比起直接暴露所有数据,可以要求用户登录或提供 API 密钥才气访问特定数据。还可以为关键内容设置身份验证机制,比如使用 OAuth 2.0 或 JWT(JSON Web Tokens),确保只有授权用户能够访问敏感数据,有效阻止未经授权的爬虫获取数据。
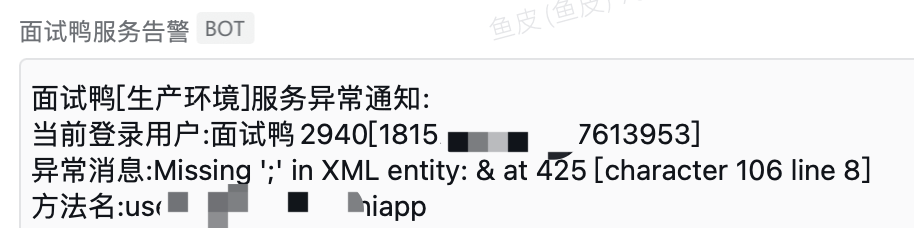
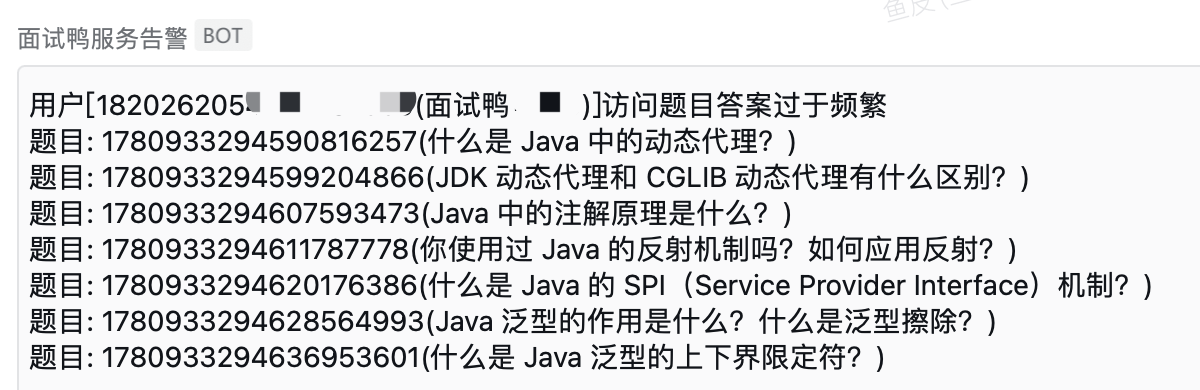
3、统计访问频率和封禁
可以使用缓存工具如 Redis 分布式缓存或 Caffeine 本地缓存来记录每个 IP 或客户端的请求次数,并设置阈值限制单个 IP 所在的访问频率。当检测到异常流量时,体系可以自动封禁该 IP 所在,或者采取其他的策略。
需要注意的是,固然 Map 也能够统计请求频率,但是由于请求是不断累加的,占用的内存也会持续增长,所以不建议使用 Map 这种无法自动开释资源的数据结构。如果肯定要使用内存进行请求频率统计,可以使用 Caffeine 这种具有数据镌汰机制的缓存技术。
4、多级处理策略
为了防止 “误伤”,比起直接对非法爬虫的客户端进行封号,可以设定一个更灵活的多级处理策略来应对爬虫。比如,当检测到异常流量时,先发出告诫;如果爬虫行为继承存在,则采取更严肃的步伐,如暂时封禁 IP 所在;如果解封后继承爬虫,再进行永久封禁等处罚。
具体的处理策略可以根据实际情况来定制,也不建议搞的太复杂,别因此加重了体系的负担。