


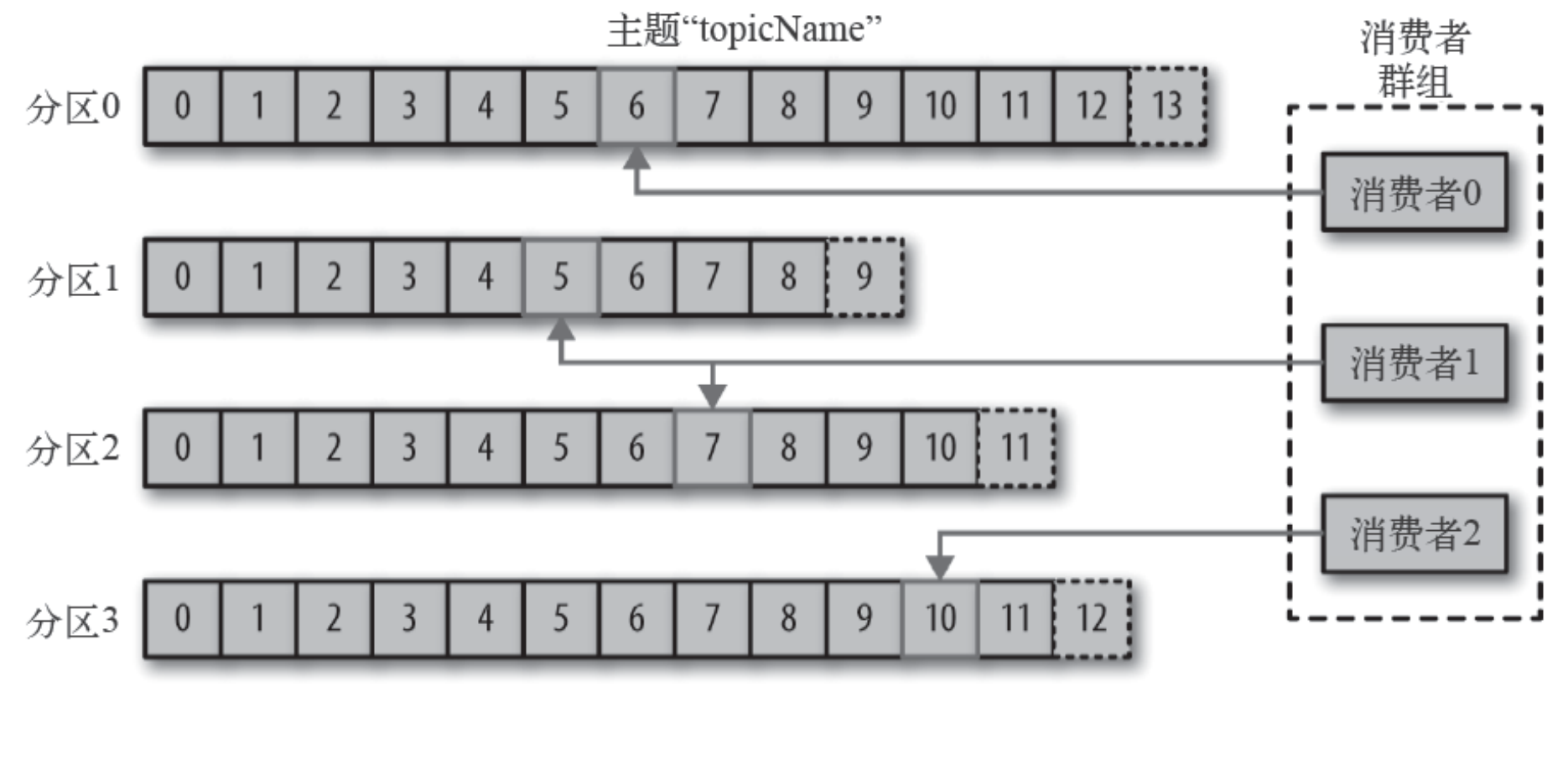



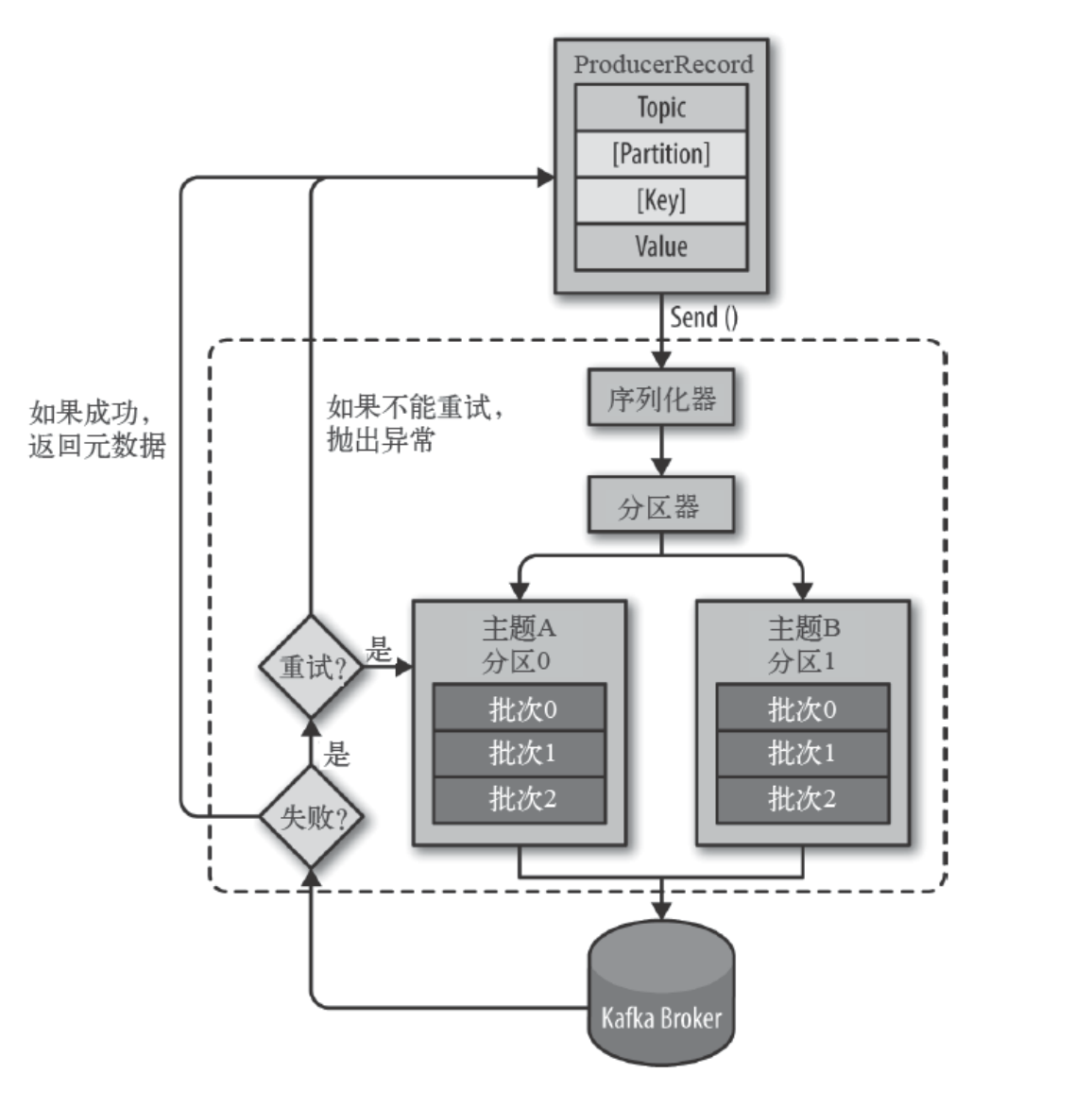



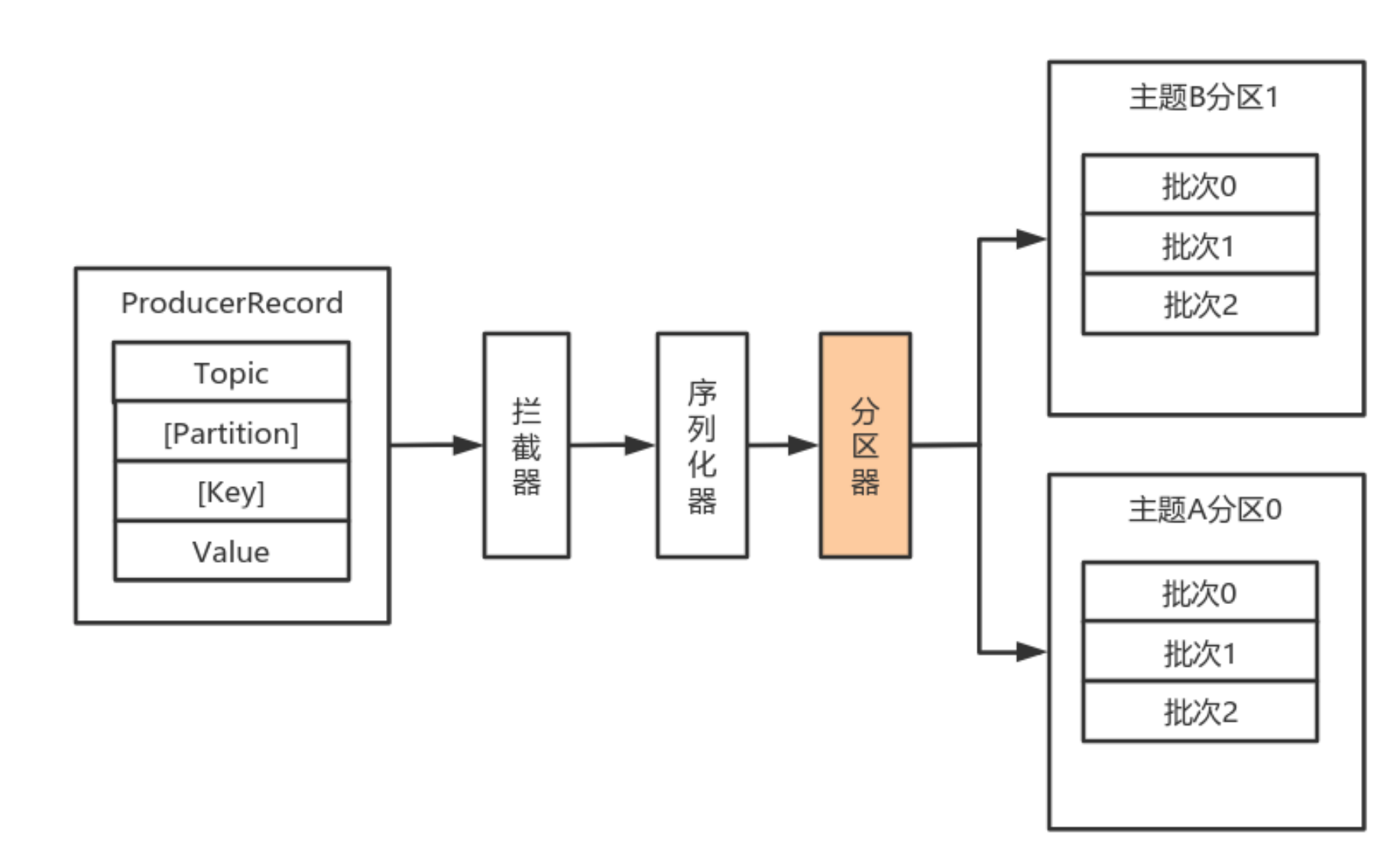


 roducerBatch> 类型的双端队列。roducerBatch> 的形式, Node 表示集群的broker节点。roducerBatch>转化为<Node, Request>形式,此时才可以向服务端发送数据。
roducerBatch> 类型的双端队列。roducerBatch> 的形式, Node 表示集群的broker节点。roducerBatch>转化为<Node, Request>形式,此时才可以向服务端发送数据。
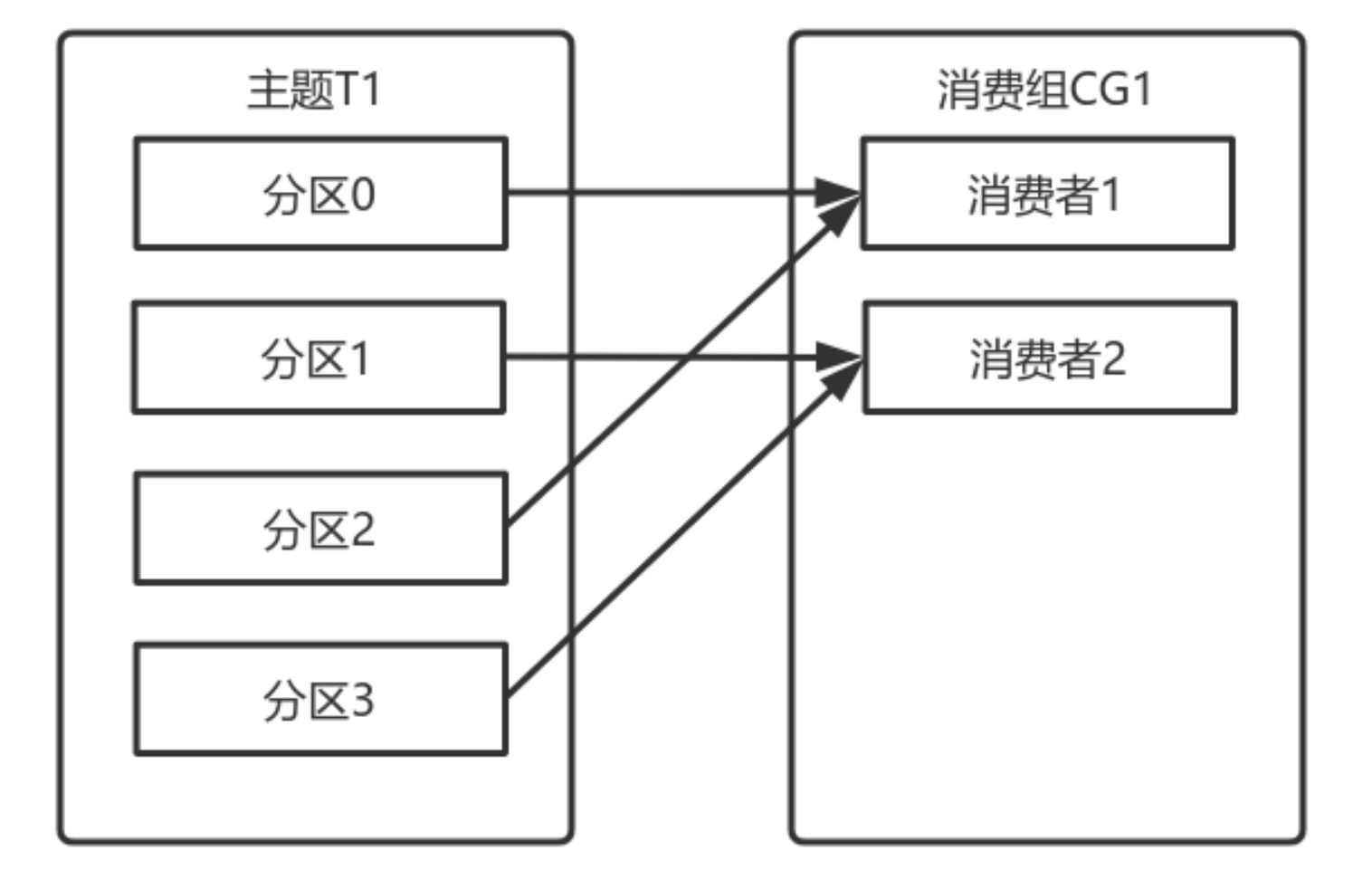



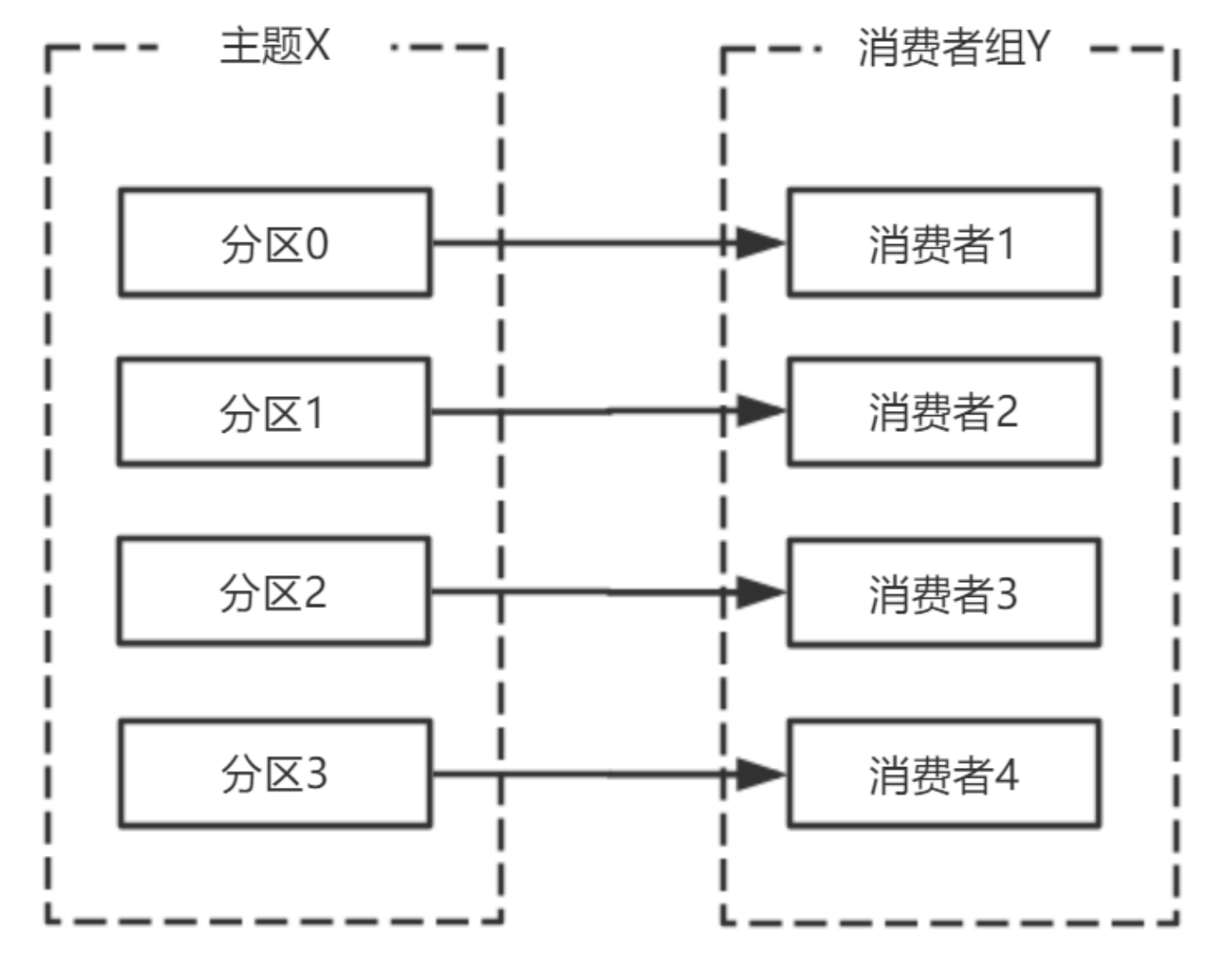


 artitionInfo>> listTopics():artitionInfo> partitionsFor(String topic):
artitionInfo>> listTopics():artitionInfo> partitionsFor(String topic):



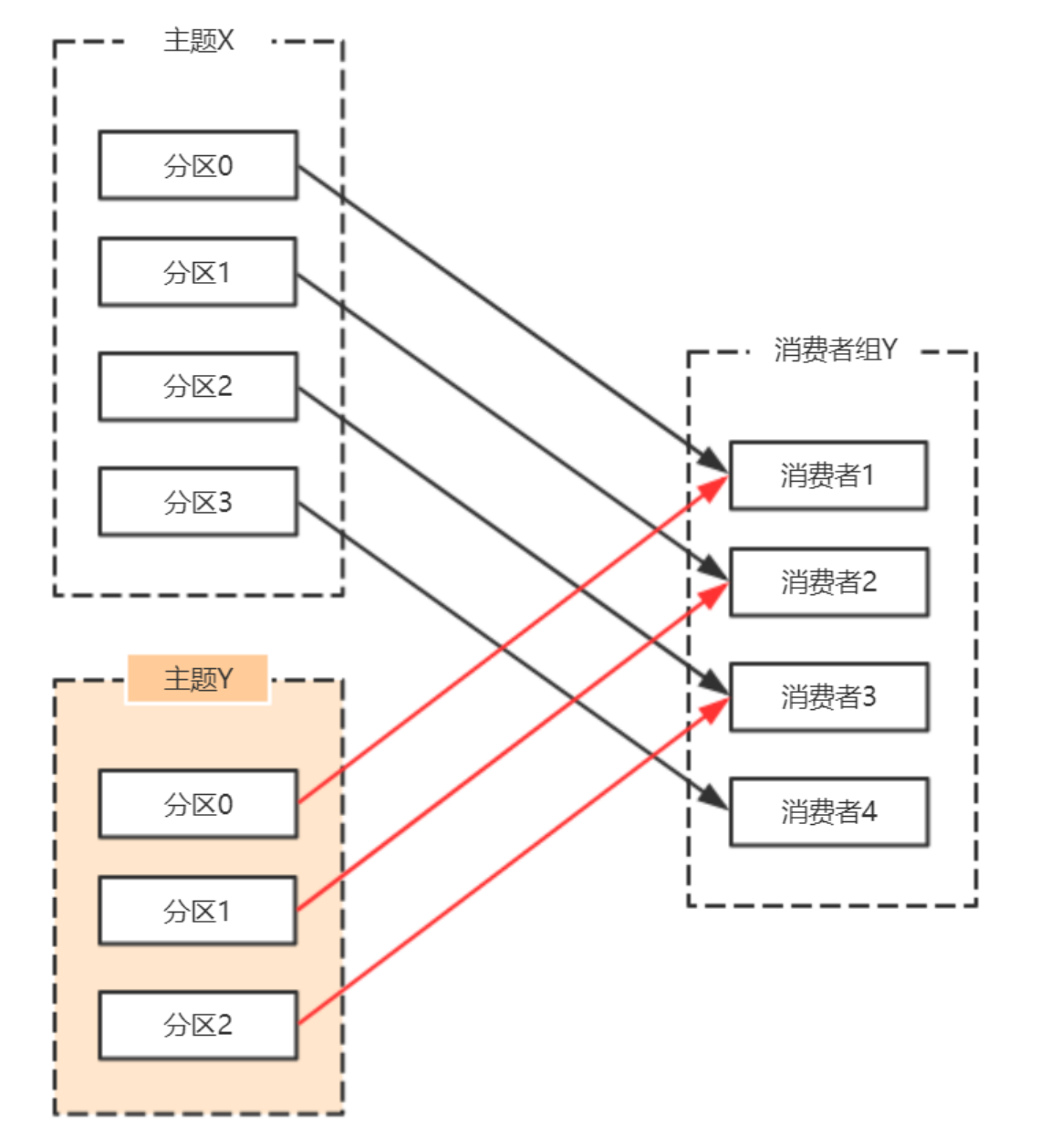



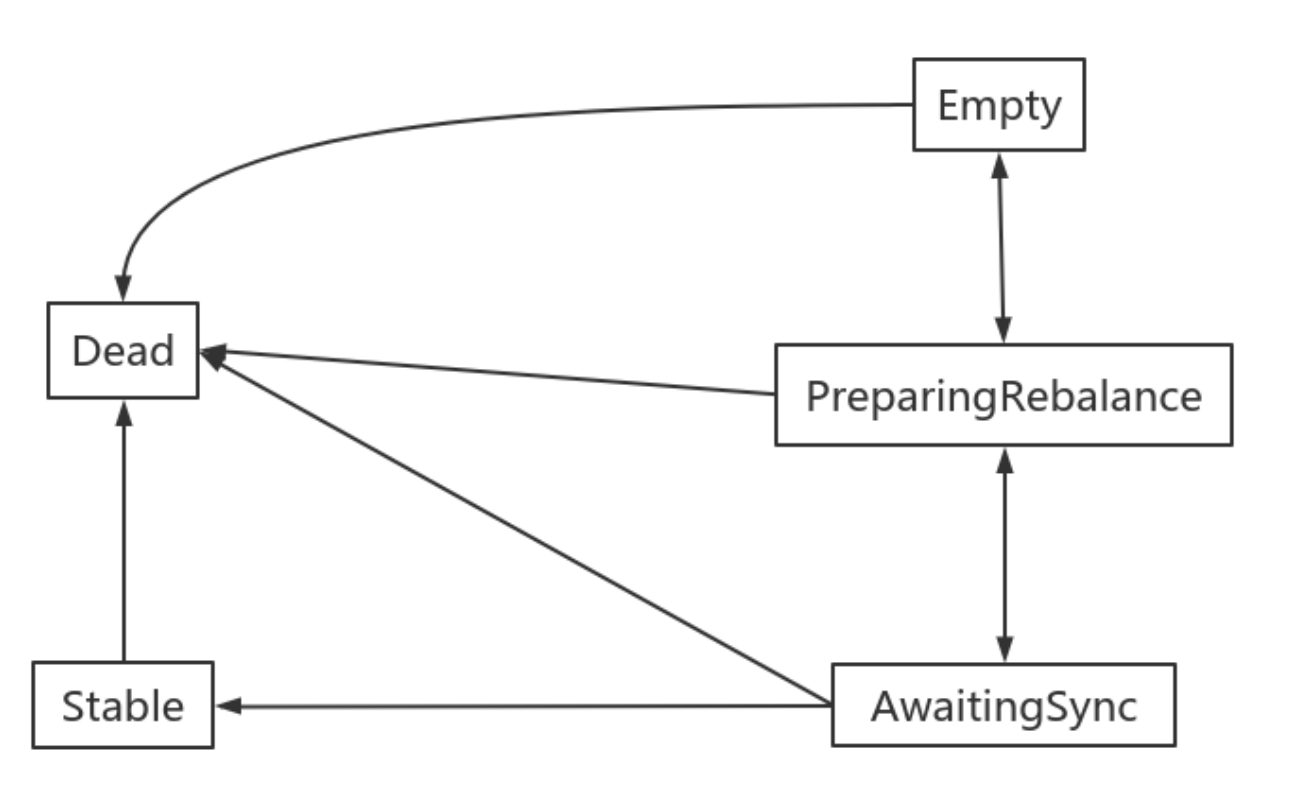



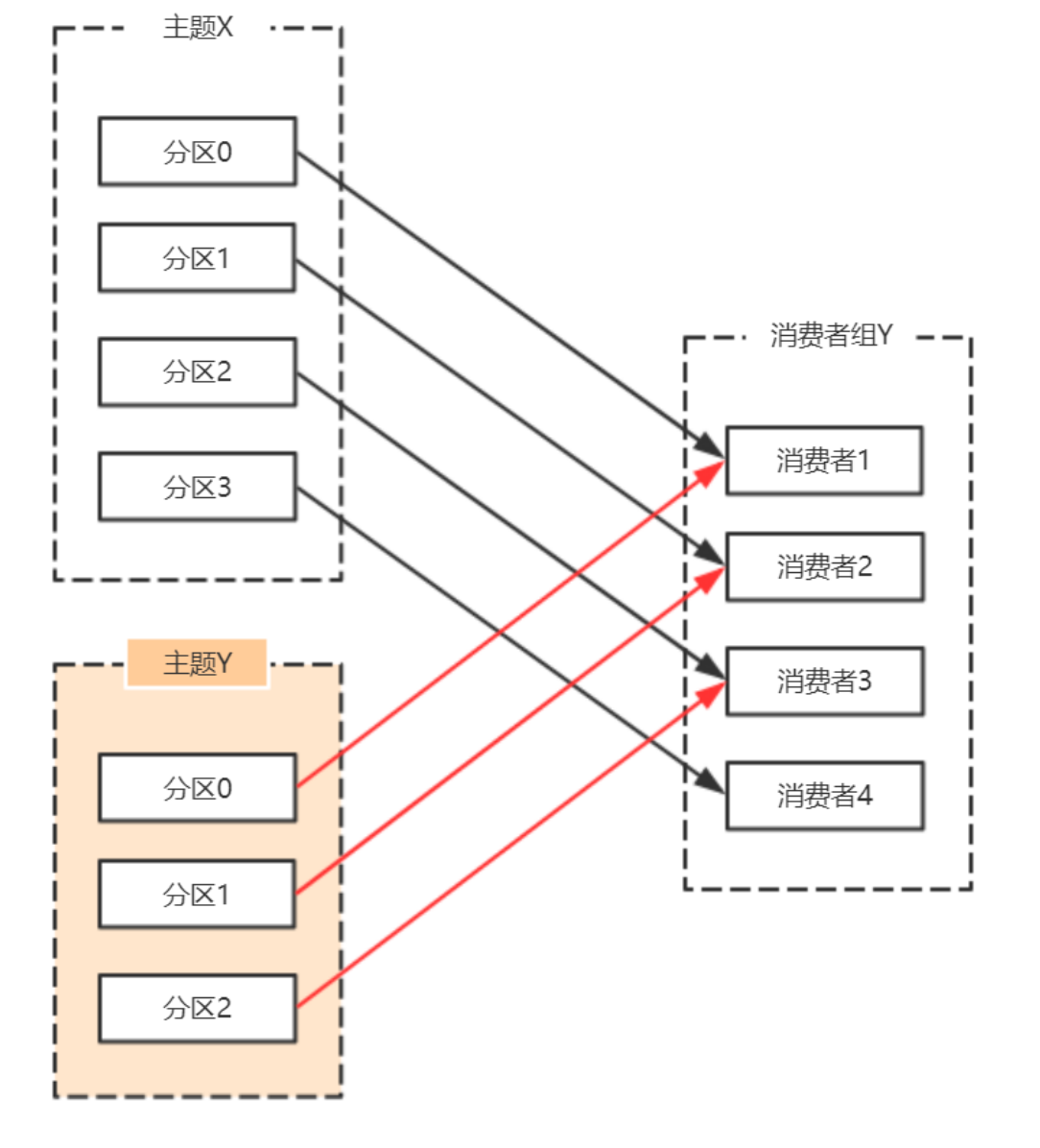



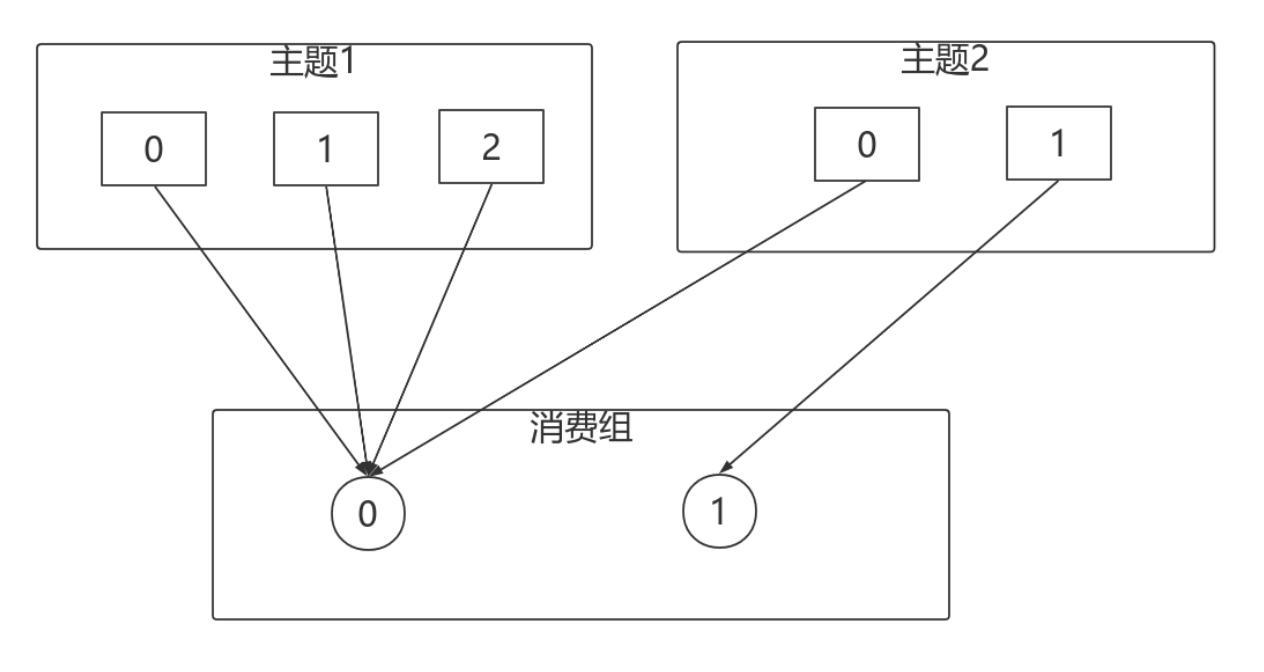



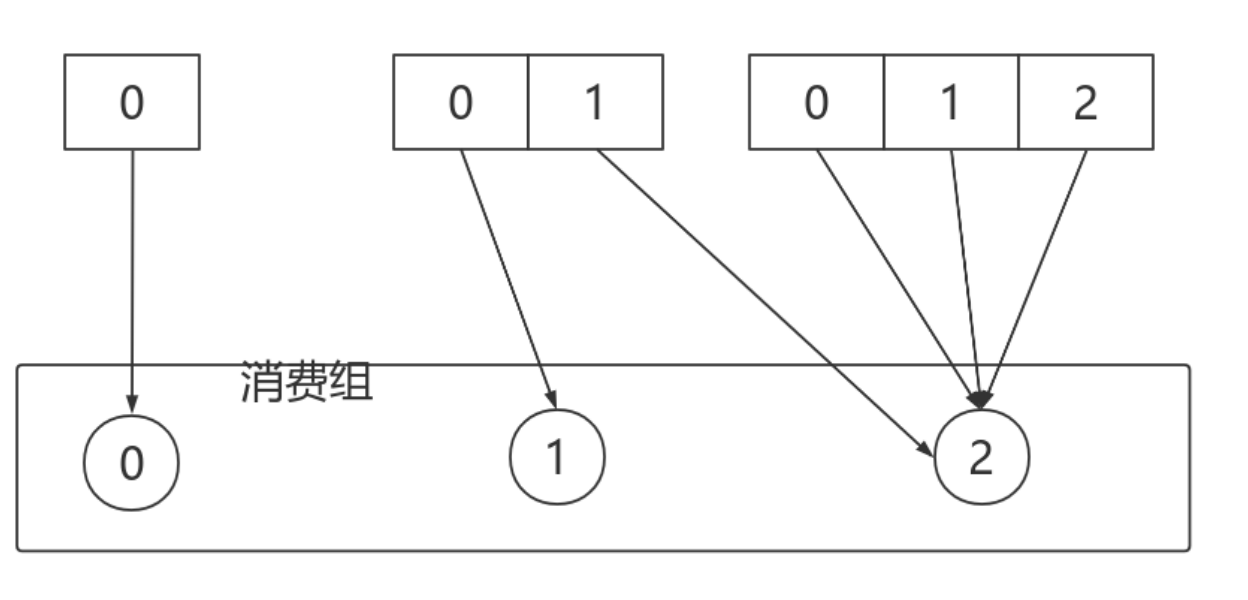







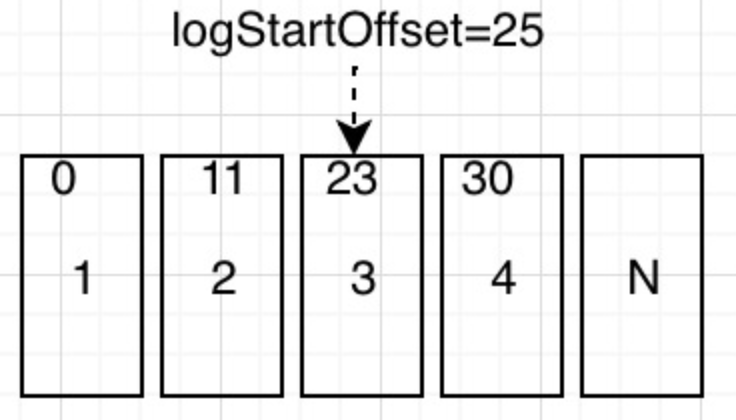






 roducer模式,这种场景是⼀般Kafka项⽬中⽐较常⻅的模式,必要事务介⼊;
roducer模式,这种场景是⼀般Kafka项⽬中⽐较常⻅的模式,必要事务介⼊;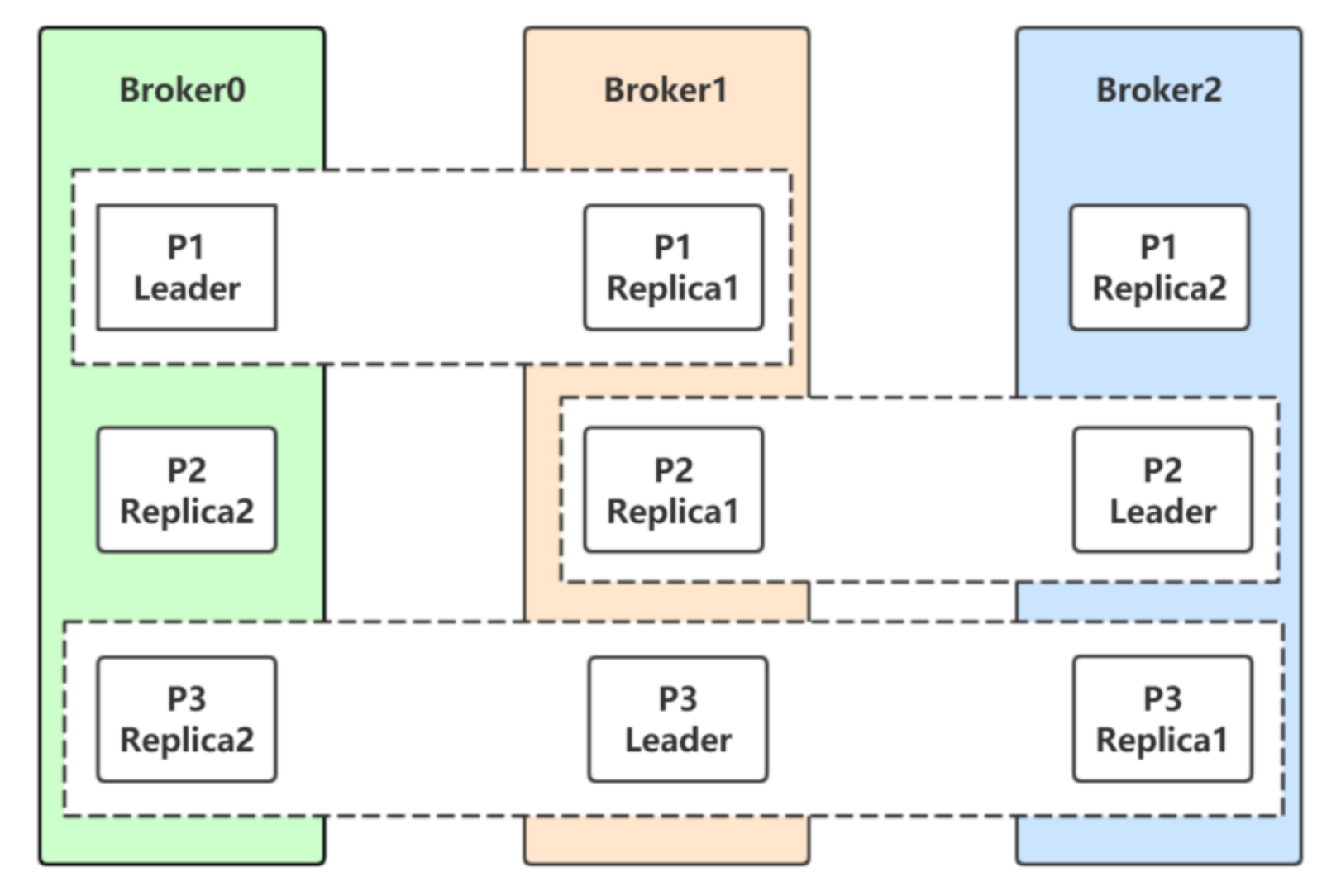



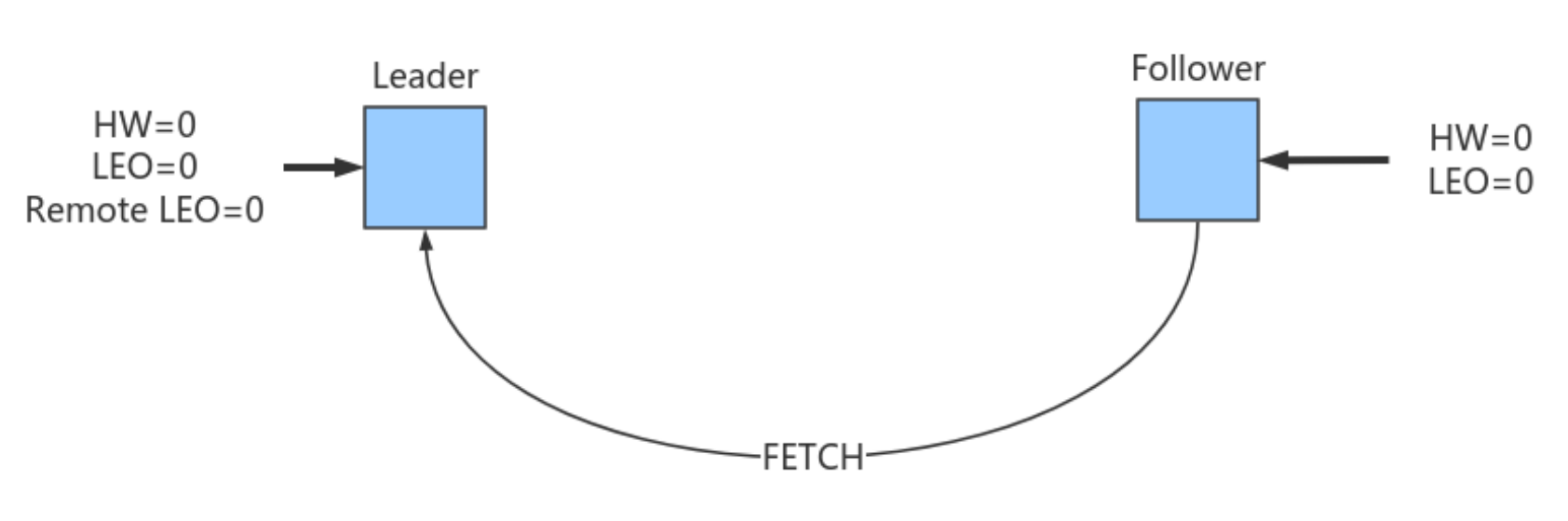



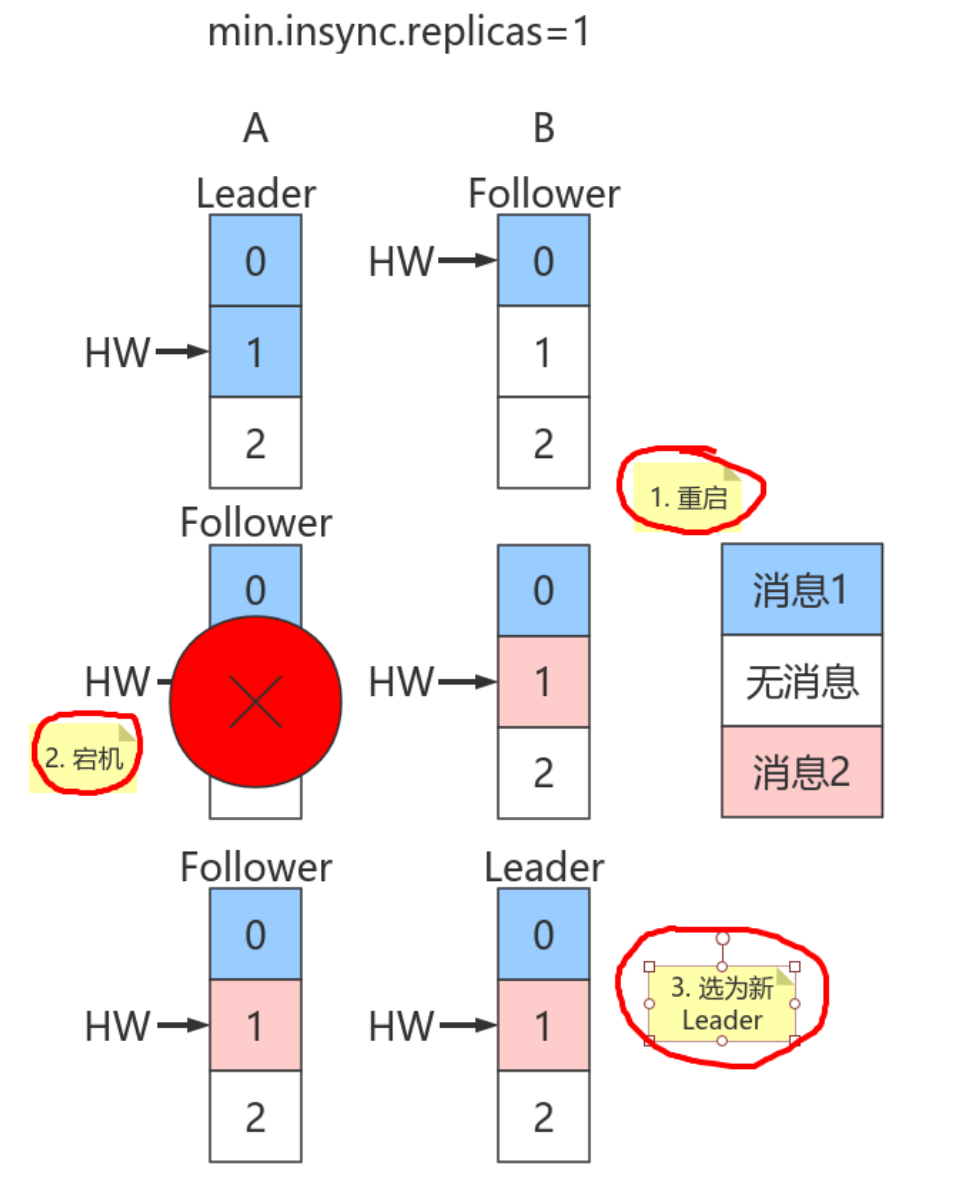









| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |