Transformer 是一种深度学习模型架构,最初由 Vaswani 等人在 2017 年的论文《Attention is All You Need》中提出。它引入了基于注意力机制的结构,降服了传统 RNN(递归神经网络)在处理长序列输入时的服从和结果问题。Transformer 模型特殊适用于自然语言处理(NLP)任务,如机器翻译、文本天生和文天职类等。
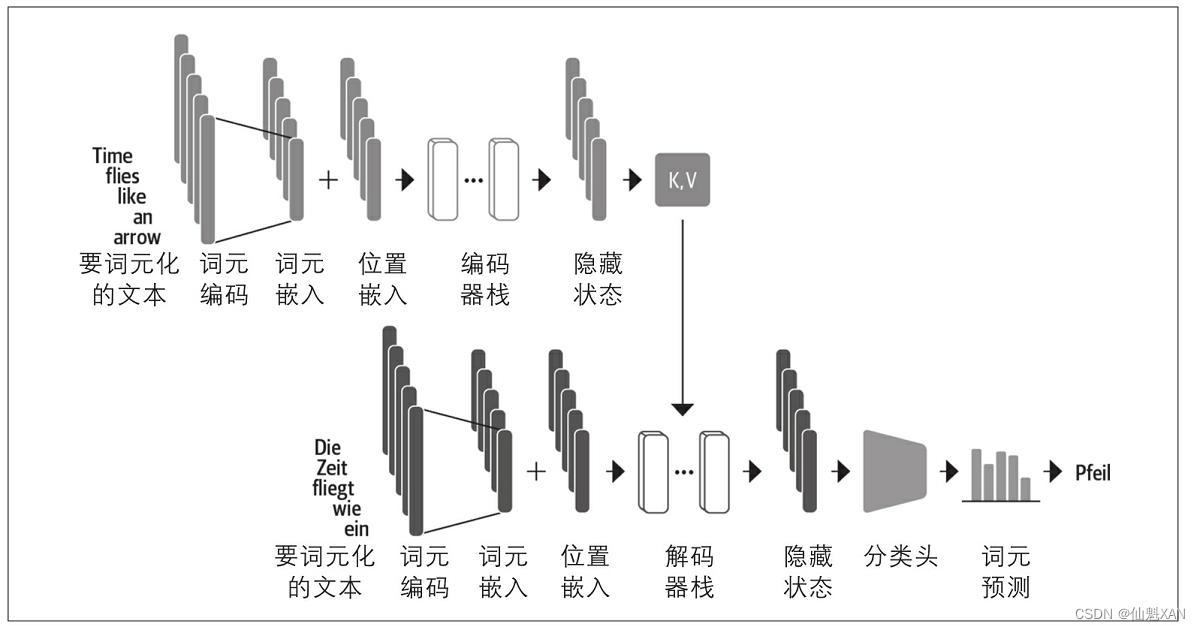
Transformer 架构主要由编码器(Encoder)息争码器(Decoder)两个部分构成:
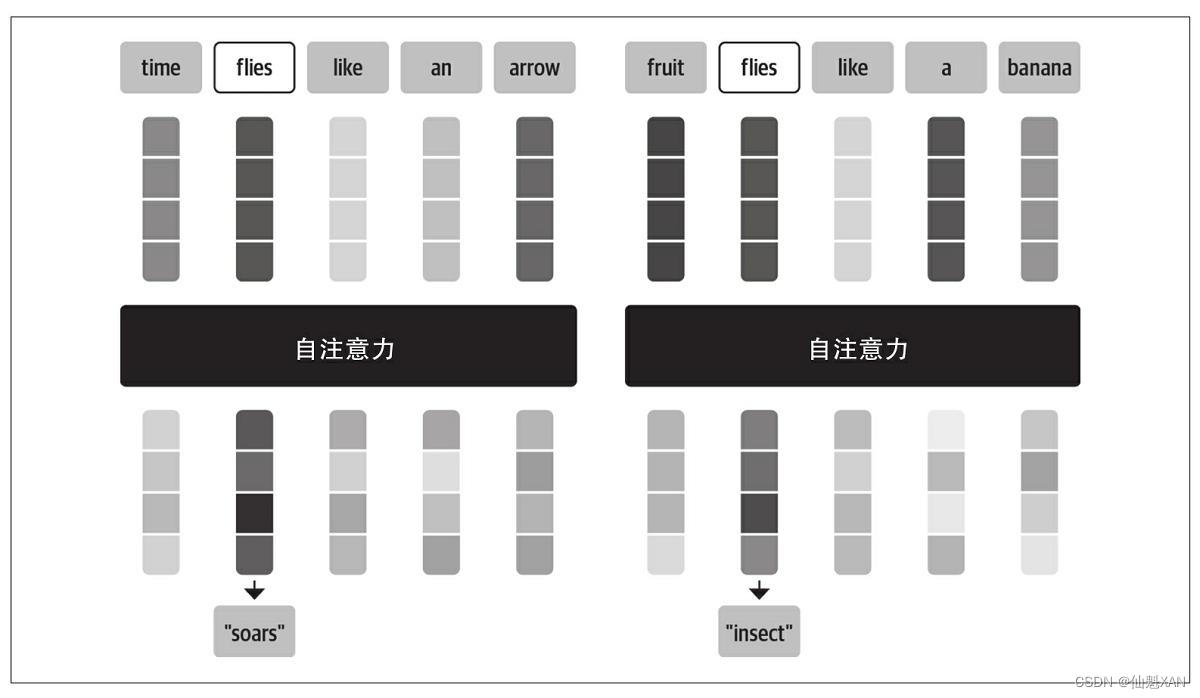
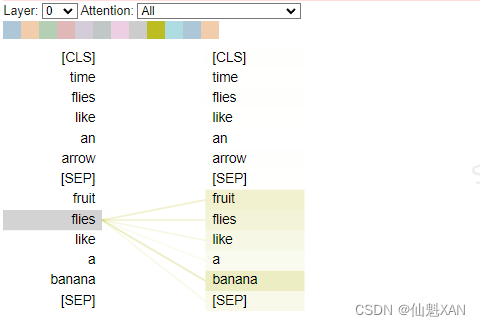
左边的flies为飞的意思,所以上下文嵌入与表现飞的soars相近。右边的flies为苍蝇的意思,所以上下文嵌入与表现昆虫的insect相近。
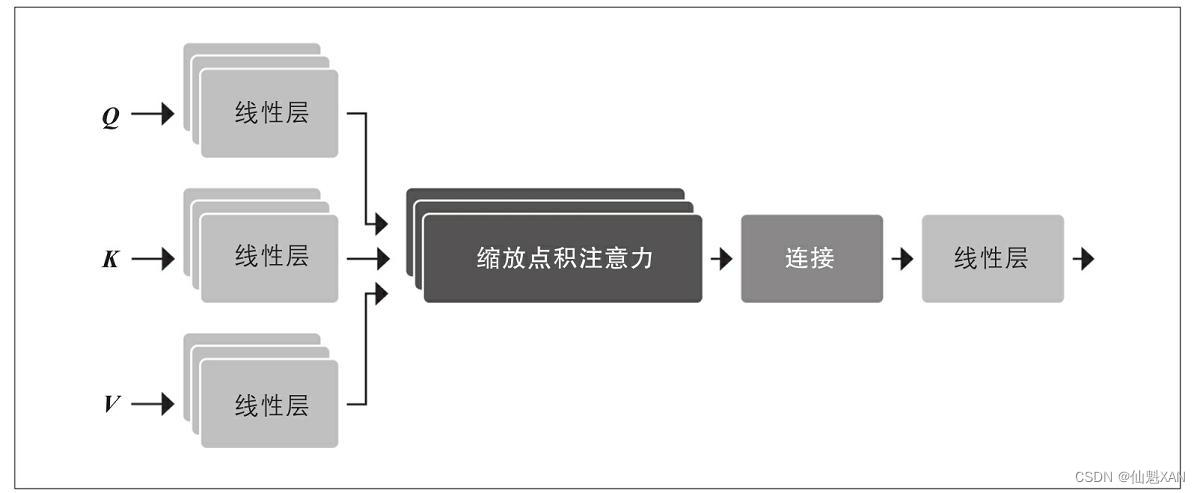
此中的系数wji称为注意力权重,其被规范化以使得∑jwji=1。假如想要相识为什么平均词元嵌入大概是一个好主意,那么可以这样思考,当你看到单词“flies”时会想到什么。也许你会想到令人讨厌的昆虫,但是假如你得到更多的上下文,比如“time flies like an arrow”,那么你会意识到“flies”表现的是动词。同样地,我们可以通过以差别的比例联合所有词元嵌入来创建“flies”的表现形式,也许可以给“time”和“arrow”的词元嵌入分配较大的权重wji。用这种方式天生的嵌入称为上下文嵌入,早在Transformer发明之前就存在了,比方ELMo语言模型 。如图展示了这一过程,我们通过自注意力根据上下文天生了“flies”的两种差别表现 。
Transformer模型通常分为与任务无关的主体和与任务相干的头。我们将在第4章讲述Hugging Face Transformers库的设计模式时会再次提到这种模式。到目前为止,我们所构建的都是主体部分的内容,假如我们想构建一个文天职类器,那么我们还需要将分类头附加到该主体上。每个词元都有一个隐藏状态,但我们只需要做出一个预测。有几种方法可以解决这个问题。一样寻常来说,这种模型通常利用第一个词元来进行预测,我们可以附加一个dropout和一个线性层来进行分类预测。下面的类对现有的编码器进行了扩展以用于序列分类:
class TransformerForSequenceClassification(nn.Module):