alter database dept set dbproperties('createtime'='20220531');
复制代码
4.1.4 数据库详细信息
1)表现数据库(show)
show databases;
复制代码
2)可以通过like进行过滤
show databases like 't*';
复制代码
3)检察详情(desc)
desc database testdb;
复制代码
4)切换数据库(use)
use testdb;
复制代码
4.1.5 删除数据库(将删除的目录移动到回收站中)
1)最简写法
drop database testdb;
复制代码
2)假如删除的数据库不存在,最好使用if exists判断数据库是否存在。否则会报错:FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
drop database if exists testdb;
复制代码
3)假如数据库不为空,使用cascade命令进行逼迫删除。报错信息如下FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(messageatabase db_hive is not empty. One or more tables exist.)
Record Columnar的缩写。是Hadoop中第一个列文件格式。能够很好的压缩和快速的查询性能。通常写操作比较慢,比非列形式的文件格式需要更多的内存空间和计算量。 RCFile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据`列式存储`,有利于数据压缩和快速的列存取。
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rnp,
percent_rank() over(partition by subject order by score) as percent_rank
from t_fraction;
复制代码
select name,subject,score,
rank() over(order by score) as row_number,
percent_rank() over(partition by subject order by score) as percent_rank
from t_fraction;
复制代码
实战2:Hive分析学天生绩信息
创建表语加载数据
name subject score
李毅 语文 87
李毅 数学 95
李毅 英语 68
黄仙 语文 94
黄仙 数学 56
黄仙 英语 84
小虎 语文 64
小虎 数学 86
小虎 英语 84
许文客 语文 65
许文客 数学 85
许文客 英语 78
建表加载数据
vim score.txt
create table score2
(
name string,
subject string,
score int
) row format delimited fields terminated by "\t";
load data local inpath '/shujia/bigdata17/xiaohu/data/score.txt' into table score;
复制代码
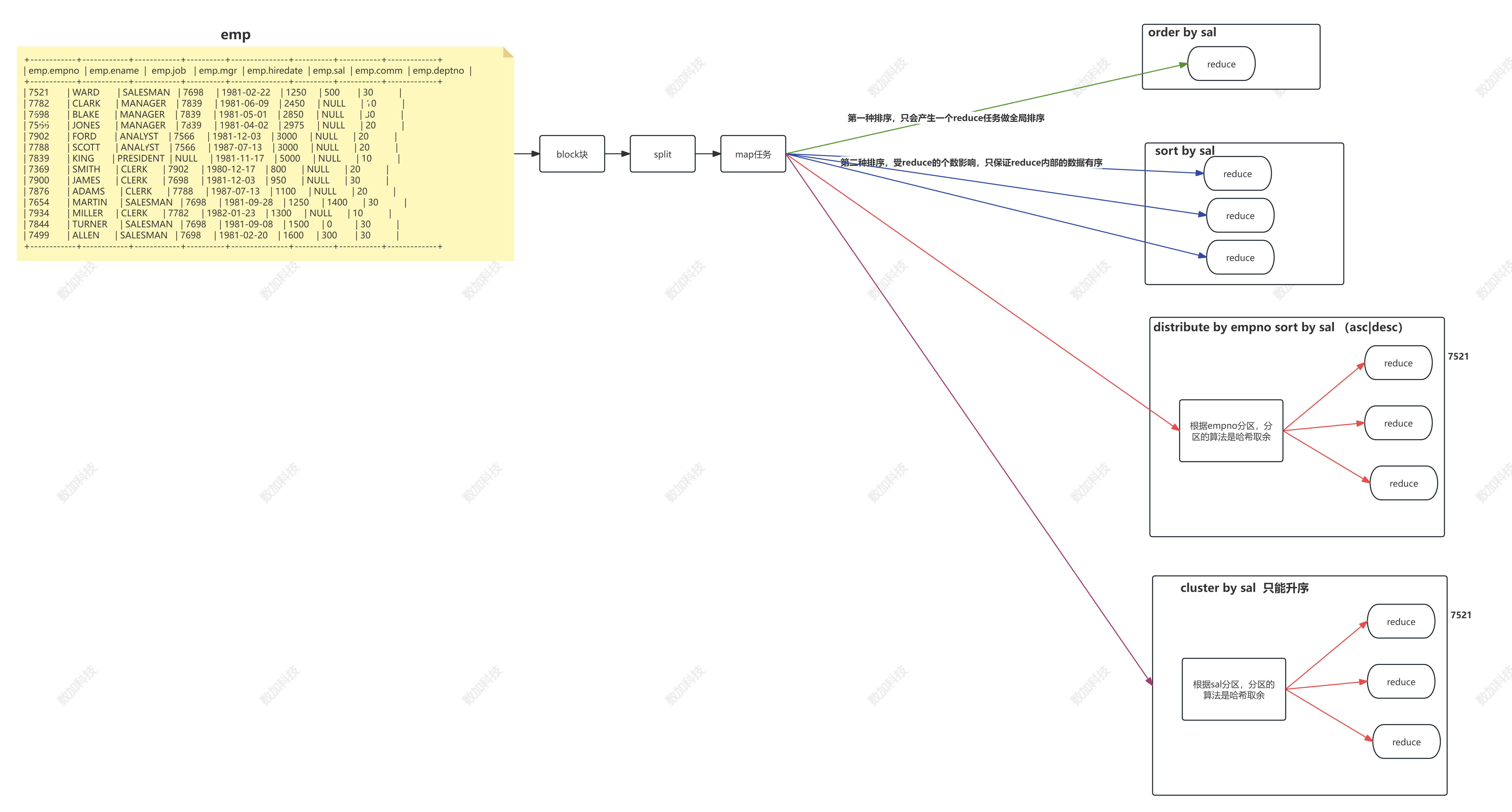
需求1:每门学科学天生绩排名(是否并列排名、空位排名三种实现)
分析:学科分组、成绩降序排序、按照成绩排名
select name,subject,score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from
score;
复制代码
需求2:每门学科成绩排名top 2的学生
select t1.name,t1.subject,t1.score from (select name,subject,score,row_number() over(partition by subject order by score desc) as rn from score2) t1 where t1.rn<3;
复制代码
4、Hive 行转列
lateral view explode
create table testArray2(
name string,
weight array<string>
)row format delimited
fields terminated by '\t'
COLLECTION ITEMS terminated by ',';
小虎 "150","170","180"
火火 "150","180","190"
select name,col1 from testarray2 lateral view explode(weight) t1 as col1;
小虎 150
小虎 170
小虎 180
火火 150
火火 180
火火 190
select key from (select explode(map('key1',1,'key2',2,'key3',3)) as (key,value)) t;
key1
key2
key3
select name,col1,col2 from testarray2 lateral view explode(map('key1',1,'key2',2,'key3',3)) t1 as col1,col2;
小虎 key1 1
小虎 key2 2
小虎 key3 3
火火 key1 1
火火 key2 2
火火 key3 3
select name,pos,col1 from testarray2 lateral view posexplode(weight) t1 as pos,col1;
小虎 0 150
小虎 1 170
小虎 2 180
火火 0 150
火火 1 180
火火 2 190
复制代码
5、Hive 列转行
// testLieToLine
name col1
小虎 150
小虎 170
小虎 180
火火 150
火火 180
火火 190
create table testLieToLine(
name string,
col1 int
)row format delimited
fields terminated by '\t';
select name,collect_list(col1) from testLieToLine group by name;
 atabase db_hive is not empty. One or more tables exist.)
atabase db_hive is not empty. One or more tables exist.)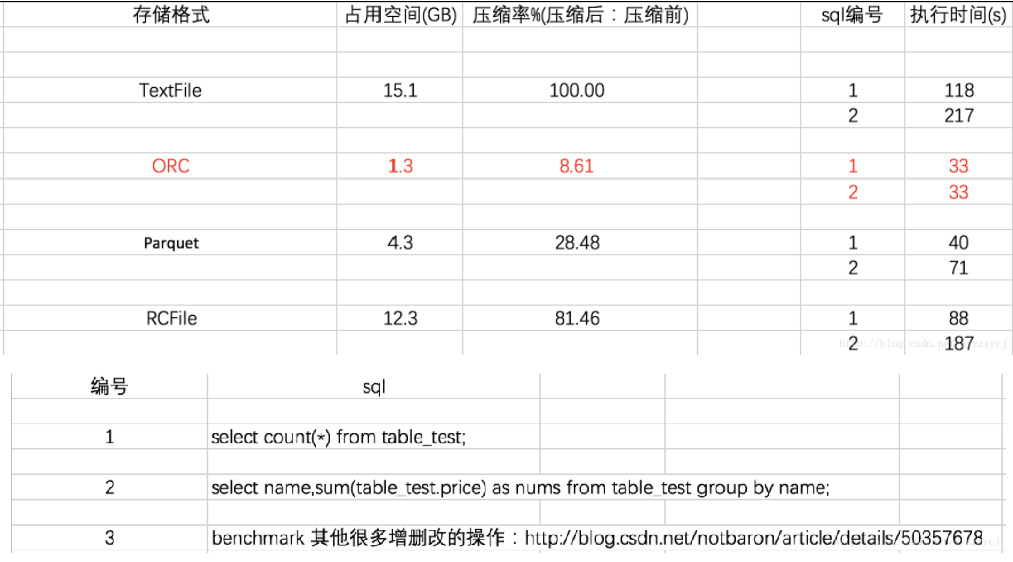

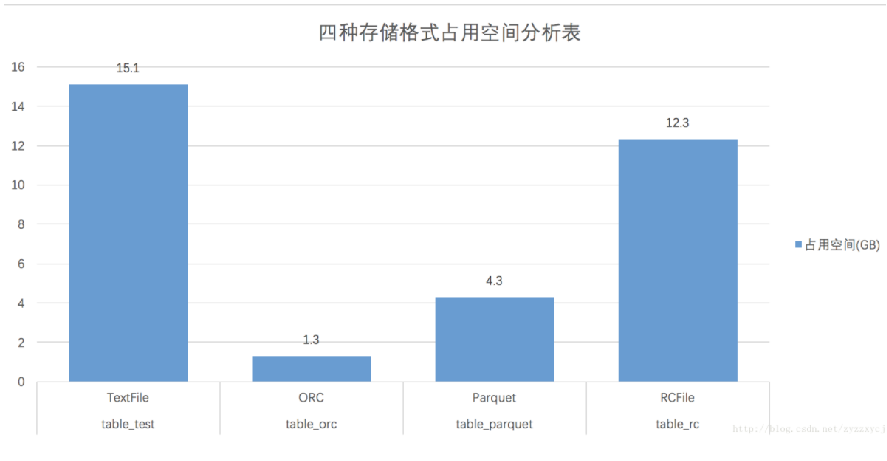
 arquet<RC<Text
arquet<RC<Text