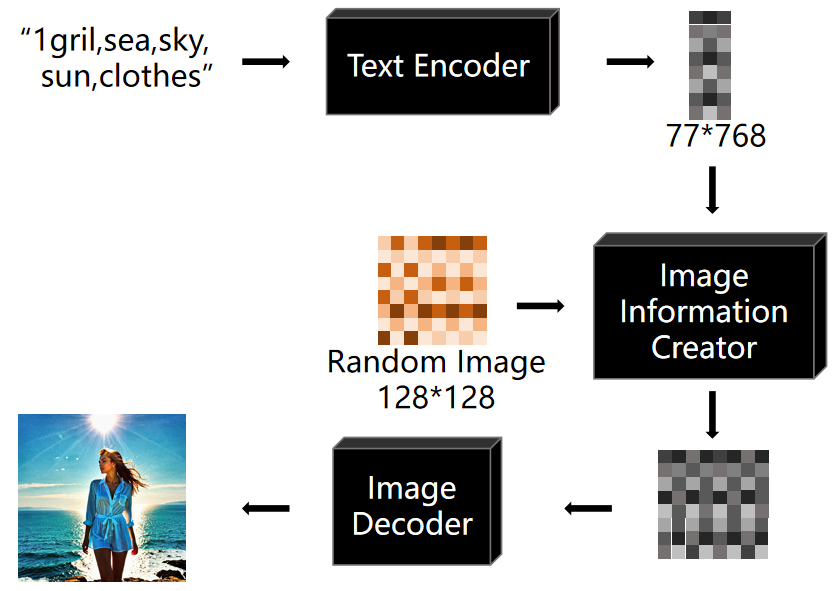
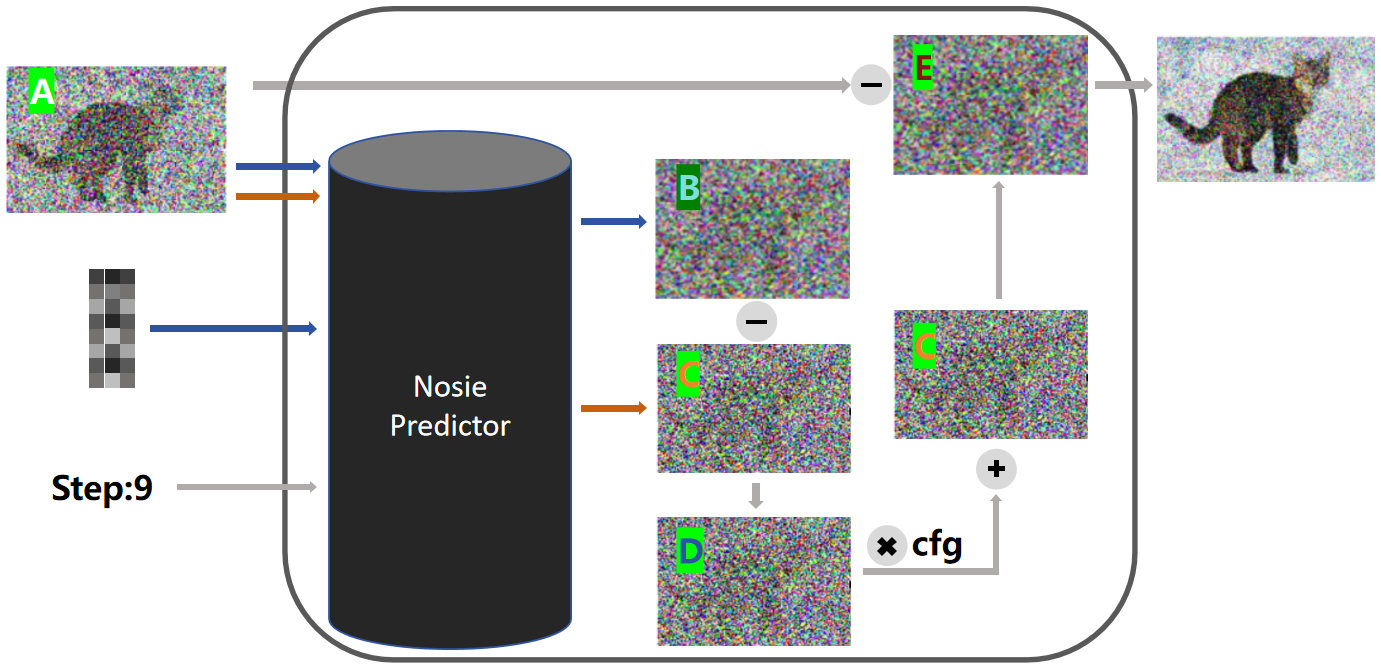
接着,降噪步骤会将噪音图 B 和噪音图 C 相减,得到图 D。我们可以用简单的数学来解释这张图的意义。起首,图 B 是通过 Prompt 和随机图预测的噪声,可以简单明白为包含「根据 Prompt 预测的噪声」和「根据随机图预测的噪声」,而图 C 则仅包含「根据随机图预测的噪声」。因此,B 减去 C,就得到「根据 Prompt 预测的噪声」。
然后,降噪过程会将噪声图 D 通过乘以一个系数放大,这个系数在 Stable Diffusion 设置中被称为CFG。接着,将放大后的图与噪声图 C 相加,得到图 E。如许做的目的是进步图片天生的准确性,通过增长「根据 Prompt 预测的噪声」的权重来确保天生的图像与 Prompt 更加相干。如果没有这一步,天生的图片可能与 Prompt 的关联度较低。这种方法被称为 Classifier Free Guidance(无分类引导法)。
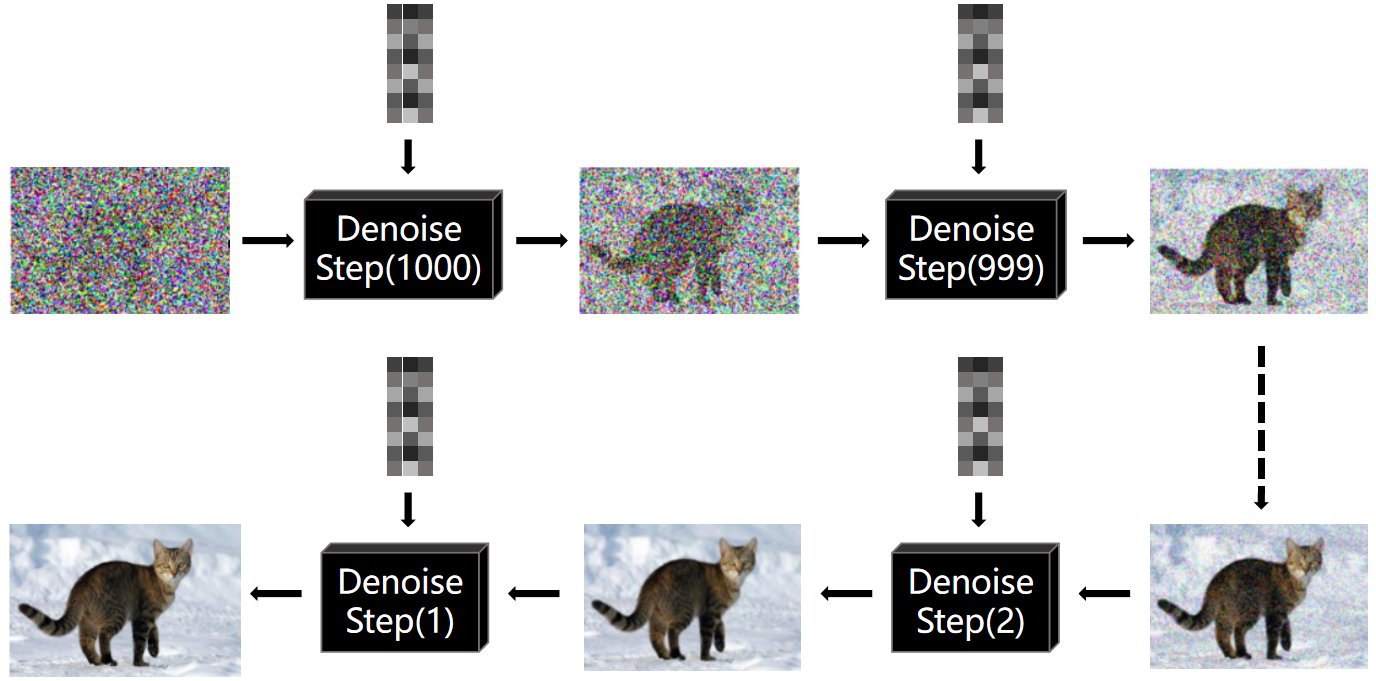
末了,降噪过程会将图 A 减去图 E,得到一张新的图像。这就像之前提到的“镌刻”过程,通过去除不需要的噪声来精粹图像。