ToB企服应用市场:ToB评测及商务社交产业平台
标题:
RocketMQ 是什么?它的架构是怎样的?和 Kafka 有什么区别?
[打印本页]
作者:
愛在花開的季節
时间:
2024-8-24 08:44
标题:
RocketMQ 是什么?它的架构是怎样的?和 Kafka 有什么区别?
RocketMQ 是什么?
RocketMQ 是阿里自研的国产
消息队列
,现在已经是 Apache 的顶级项目。和其他消息队列一样,它担当来自
生产者
的消息,将消息分类,每一类是一个
topic
,
消耗者
根据需要订阅 topic,获取内里的消息。
RocketMQ 的架构是怎么样的?
RocketMQ主要由Producer、Broker和Consumer三部门组成,如下图所示:
Producer:消息生产者,负责将消息发送到 Broker.
Broker:消息中转服务器,负责存储和转发消息。RocketMQ 支持多个 Broker 构成集群,每个 Broker 都拥有独立的存储空间和消息队列。
Consumer:消息消耗者,负责从 Broker 消耗消息
NameServer:名称服务,负责维护 Broker 的元数据信息,包罗 Broker 地址、Topic 和 Queue 等信息Producer 和 Consumer 在启动时需要毗连到 NameServer 获取 Broker 的地址信息。
Topic:消息主题,是消息的逻辑分类单位。Producer 将消息发送到特定的 Topic 中,Consumer 从指定的Topic 中消耗消息
Message Queue:4:消息队列,是 Topic 的物理实现。一个Topic可以有多个 Queue ,每个 Queue 都是独立的存储单元。Producer 发送的消息会被存储到对应的 Queue 中,Consumer 从指定的 Queue 中消耗消息
RocketMQ 和 Kafka 的区别?
RocketMQ 的架构其实参考了 Kafka 的设计头脑,同时又在 Kafka 的基础上做了一些调整。
这些调整,用一句话总结就是,“
和 Kafka 相比,RocketMQ 在架构上做了减法,在功能上做了加法
”。
架构上做了减法
简化协调节点
Zookeeper 在 Kafka 架构中会和 broker 通信,维护 Kafka 集群信息。一个新的 broker 连上 Zookeeper 后,其他 broker 就能立马感知到它的加入,像这种能在分布式情况下,让多个实例同时获取到同一份信息的服务,就是所谓的
分布式协调服务
。
但 Zookeeper 作为一个
通用的
分布式协调服务,它不仅可以用于服务注册与发现,还可以用于分布式锁、配置管理等场景。Kafka 其实只用到了它的部门功能,用 Zookeeper 太重了。
所以 RocketMQ 去掉了 Zookeeper,引入 NameServer 用一种更轻量的方式,管理消息队列的集群信息。生产者通过 NameServer 获取到 topic 和 broker 的路由信息,然后再与 broker 通信,实现
服务发现
和
负载均衡
的效果。
Kafka 从 2.8.0 版本就支持将 Zookeeper 移除,通过在 broker 之间加入一致性算法 raft 实现同样的效果,这就是所谓的
KRaft
或
Quorum
模式。
简化分区
Kafka 会将 topic 拆分为多个 partition,用来提升
并发性能
。
在 RocketMQ 里也一样,将 topic 拆分成了多个分区,但换了个名字,叫
Queue
,也就是"
队列
"。
Kafka 中的 partition 会存储
完整
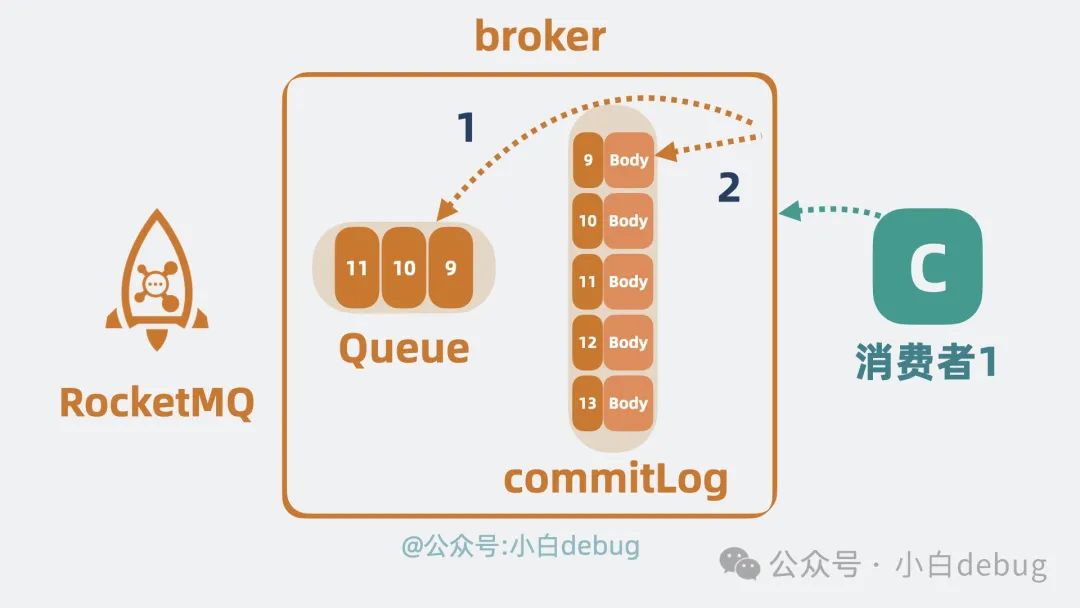
的消息体,而 RocketMQ 的 Queue 上却只存一些
扼要
信息,比如消息偏移 offset,而消息的完整数据则放到"一个"叫 commitlog 的文件上,通过 offset 我们可以定位到 commitlog 上的某条消息。
Kafka 消耗消息,broker 只需要直接从 partition 读取消息返回就好,也就是读第
一次
就够了。
而在 RocketMQ 中,broker 则需要先从 Queue 上读取到 offset 的值,再跑到 commitlog 上将完整数据读出来,也就是需要读
两次
。
看起来 Kafka 的设计更高效?为什么 RocketMQ 不采用 Kafka 的设计?这就跟底层存储有关了
底层存储
Kafka 的 partition 分区,其实在底层由很多
段
(
segment
)组成,每个 segment 可以认为就是个
小文件
。将消息数据写入到 partition 分区,本质上就是将数据写入到某个 segment 文件下。
Kafka 同时写
多个
topic 底下的 partition 就会越多, segment 也会越多,等同于同时写多个文件**,
虽然每个文件内部都是顺序写,但多个文件存放在磁盘的差异地方,原本
顺序写磁盘就可能劣化变成了随机写**。于是写性能就低落了。
为了缓解同时写多个文件带来的随机写问题,RocketMQ 索性将单个 broker 底下的多个 topic 数据,全都写到"
一个
"逻辑文件 CommitLog 上,这就消除了随机写多文件的问题,将所有写操纵都变成了顺序写。大大提升了 RocketMQ 在多 topic 场景下的写性能。
CommitLog 逻辑上是一个大文件,实际是由多个固定巨细的小文件构成,写慢一个小文件,就会创建一个新的来写。
简化备份模型
Kafka 会将 partiton 分散到多个 broker 中,并为 partiton 配置副本,将 partiton 分为 leader和 follower,也就是
主和从
。
RocketMQ 将 broker 上的所有 topic 数据到写到 CommitLog 上。假如还像 Kafka 那样给每个分区单独建立同步通信,就还得将 CommitLog 里的内容
拆开
,这就照旧退化为
随机读
了。
于是 RocketMQ 索性
以 broker 为单位区分主从
,主从之间同步 CommitLog 文件,保持高可用的同时,也大大简化了备份模型。
功能上做了加法
消息过滤
我们知道,Kafka 支持通过 topic 将数据举行分类,比如订单数据和用户数据是两个差异的 topic,但假如我还想
再进一步分类
呢?比如同样是用户数据,还能根据 vip 等级进一步分类。假设我们只需要获取 vip6 的用户数据,在 Kafka 里,消耗者需要消耗 topic 为用户数据的
所有消息
,再将 vip6 的用户过滤出来。
而 RocketMQ 支持对消息打上
标记
,也就是打
tag
,消耗者能根据 tag 过滤所需要的数据。比如我们可以在部门消息上标记 tag=vip6,这样消耗者就能
只获取
这部门数据,省下了消耗者过滤数据时的资源消耗。
相当于 RocketMQ 除了支持通过 topic 举行一级分类,还支持通过 tag 举行二级分类。
支持事务
Kafka 也支持事务,比如生产者发三条消息 ABC,这三条消息要么同时发送乐成,要么同时发送失败。
但是,写业务代码的时候,我们更想要的事务是,"
执行一些自定义逻辑
"和"
生产者发消息
"这两件事,要么同时乐成,要么同时失败。
而这正是 RocketMQ 支持的事务能力。
加入延时队列
假如我们希望消息投递出去之后,消耗者不能立马消耗到,而是过个一定时间后才消耗,也就是所谓的
延时消息
,就像文章开头的定时外卖那样。假如我们使用 Kafka, 要实现类似的功能的话,就会很费劲。
但 RocketMQ 自然支持
延时队列
,我们可以很方便实现这一功能。
加入死信队列
消耗消息是有可能失败的,失败后一样平常可以设置
重试
。假如多次重试失败,RocketMQ 会将消息放到一个专门的队列,方便我们
后面单独处理
。这种专门存放失败消息的队列,就是
死信队列
。
Kafka 原生不支持这个功能,需要我们自己实现。
消息回溯
Kafka 支持通过
调整 offset
来让消耗者从某个地方开始消耗,而 RocketMQ,除了可以调整 offset, 还支持
调整时间
( kafka 在0.10.1后支持调时间)
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4