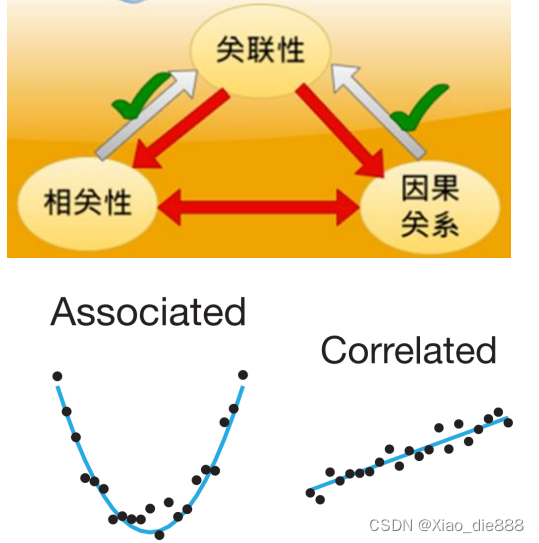
- 定义:指一个变量能够提供有关另一个变量的信息。
- 特点:关联性是一个广泛的概念,它可以包罗直接的、间接的、强的或弱的联系。
- 定义:指两个变量同时上升或下降的趋势。
- 特点:相关性通常用相关系数来量化,如皮尔逊相关系数,它可以测量变量之间的线性关系强度和方向。
- 误区:相关性意味着关联性,而不是因果关系;
- 定义:指一个变量(原因)直接影响另一个变量(结果)。
- 特点:因果关系必要通过实行或统计方法来验证,例如随机对照试验(RCT)或使用因果推断模子。
- 误区:因果关系意味着关联,而不是相关性






| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |