IT评测·应用市场-qidao123.com技术社区
标题:
【八】Zookeeper3.7.1集成Hadoop3.3.4集群安装
[打印本页]
作者:
泉缘泉
时间:
2024-8-5 12:37
标题:
【八】Zookeeper3.7.1集成Hadoop3.3.4集群安装
1.根本原理
ZooKeeper 是一个分布式协调服务,用于分布式体系中管理配置信息、命名、同步和集群服务。它提供了一种简单的接口来访问存储在其文件体系中的数据,同时为复杂的分布式体系提供了高可用性和划一性保障。以下是 ZooKeeper 的根本原理:
1 . 数据模型和 ZNode
数据模型
:ZooKeeper 以分层命名空间的方式存储数据,类似于文件体系。每个节点称为一个 ZNode。
ZNode
:ZNode 是 ZooKeeper 中的根本数据单元,可以存储少量数据。它有两种范例:
持久节点(Persistent ZNode)
:即使客户端断开连接或体系重启,节点数据也会不停存在。
临时节点(Ephemeral ZNode)
:客户端会话结束时主动删除。
顺序节点(Sequential ZNode)
:主动在名称末尾附加一个单调递增的数字。
2 . 划一性保证
ZooKeeper 提供了划一性保障,确保以下条件:
原子性
:操作要么乐成,要么失败,没有中间状态。
顺序划一性
:所有操作按照它们的执行顺序举行。
单一体系映像
:所有客户端无论连接到哪个 ZooKeeper 服务器,看到的数据都是划一的。
耐久性
:一旦操作乐成执行,数据将被持久化,不会丢失。
实时性
:在合理的时间内,客户端可以看到最近的体系状态。
3 . Leader 选举和复制
集群角色
:ZooKeeper 集群由多个服务器(节点)构成,此中一个节点是 Leader,其余是 Follower。
Leader 选举
:在集群启动或 Leader 故障时,ZooKeeper 利用选举算法(如基于 ZAB 协议的选举)选举新的 Leader。
数据复制
:Leader 负责处置处罚所有的写请求,并将更新同步到所有 Follower,从而保持数据划一性。读请求可以由任何 Follower 处置处罚。
会话和 Watcher
会话
:客户端与 ZooKeeper 服务器之间的连接称为会话。会话有超时机制,如果客户端在指定时间内没有发送心跳包,ZooKeeper 将以为会话结束。
Watcher
:ZooKeeper 提供了一种监控机制,称为 Watcher。客户端可以在 ZNode 上设置 Watcher,当节点状态发生变化时,ZooKeeper 会通知客户端。这种机制常用于配置管理、命名服务和分布式锁等场景。
5 . 高可用性和容错
高可用性
:ZooKeeper 依靠于集群的多台服务器提供服务,即使部分节点故障,也能继续提供服务。
容错性
:ZooKeeper 能容忍少数节点的故障,而无需制止服务。只要集群中的活跃节点数量超过总节点数的一半(即超过多数节点),ZooKeeper 就能继续正常工作。
6 . ZAB 协议
ZooKeeper 利用的 ZAB 协议(ZooKeeper Atomic Broadcast)是一种基于投票的协议,确保了事件的顺序划一性和数据的复制。它包罗两部分:
选举阶段
(用于选举 Leader)和
广播阶段
(用于复制数据)。
7 . 典型应用
ZooKeeper 常用于分布式体系中的服务注册和发现、分布式锁、配置管理、分布式消息队列等。其高可用性和划一性特性使其成为这些场景中的关键组件。
总之,ZooKeeper 通过提供可靠的分布式协调机制和数据划一性保障,为分布式体系的构建和管理提供了强有力的支持。
2.下载并解压ZooKeeper
1 . 环境准备
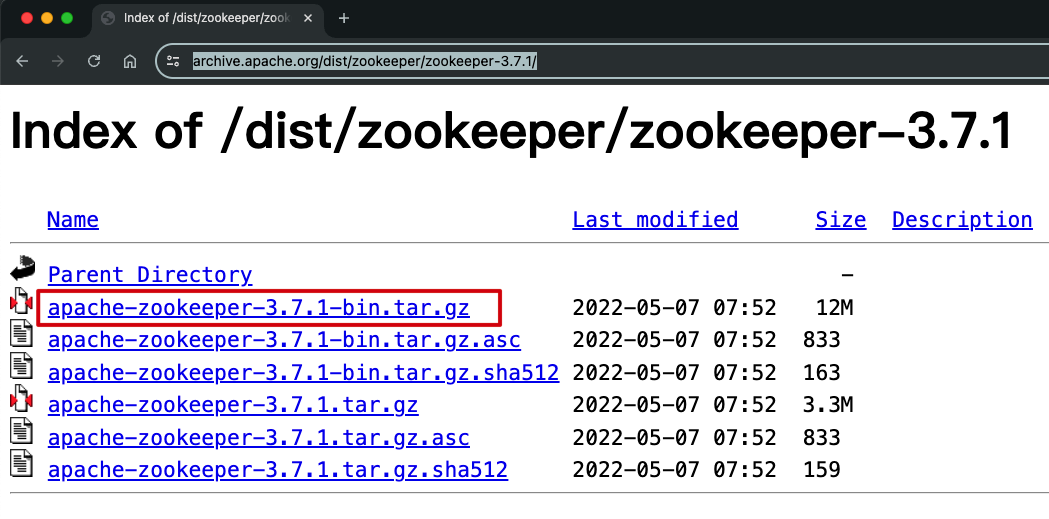
hostnameipubuntu1172.16.167.131ubuntu2172.16.167.132ubuntu3172.16.167.133 2 . 下载ZooKeeper 3.7.1(或其他兼容版本)的二进制文件
https://archive.apache.org/dist/zookeeper/zookeeper-3.7.1/
复制代码
3 . 解压缩文件并将其移动到适当的目录:
tar -xzf apache-zookeeper-3.7.1-bin.tar.gz
mv apache-zookeeper-3.7.1-bin /usr/local/zookeeper
复制代码
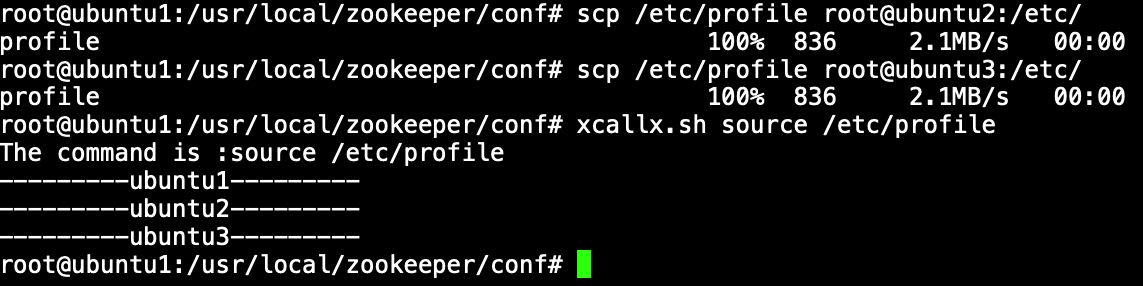
3.配置环境变量
1 . 编辑/etc/profile文件,添加ZooKeeper的环境变量:
vim /etc/profile
复制代码
2 . 添加以下内容:
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
复制代码
3 . 刷新环境变量:
source /etc/profile
复制代码
4 . 将环境变量分发到其他节点并刷新
4.配置ZooKeeper
1 . 进入ZooKeeper的配置目录:
cd /usr/local/zookeeper/conf
复制代码
2 . 复制zoo_sample.cfg为zoo.cfg:
cp zoo_sample.cfg zoo.cfg
复制代码
3 . 编辑zoo.cfg文件,举行根本配置:
vim zoo.cfg
复制代码
根据你的集群环境修改以下内容,目录一定要注意:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=10
syncLimit=5
server.1=ubuntu1:2888:3888
server.2=ubuntu2:2888:3888
server.3=ubuntu3:2888:3888
复制代码
tickTime:ZooKeeper中两个心跳之间的根本时间单元,以毫秒为单元。
dataDir:存储快照的目录。
clientPort:客户端连接到ZooKeeper服务器的端口。
initLimit:允许跟随者(Follwer)在连接并同步到Leader之前可以举行的心跳数。
syncLimit:Leader与Follower之间发送消息、请求和响应时间的数量。
server.X:ZooKeeper集群中服务器的配置,ubuntu1, ubuntu2, ubuntu3是你的服务器主机名或IP地址。
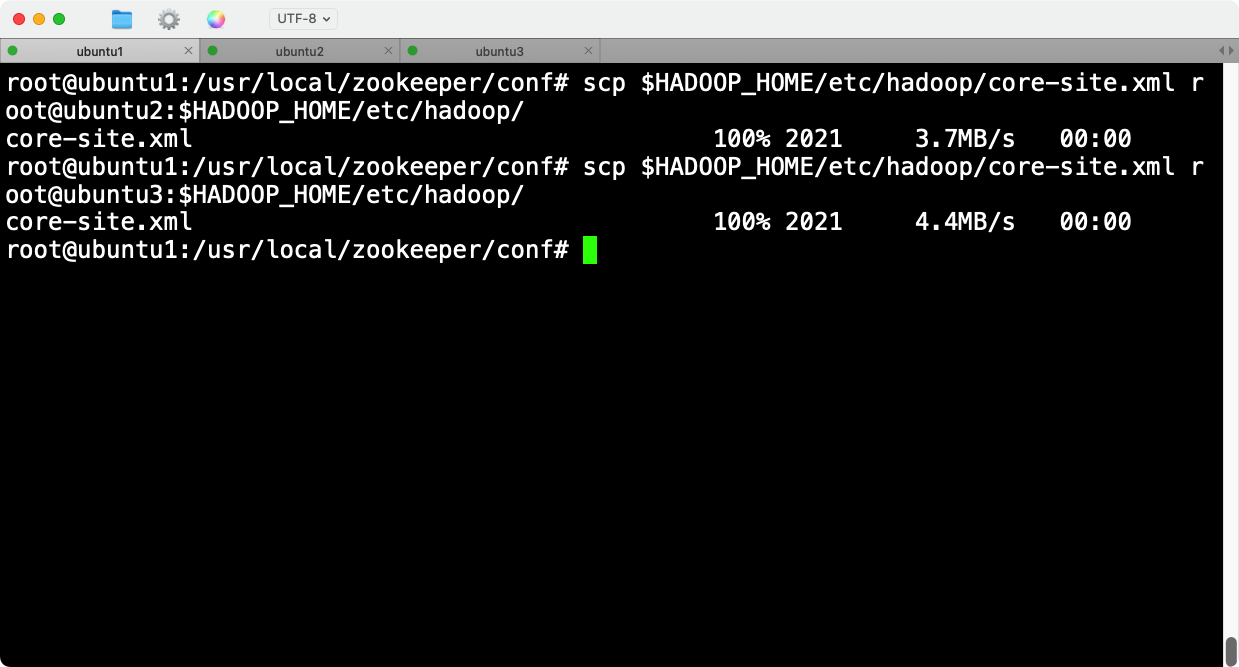
用scp命令,将zookeeper分发到所有节点。
5.创建数据目录并初始化myid
1 . 在每个ZooKeeper节点上创建数据目录:
mkdir -p /var/lib/zookeeper
chmod -R 755 /var/lib/zookeeper
复制代码
2 . 在每个节点的数据目录中创建myid文件,并写入对应的服务器编号(1,2,3):
echo "1" > /var/lib/zookeeper/myid # 在ubuntu1上
echo "2" > /var/lib/zookeeper/myid # 在ubuntu2上
echo "3" > /var/lib/zookeeper/myid # 在ubuntu3上
复制代码
6.启动ZooKeeper
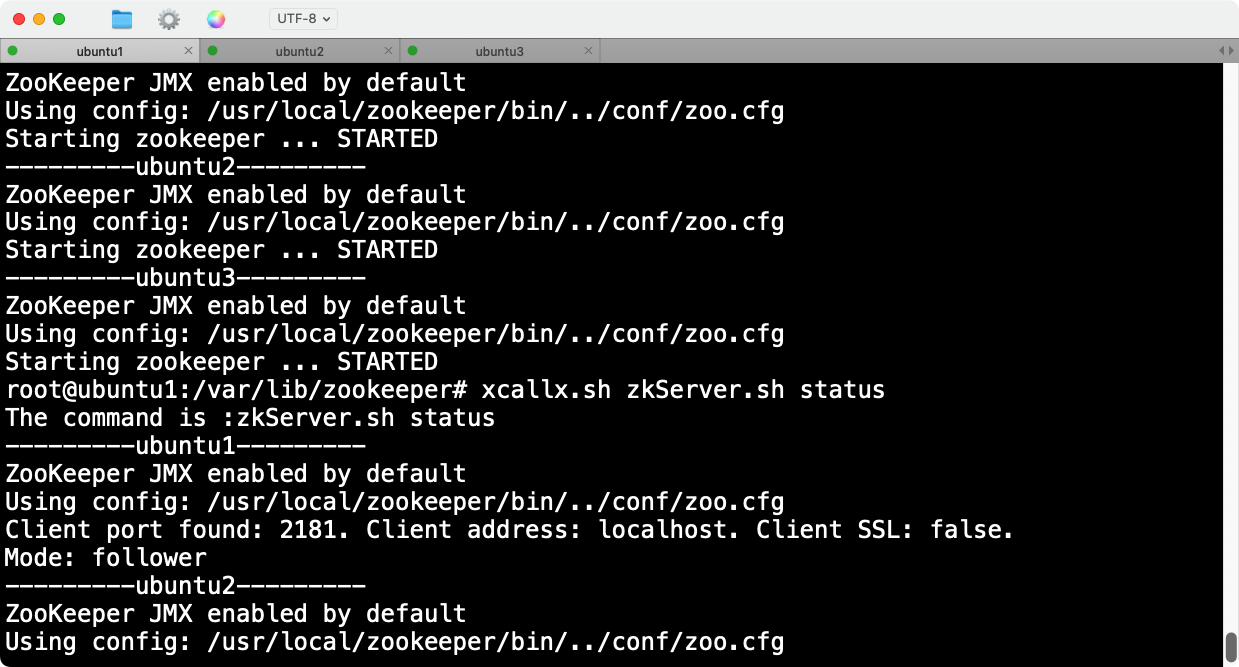
1 . 在每个节点上启动ZooKeeper服务:
zkServer.sh start
复制代码
2 . 验证每个节点ZooKeeper是否正常启动:
zkServer.sh status
复制代码
7.配置ZooKeeper集成到Hadoop
1 . 修改Hadoop的core-site.xml文件,添加ZooKeeper的Quorum配置:
vim $HADOOP_HOME/etc/hadoop/core-site.xml
复制代码
2 . 添加以下内容:
<property>
<name>ha.zookeeper.quorum</name>
<value>ubuntu1:2181,ubuntu2:2181,ubuntu3:2181</value>
</property>
复制代码
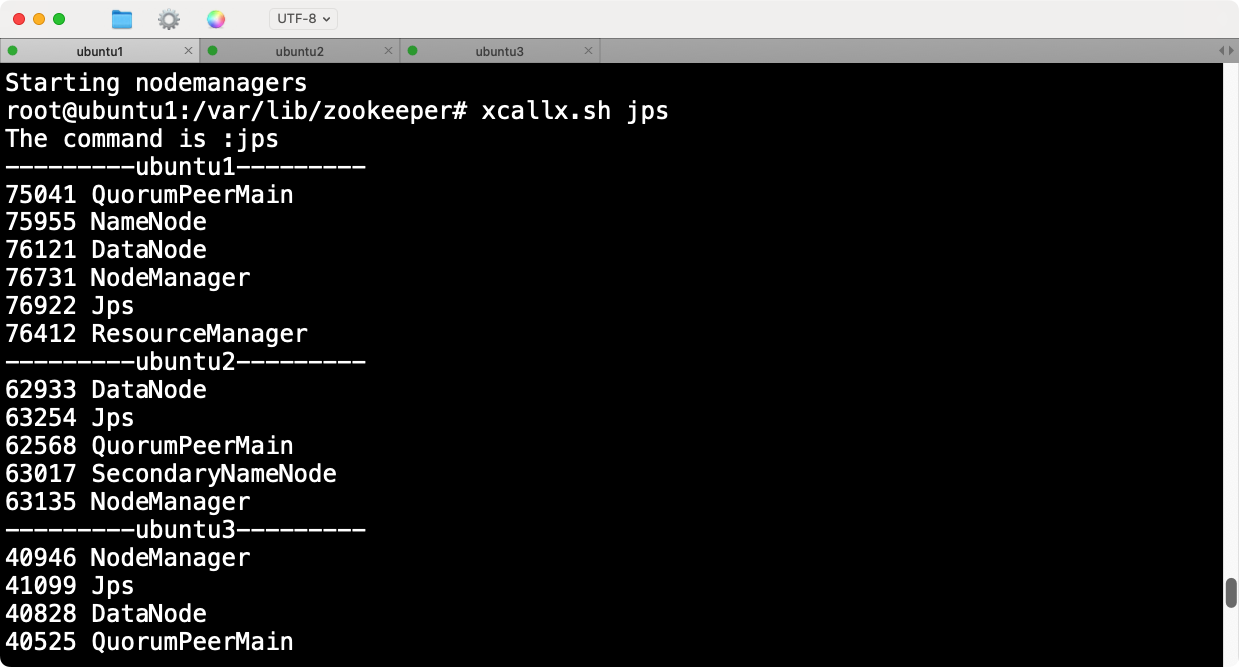
8.重启Hadoop
1 . 重新启动Hadoop集群以应用新的配置:
stop-all.sh
start-all.sh
复制代码
9.ZooKeeper状态检查
利用ZooKeeper命令行客户端检查ZooKeeper的状态:
zkCli.sh -server ubuntu1:2181
复制代码
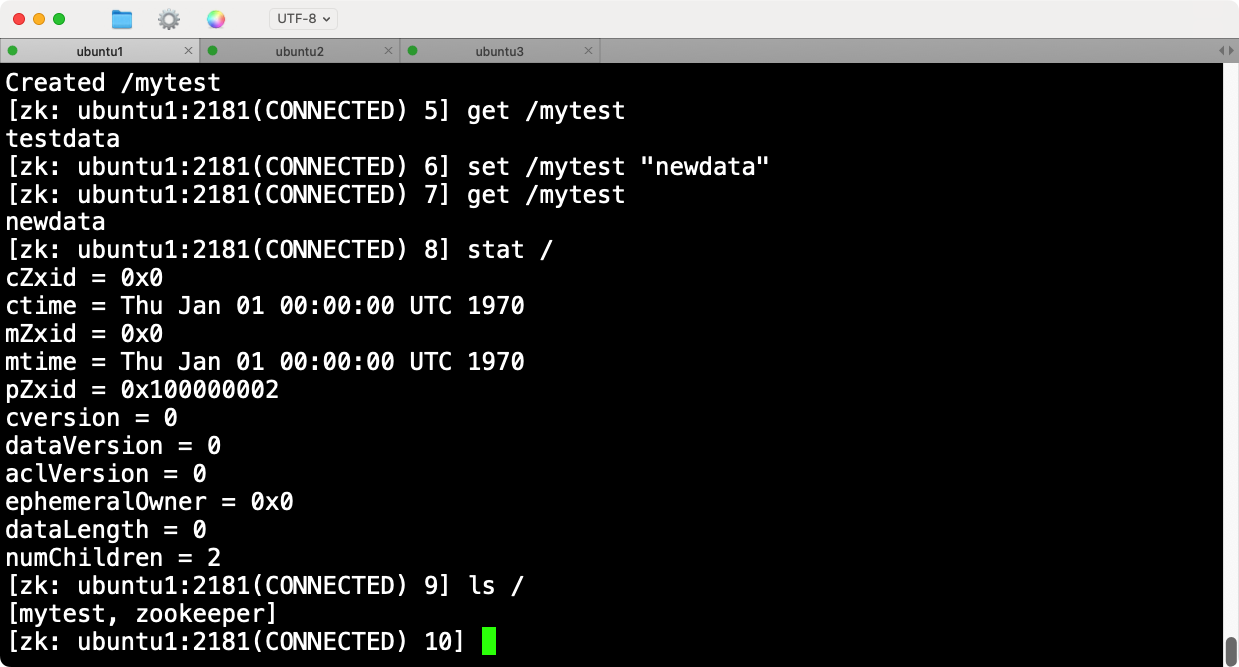
在ZooKeeper命令行客户端中,可以输入以下命令来检查集群状态:
ls /
stat
复制代码
创建一个新的节点:
create /mytest "testdata"
复制代码
验证节点创建:
ls /
复制代码
删除节点:
delete /mytest
复制代码
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4