收集人类反馈数据的图像(稳定扩散变体)之外,这些改进还推广到了模子(Muse)。
论文:https://arxiv.org/pdf/2312.10240
MOTIVATION
many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality.(伪影和错位问题)
Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation.
There has been much recent work on evaluation of text-to-image models along many dimensions,but the focus of their work is artifact region only.
最能形貌图像的类别是什么?从“人类”、“动物”、“物体”、“室内场景”、“室外场景”中选择。(Which category best describes the image? Choose one in ‘human’, ‘animal’, ‘object’, ‘indoor scene’, ‘outdoor scene’)
数据统计和标注者同等性分析
分数尺度化:使用公式 s norm = s − s min s max − s min \text{s}_{\text{norm}} = \frac{s - s_{\text{min}}}{s_{\text{max}} - s_{\text{min}}} snorm=smax−smins−smin(此中 s max = 5 s_{\text{max}} = 5 smax=5, s min = 1 s_{\text{min}} = 1 smin=1对分数举行尺度化,使分数范围在[0, 1]内。
分数分布:分数的分布类似于高斯分布,合理性和文本-图像对齐分数的1.0得分比例略高。
样本平衡:收集的分数分布确保了练习良好嘉奖模子的负面和正面样本数量合理。
标注者同等性:为了分析标注者对图像-文本对的评分同等性,计算分数之间的最大差异: maxdiff = max ( scores ) − min ( scores ) \text{maxdiff} = \max(\text{scores}) - \min(\text{scores}) maxdiff=max(scores)−min(scores),此中分数是图像-文本对的三个评分标签。约莫25%的样本有完美的标注者同等性,约莫85%的样本有良好的标注者同等性(在尺度化后maxdiff小于等于0.25或5点Likert量表上的1)。