IT评测·应用市场-qidao123.com
标题:
使用 Llama-Index、Llama 3 和 Qdrant 构建高级重排-RAG 系统
[打印本页]
作者:
石小疯
时间:
2024-8-8 11:21
标题:
使用 Llama-Index、Llama 3 和 Qdrant 构建高级重排-RAG 系统
原文:Plaban Nayak Build an Advanced Reranking-RAG System Using Llama-Index, Llama 3 and Qdrant
引言
只管 LLM(语言模子)可以或许生成有意义且语法正确的文本,但它们面临着一种称为幻觉的挑战。LLM 中的幻觉指的是它们倾向于自信地产生错误答案,从而产生虚假信息,这些信息可能看起来令人佩服。这个问题自 LLM 问世以来就一直存在,而且常常导致不准确和事实错误的输出。
为了办理幻觉问题,事实查抄至关重要。一种用于原型计划 LLM 用于事实查抄的方法包罗三种方法:
提示工程
检索加强生成(RAG)
微调
在这个配景下,我们将使用 RAG(检索加强生成)来减轻幻觉问题。
什么是 RAG?
RAG = 密集向量检索(R)+ 上下文学习(AG)
检索:为所提问的问题找到参考文献。
加强:将参考文献添加到提示中。
生成:改进所提问的答案。
在 RAG 中,我们通过将一系列文本文档或文档片断编码为称为向量嵌入的数值表现来处理惩罚它们。每个向量嵌入对应于一个单独的文档片断,并存储在称为向量存储的数据库中。负责将这些片断编码为嵌入的模子称为编码模子或双编码器。这些模子在大量数据集上进行练习,使它们可以或许创建出单个向量嵌入中文档片断的强大表现。为了避免幻觉,RAG 使用与 LLM 的推理能力分开的事实知识来源。这些知识被外部存储,而且可以轻松访问和更新。
有两种范例的知识来源:
参数化知识:这种知识在练习过程中获得,而且隐式地存储在神经网络的权重中。
非参数化知识:这种范例的知识存储在外部源中,比方向量数据库。
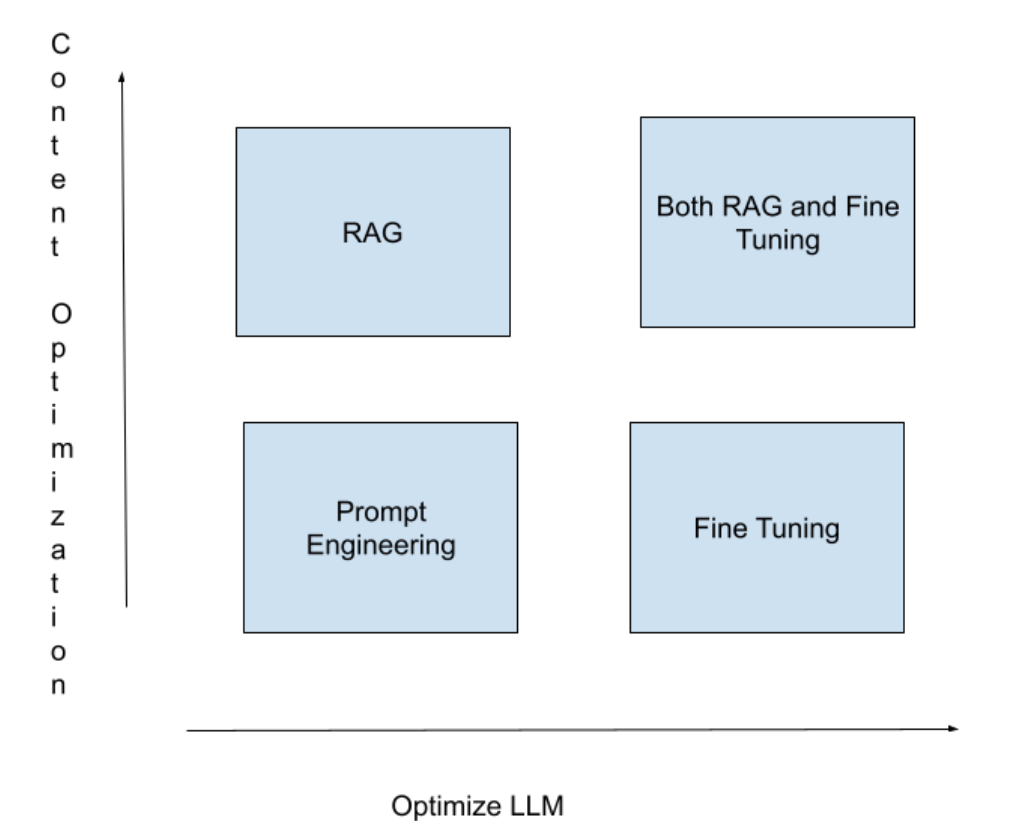
为什么在微调之前使用 RAG(操作顺序)?
便宜:无需额外的练习。
更容易更新最新信息。
更可信,因为可以进行事实查抄的参考文献。
优化工作流程总结了基于以下两个因素可以使用的方法:
内容优化:模子必要了解什么。
LLM 优化:模子必要如何行动。
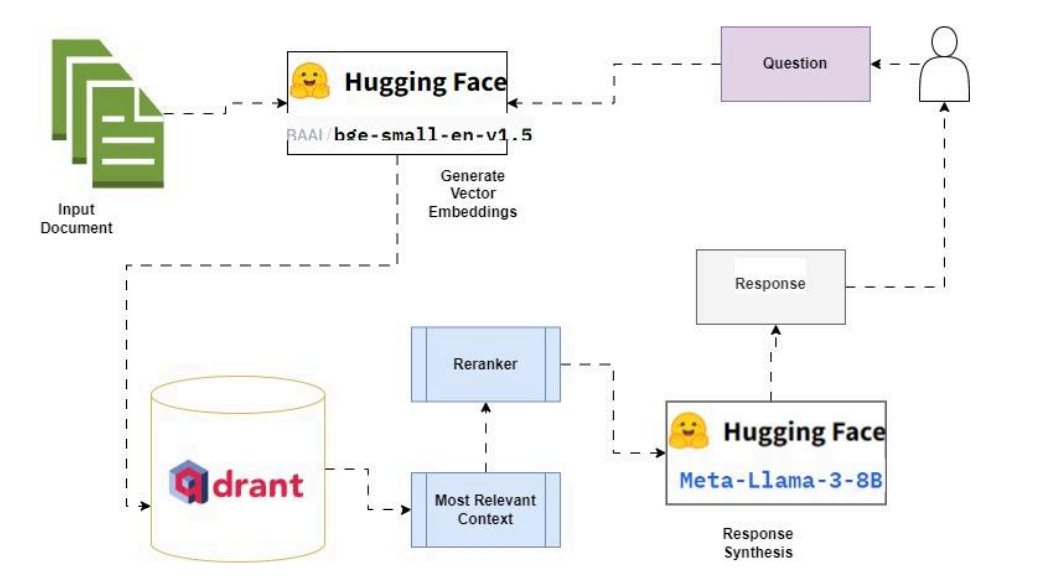
RAG 数据堆栈
欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/)
Powered by Discuz! X3.4