ToB企服应用市场:ToB评测及商务社交产业平台
标题:
一篇文章带你学会向量数据库Milvus(一)
[打印本页]
作者:
张春
时间:
2024-8-12 12:11
标题:
一篇文章带你学会向量数据库Milvus(一)
上一篇文章中 LLM 学习之「向量数据库」 中我们先容了什么是向量数据库,向量数据库有那些用途,向量数据库与 LLM 的关联以及 RAG 中向量数据库的利用。本篇文章我们重点先容 Milvus 向量数据库的知识和利用。
Milvus 简介:
向量数据库是一种专用体系,旨在通过向量嵌入和数值表示来管理和检索非布局化数据,这些数据项捕捉图像、音频、视频和文本内容等数据项的本质。与利用准确搜索利用处置惩罚布局化数据的传统关系数据库不同,向量数据库在利用近似最近邻 (ANN) 算法等技能进行语义相似性搜索方面体现出色。此功能对于开发跨各个领域的应用程序(包括推荐体系、聊天机器人和多媒体内容搜索工具)以及办理 AI 和 ChatGPT 等大型语言模型带来的挑战至关重要,例如理解上下文和渺小差异以及 AI 幻觉。
像 Milvus 如许的向量数据库的出现正在改变行业,它支持对大量非布局化数据进行基于内容的搜索,超越了人工生成标签的限制。使向量数据库与众不同的主要功能包括
可扩展性和可调性,可处置惩罚不断增长的数据量
多租户和数据隔离,实现高效的资源利用和隐私保护
适用于各种编程语言的一整套 API
用户友好的界面,简化了与复杂数据的交互。
这些属性确保了矢量数据库能够满足现代应用程序的需求,为探索和利用非布局化数据提供了强大的工具,这是传统数据库无法做到的。
数据库管理
与传统数据库引擎类似,您也可以在 Milvus 中创建数据库,并为某些用户分配权限来管理它们。那么这些用户就有权管理数据库中的集合。一个 Milvus 集群最多支持 64 个数据库。
创建数据库
要创建数据库,您须要起首连接到 Milvus 集群并为其预备一个名称:
ini复制代码 from pymilvus import connections, db # type: ignore
_HOST = '127.0.0.1'
_PORT = 19530
_db_name = "default"
_user = "root"
_passwd = "Milvus"
_role_demo = "public"
_user_demo= "demo"
_passwd_demo = "demodemo1"
connections.connect(host=_HOST, port=_PORT, db_name=_db_name, user=_user_demo, password=_passwd_demo)
复制代码
删除数据库
python复制代码 def drop_database(name: str) -> any:
return db.drop_database(name)
# 创建数据库
def create_database(name: str) -> any:
database = db.create_database(name)
return database
# 切换数据库
def use_database(name: str) -> any:
return db.using_database(name)
# 列出数据库
def list_databases() -> list[str]:
return db.list_database()
复制代码
列出数据库
scss复制代码 print(list_databases())
databases = list_databases()
print(databases)
## 删除数据库
drop_database("demo_v1")
drop_database("demo_v1")
databases = list_databases()
print(databases)
create_database('demo_v1')
databases = list_databases()
print(databases)
复制代码
Milvus 中的 schema, schema 用于界说集合的属性及此中的字段。
Field schema
Field schema 是字段的逻辑界说。我们在界说集合架构和管理集合之前须要界说的第一件事就是界说 Field schema。
Milvus 集合中仅支持一个主键字段。
Field schema properties
属性描述备注name要创建的集合中的字段名称String,必填dtype字段的数据类型必填description字段描述String,选填is_primary是否设置该字段为主键字段Boolean (true or false) 主键字段必填auto_id(主键字段必填)切换以启用或禁用自动 ID(主键)分配True或Falsemax_length(VARCHAR 字段必需)允许插入的字符串的最大长度。[1, 65,535]dim向量的维数∈[1, 32768]is_partition_key该字段是否是分区键字段布尔值(true 或 false)
创建 field schema
Milvus 允许我们在创建字段 schema 时为每个标量字段指定默认值,从而减低插入数据的复杂性,但不包括主键字段。如果在插入数据时将字段留空,则将应用为此字段指定的默认值。
创建通例字段 schema:
ini复制代码 from pymilvus import FieldSchema, DataType
# 创建一个名为id 的 primary id
id_field = FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, description='primary key')
age_field = FieldSchema(name='age', dtype=DataType.INT64, description='age')
embedding_field = FieldSchema(name='embedding',dtype=DataType.FLOAT_VECTOR, dim=128, description='vector')
# 使用 position 作为分区键
position_field = FieldSchema(name='position', dtype=DataType.VARCHAR, max_length=256,is_partition_key=True)
复制代码
创建具有默认字段值的 schema
ini复制代码 from pymilvus import FieldSchema, DataType
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True),
FieldSchema(name='age', dtype=DataType.INT64, default_value=25,description='age'),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=128, description='vector')
];
复制代码
collection schema
collection schema 是 collection 的逻辑界说。我们须要在界说 collection schema 之前界说 field schema。
Collection schema 属性
属性描述备注field集合中要创建的字段必填description集合描述String,选填partition_key_field设计用作分区键的字段的名称。String, 选填enable_dynamic_field是否启用动态模式Boolean (true or false)
ini复制代码 from pymilvus import FieldSchema, CollectionSchema
id_field = FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, description='primary id')
age_field = FieldSchema(name='age', dtype=DataType.INT64, description='age'),
embedding_field = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=128,description='vector')
# 启用分区字段
position_field = FieldSchema(name='position', dtype=DataType.VARCHAR, max_length=256, is_partition=True)
# 如果需要使用动态字段,请将 enable_dynamic_field 设置为 True。
schema = CollectionSchema(fields=[id_field, age_field, embedding_field],
auto_id=False, enable_dynamic_field=True, description='desc of a collection')
ini复制代码 from pymilvus import Collection
collection_name1 = 'demo_v2'
collection1 = Collection(name=collection_name1, schema=schema, using='default', shards_num=2)
复制代码
参数剖析:
我们利用 shard_num 自界说分片编号
我们通过参数 using 来指定别名界说要在其上创建集合的 Milvus 服务器。
如果我们须要实现基于分区上面的多租户,可以通过在字段上面将 is_partition_key设置为True来启用该字段的分区键功能。
如果须要启用动态字段,可以通过在集合架构中将 enable_dynamic_field 设置为True 来启用动态架构。
Milvus 集合管理
本教程之前你须要先安装 Milvus 服务。你可以安装单机版大概集群版。详细教程可以参考 Milvus 官方文档。
在 Milvus 中,我们将向量嵌入存储在集合中。集合中的所有向量嵌入共享雷同的维度和间隔度量来测量相似性。
Milvus 集合支持动态字段(即 schema 中未预界说的字段)和主键自动递增。
为了适应不同的人的习惯,Milvus 提供了两种创建集合的方法。一种提供快速设置,另一种则允许对集合架构和索引参数进行详细定制。
创建 collection
我们可以通过下面的两种方式创建 collection 。
通过官方包 MilvusClient 创建。
定制设置,也就是上面文档的部分。
下面我们利用第一种方式创建 collection
在人工智能行业大跃进的背景下,大多数开发者只须要一个简单而动态的集合来开始。 Milvus 允许仅利用三个参数快速设置如许的集合:
要创建的集合的名称
要插入的向量嵌入的维度
用于测量向量嵌入之间相似性的度量类型
示例代码:
ini复制代码 # 导入相关的 python 包
from pymilvus import MilvusClient, DataType
# 连接服务,初始化 MilvusClient
client = MilvusClient(
uri="http://localhost:19530"
)
# 创建一个 collection
client.create_collection(
collection_name="demo_v2",
dimension=5
)
# 获取 collection 的状态
res = client.get_load_state(
collection_name="demo_v2"
)
print(res)
复制代码
利用上面的代码设置的 collection 只包括两个字段. id 作为主键, vector 作为向量字段,以及自动设置 auto_id、enable_dynamic_field 为 True
auto_id 启用此设置可确保主键自动递增。在数据插入期间无需手动提供主键。
enable_dynamic_field 启用后,要插入的数据中除 id 和 vector 之外的所有字段都将被视为动态字段。这些附加字段作为键值对保存在名为 $meta 的特殊字段中。此功能允许在数据插入期间包含额外的字段。
自界说设置
我们可以自行确定集合的架构和索引参数,而不是让 Milvus 决定您集合的险些所有内容。而且如果我们体系中重度利用了 Milvus 的情况下,建议利用定制设置.
设置 schema
在 schema 中,我们可以选择启用大概禁用 enable_dynamic_field,添加预定一字段以及为每个字段设置属性。
ini复制代码 schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
schema.add_field(field_name="my_id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="my_vector", datatype=DataType.FLOAT_VECTOR, dim=5)
复制代码
代码片断中,enable_dynamic_field 设置为 True,并为主键启用 auto_id。此外,还引入了一个vector字段,其维度设置为5,并包含四个标量字段,每个标量字段都有其各自的属性。
设置索引参数
索引参数决定 Milvus 怎样组织集合中的数据。我们可以通过调解特定字段的 metric_type 和 index_type 来设置特定字段的索引过程。对于矢量,可以机动选择COSINE、L2或IP作为metric_type。
ini复制代码 # 创建索引字段
index_params = client.prepare_index_params()
index_params.add_index(
field_name="my_id",
index_type="STL_SORT"
)
index_params.add_index(
field_name="my_vector",
index_type="IVF_FLAT",
metric_type="IP",
params={ "nlist": 128 }
)
复制代码
上面的代码中演示了怎样分别为向量和标量设置索引参数。对于向量字段同时设置度量类型和索引类型。对于标量字段,仅设置索引类型。建议为向量字段和任何经常利用用于过滤器的标量字段创建索引。
创建 collection
我们可以选择分别创建集合和索引文件,大概创建集归并在创建时同时加载索引。
看个例子:
ini复制代码 # 创建集合
client.create_collection(
collection_name="demo_v3",
schema=schema,
index_params=index_params
)
# 因为上面的代码是异步操作,所以这里 sleep 一下。
time.sleep(5)
# 获取集合的状态
res = client.get_load_state(
collection_name="customized_setup_1"
)
复制代码
检察集合
创建完集合后我们可以去检索集合,看下面的示例:
ini复制代码 # 查询集合详情
res = client.describe_collection(
collection_name="demo_v3"
)
print(res)
复制代码
如果要检察现有有哪些集合可以利用下面的代码检察:
ini复制代码 # 列出所有集合名称
res = client.list_collections()
print(res)
复制代码
加载和开释集合
在集合加载过程中,Milvus 会将集合的索引文件加载到内存中,当开释集适时,Milvus 会从内存中卸载索引文件。在集合进行搜索之前,我们须要确保集合已加载。
加载集合
ini复制代码 # 加载集合代码
client.load_collection(
collection_name="demo_v3"
)
res = client.get_load_state(
collection_name="demo_v3"
)
复制代码
发布集合
ini复制代码 # 发布一个集合
client.release_collection(
collection_name="demo_v3"
)
res = client.get_load_state(
collection_name="demo_v3"
)
复制代码
设置集合别名
我们可以为集合分配别名,以使它们在特定上下文中更故意义。可以为一个集合指定多个别名,但多个集合不能共享一个别名
创建别名
ini复制代码 # 创建别名
client.create_alias(
collection_name="demo_v3",
alias="dv3"
)
client.create_alias(
collection_name="demo_v2",
alias="dv2"
)
复制代码
列出别名
shell复制代码 res = client.list_aliases(
collection_name="demo_v2"
)
# Output
#
# {
# "aliases": [
# "dv3",
# "alice"
# ],
# "collection_name": "demo_v3",
# "db_name": "default"
# }
复制代码
我们还可以为别名设置描述, 重新分配别名,删除别名。
删除集合
如果我们不再须要某个集合,可以删除该集合。
ini复制代码 client.drop_collection(
collection_name="demo_v3"
)
client.drop_collection(
collection_name="demo_v2"
)
复制代码
总结
本文主要是先容了目前很火的向量数据库 Milvus 的干系知识,包括:
Milvus 是什么,能做什么。
Milvus 数据库管理(添加,删除,查询列表, 字段)
Milvus 集合管理
创建集合包括两种方式(默认方式和自界说的方式)
检察集合
集合加载和开释
资源分享
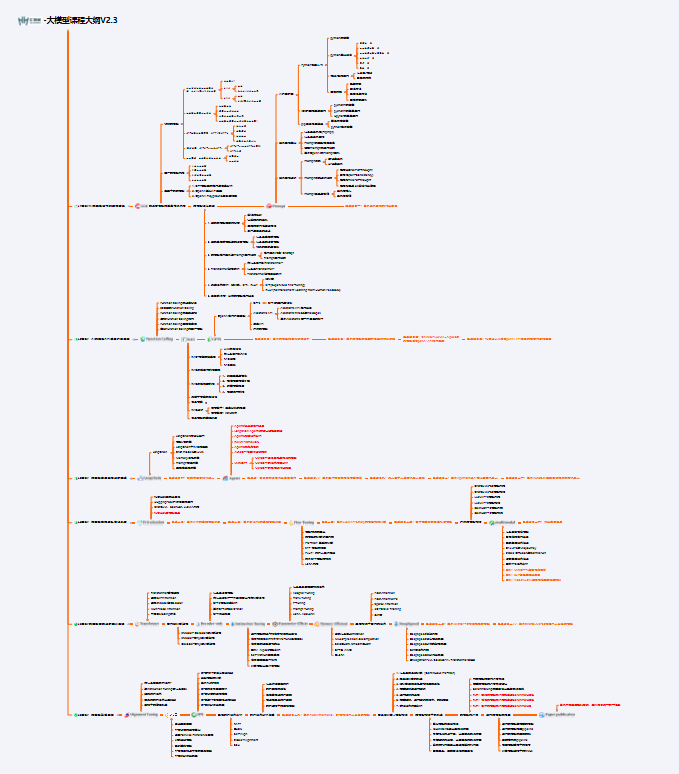
大模型AGI学习包
资料目次
成长路线图&学习规划
配套视频教程
实战LLM
人工智能比赛资料
AI人工智能必读书单
面试题合集
《
人工智能\大模型入门学习大礼包
》,可以
扫描下方二维码免费领取
!
1.成长路线图&学习规划
要学习一门新的技能,作为新手一定要
先学习成长路线图
,
方向不对,积极白费
。
对于从来没有打仗过网络安全的同砚,我们帮你预备了详细的学习成长路线图&学习规划。可以说是最科学最体系的学习路线,各人跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜好
艰涩的文字
,我也为各人预备了视频教程,此中一共有
21个章节
,每个章节都是
当前板块的精华浓缩
。
3.LLM
各人最喜好也是最关心的
LLM(大语言模型)
《
人工智能\大模型入门学习大礼包
》,可以
扫描下方二维码免费领取
!
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4