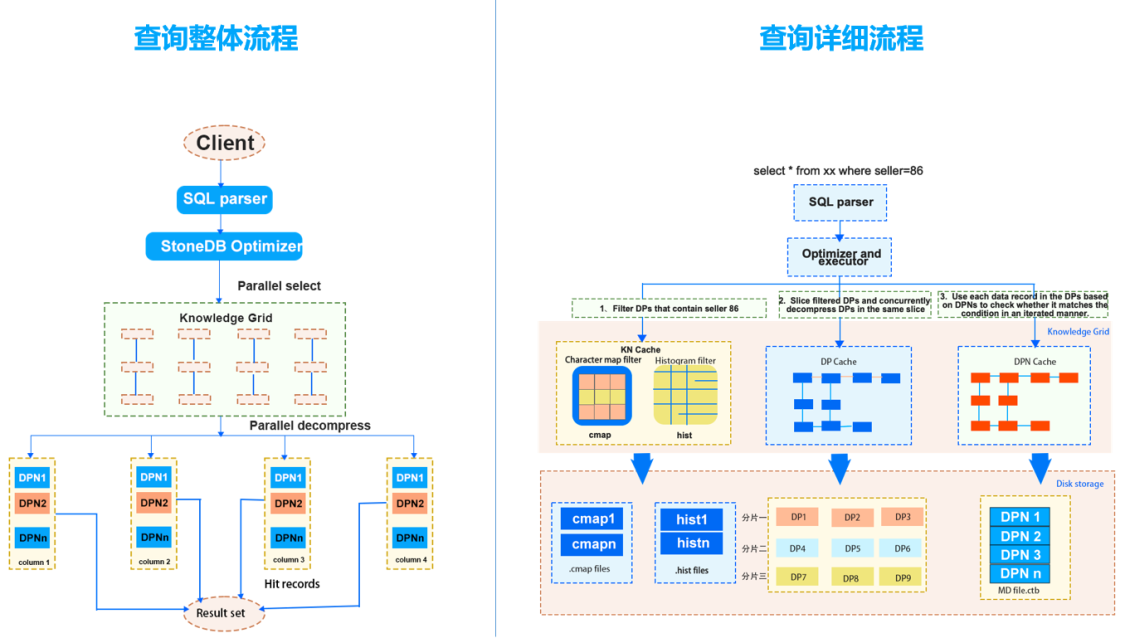
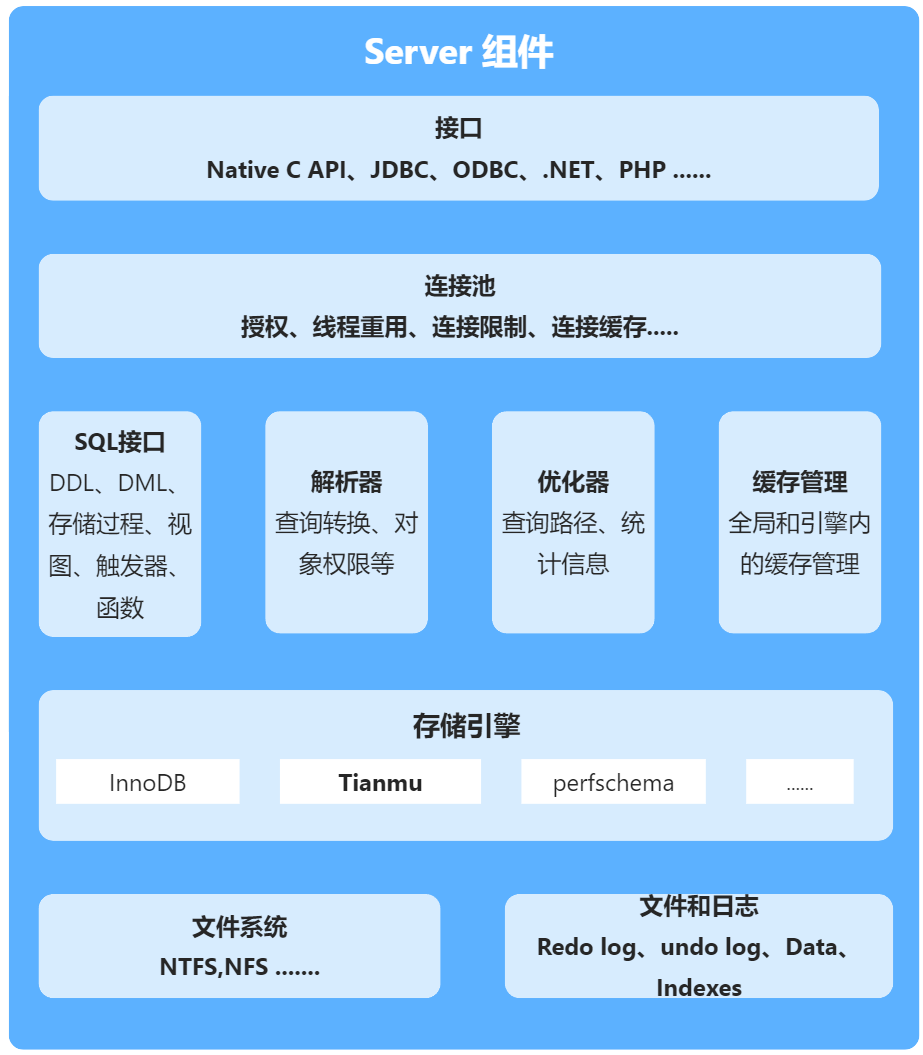
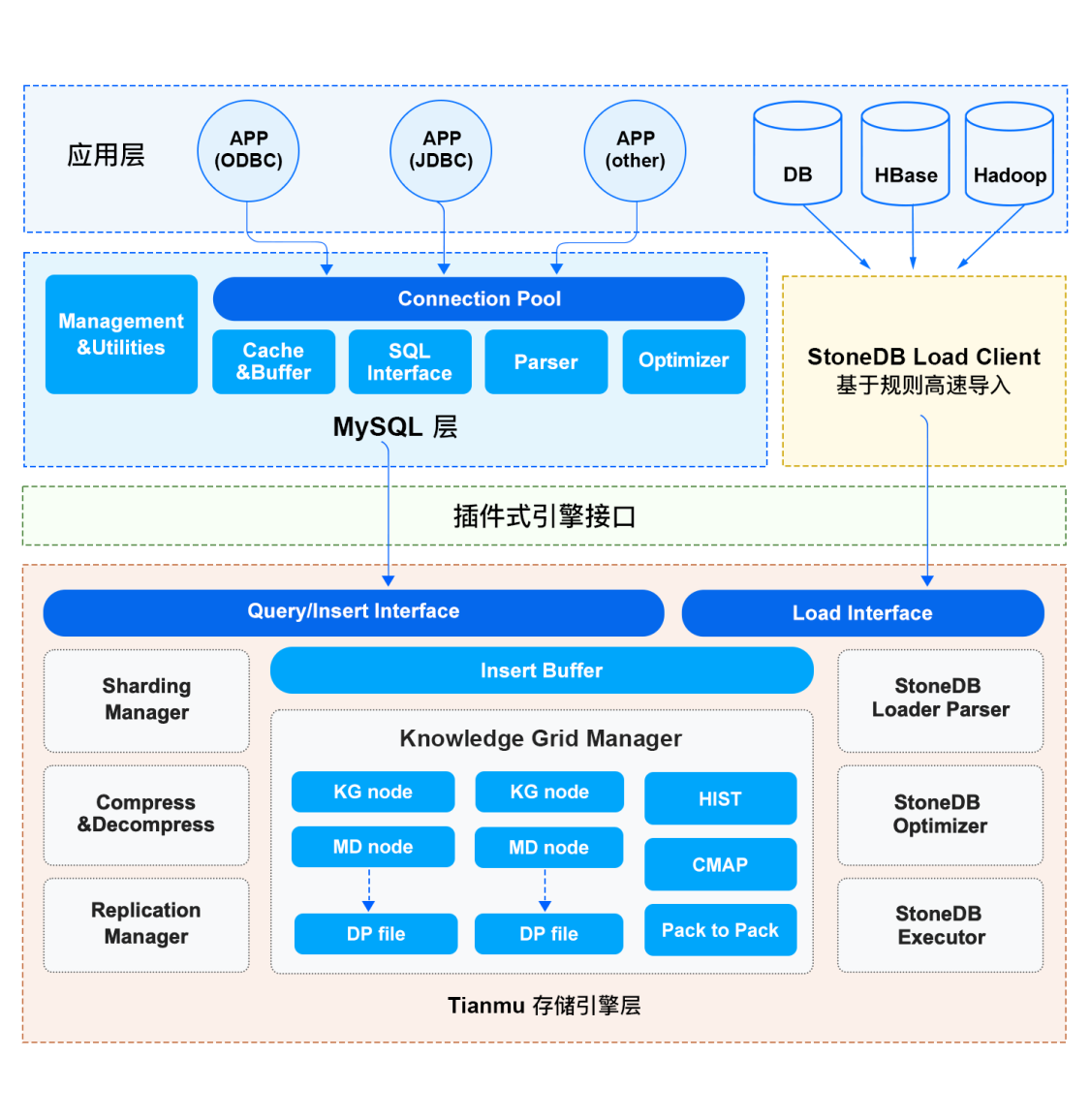
解析客户端传来的 SQL ,进行关键字提取、解析,生成解析树。解析的词包括 select、update、delete、or、group by 等,对不支持的语法会向客户端抛出异常:ERROR:You have an error in your SQL syntax.
比如,执行如下语句:
select * from user where userId =1234;
复制代码
在分析器中就通过语义规则器将 select、from、where 这些关键词提取和匹配出来, MySQL 会自动判断关键词和非关键词,将用户的匹配字段和自定义语句识别出来。这个阶段也会做一些校验,比如校验当前数据库是否存在 user 表,同时假如 user 表中不存在 userId 这个字段同样会报错:unknown column in field list. 解析入口: