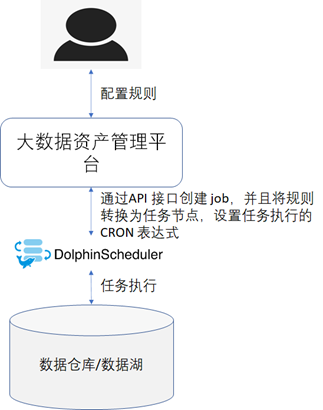
规则
| 描述
|
表字段的空值率
| 采集指定表的指定字段为空的比率
|
表字段的异常率
| 采集指标表的指定字段值的异常率,比如性别字段,只可能为男大概女,对于别的值就是异常值,我们可以根据规则统计出异常值的比率,哪些值是异常值当然也必要支持自定义维护
|
表字段数据格式异常率
| 采集指标表的指定字段值的数据格式异常率,比如时间格式大概手机号格式不符合指定规则的就是异常数据,我们可以计算出这些格式异常的比率
|
表字段数据的重复率
| 采集指定表的指定字段值的重复率,比如某些字段的值是不允许重复的,出现重复时就是异常
|
表字段的缺失率
| 采集指定表的字段数量是否和预期的字段数量同等,如果不同等,就是出现了字段缺失,就可以统计出字段的缺失率
|
表数据入库的及时率
| 采集指定的表数据的入库时间和当前系统时间的差别,然厥后计算出数据的及时性以及及时率
|
表记载的丢失率
| 1、 采集指定的表数据的记载数,然后和预期的数据量大概源表中的数据量举行比力,计算出数据记载的丢失率
2、 采集指定的表数据的记载数,然后和周大概月平均值举行比力,判定数据记载数是否低于正常尺度,从而判定是否存在丢失。
|
除了通用规则外,肯定还必要支持自定义的规则,自定义的规则可以允许用户自己编写SQL脚本、Python语言脚本大概scala 语言脚本。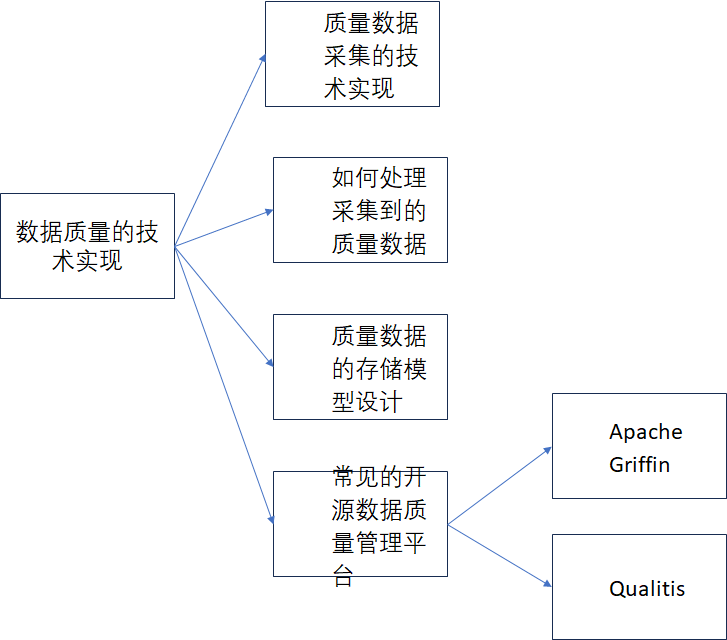
 ata quality management: Overview
ata quality management: Overview