(2)告警相似度计算
(2)告警分诊

【安全告警数据分析之道:二】数据过滤篇-腾讯云开发者社区-腾讯云 (tencent.com)
【安全告警分析之道:三】非常处理篇-腾讯云开发者社区-腾讯云 (tencent.com)
【安全告警分析之道:四】扫描辨认(上)-腾讯云开发者社区-腾讯云 (tencent.com)

| 链接 | 择要总结 |
| 智能运维-告警太多看不过来?必要告警优化啦-腾讯云开发者社区-腾讯云 (tencent.com) | (1)告警级别划分:初中高级 (2)告警相似度计算 |
| 【攻击意图评估:序】误报太多?谈海量告警筛选-腾讯云开发者社区-腾讯云 (tencent.com) | (1)非常检测筛选法:关注有数范例、有数端口等在统计分布中孤立/离群的告警 |
| 告警载荷嵌入的前景和难点-腾讯云开发者社区-腾讯云 (tencent.com) | (1)告警载荷择要 |
| 基于多维度关联的告警评估方法-腾讯云开发者社区-腾讯云 (tencent.com) | (1)基于图的告警关联分析:资产关联图,Payload关联图 |
| AISecOps:量化评估告警筛选方案的性能-腾讯云开发者社区-腾讯云 (tencent.com) | (1)告警保举:根据紧张程度 (2)告警分诊 |
| 告警全量分诊思路分析-腾讯云开发者社区-腾讯云 (tencent.com) | (1)“Alert throttling”的方式举行告警聚合 |
| 【安全告警数据分析之道:一】数据透视篇-腾讯云开发者社区-腾讯云 (tencent.com) 【安全告警数据分析之道:二】数据过滤篇-腾讯云开发者社区-腾讯云 (tencent.com) 【安全告警分析之道:三】非常处理篇-腾讯云开发者社区-腾讯云 (tencent.com) 【安全告警分析之道:四】扫描辨认(上)-腾讯云开发者社区-腾讯云 (tencent.com) | (1)提取字段:按照数量大到数量小,紧张程度低到紧张程度高的原则对告警举行过滤、分类 |
| 引用文献 | 择要总结 |
| 马琳茹. 网络安全告警信息处理技术研究[D].国防科学技术大学,2009. | 该文章为博士论文,年份比较久,但详细先容了很多告警处理方式,包罗上下文报警关联等,可以多做参考 ,有一个整体的了解。 1、正则表达式告警筛选,规则匹配 2、多特性聚合:攻击范例特性、空间特性和时间特性束缚条件   3、第三章后太难了看不懂了 ... ,,ԾㅂԾ,, |
| 陈瑞,冷迪,李英.数据中央告警事故全面自愈方法及系统研究[J].电子元器件与信息技术,2021,5(09):241-242.DOI:10.19772/j.cnki.2096-4455.2021.9.110. | 两页,内容形貌雷同专利,且无有用参考方法 |
| 任姝锦. 电力网络安全告警信息关联性方法的研究与实现[D].内蒙古大学,2022.DOI:10.27224/d.cnki.gnmdu.2022.001153. | 该文章为硕士论文,方法简单,相对容易理解。 1、创新点:DP-Kmeans去除误报,Max-IFP关联算法挖掘内在接洽 2、聚类方法:属性相似度、专家经验、神经网络、哈希函数 3、关联分析:关联分析/频仍项集挖掘:Apriori算法_最大频仍项目集挖掘算法apriori算法案例报告-CSDN博客 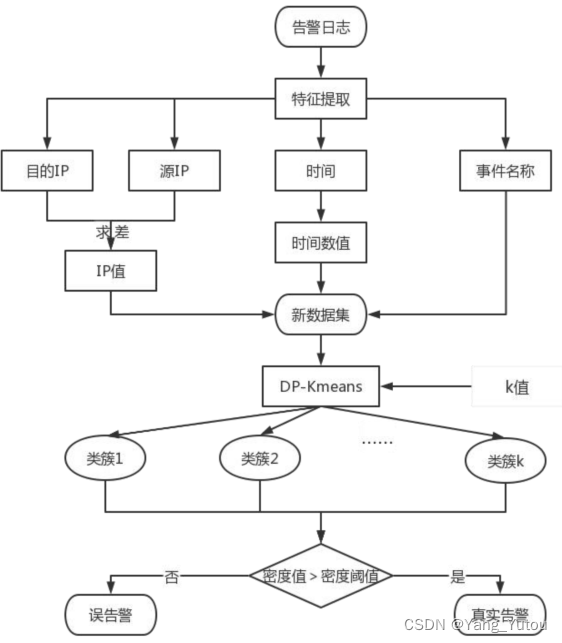 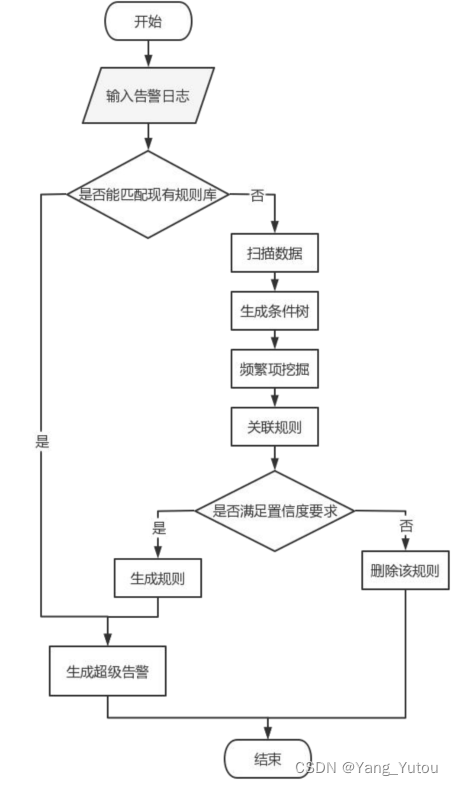 |
| Tjhai G C, Furnell S M, Papadaki M, et al. A preliminary two-stage alarm correlation and filtering system using SOM neural network and Kmeans algorithm[J]. Computers&Security, 2010, 29(6): 712-723 | 无监督神经网络算法SOM(自组织映射)+kmeans两级告警滤波系统,判断真假告警。整个过程包罗特性提取、报警聚合、聚类分析和分类四个阶段。 第一阶段的分类是为了恰当地关联与特定运动相关的警报。由单个事故触发的全部警报,无论署名范例怎样,都将被映射并分组到一个集群中。此外,第二阶段的重要目标是随后将第一次分类中产生的全部集群标记为真警报组和假警报组。 |
| 郭帆. 一种基于分类和相似度的报警聚合方法[J]. 计算机应用, 2007, 27(10). | 有监督,将告警按攻击类别分为四类,属性值分为类别、数值、时间、字符串属性,设定差别的属性相似度计算方法和阈值,数值和字符串比较结果为0和1。  |
| 石镇宇.融合多源告警信息的安全态势感知方法[J].移动通信,2022,46(12):108-113. | 通过CNN+LSTM,利用告警信息的关联性对多源告警信息(防火墙日记、网络流量、安全告警、威胁情报)举行融合关联,接纳最大概率攻击路径的方法更清楚展现网络攻击行为,提拔网络安全态势感知精准度。 |
| 白冰,段笑晨.电力网络安全告警信息挖掘研究与实现[J].自动化与仪器仪表,2023(05):87-91.DOI:10.14016/j.cnki.1001-9227.2023.05.087. | 该论文和上面那个(任姝锦)硕士论文大差不差。 创新点:DP-Kmeans举行聚类,Max-IFP关联算法挖掘内在接洽 |
| 王维靖,陈俊洁,杨林,等.基于多元数据融合的网络侧告警排序方法[J/OL].软件学报:1-17[2024-05-06].https://doi.org/10.13328/j.cnki.jos.007118. | 绿盟与天津大学互助项目: 1、起首,计划了一个基于源 IP 地址与目标 IP 地址的多策略上 下文编码器,生成告警频数矩阵,用于捕获告警的上下文信息; 2、其次,一个基于注意力机制双向 GRU 模型与ChineseBERT 模型的文本编码器, 从告警报文等文本数据中学习网络侧告警的语义信息; 3、末了, 构建排序模型得到告警排序值, 并按其降序将攻击性强的高风险告警排在前面。 输入数据: (1) 上下文数据, 即基于源 IP 地址(s-ip)与目标 IP 地址(d-ip)的上下文告警; (2) 文本数据, 包罗告警名称(name)、告警载荷(payload)、Web 访问请求体(q-body)、Web 访问响应体(r-body); (3) 离散数据, 即目标端口(d-port)等 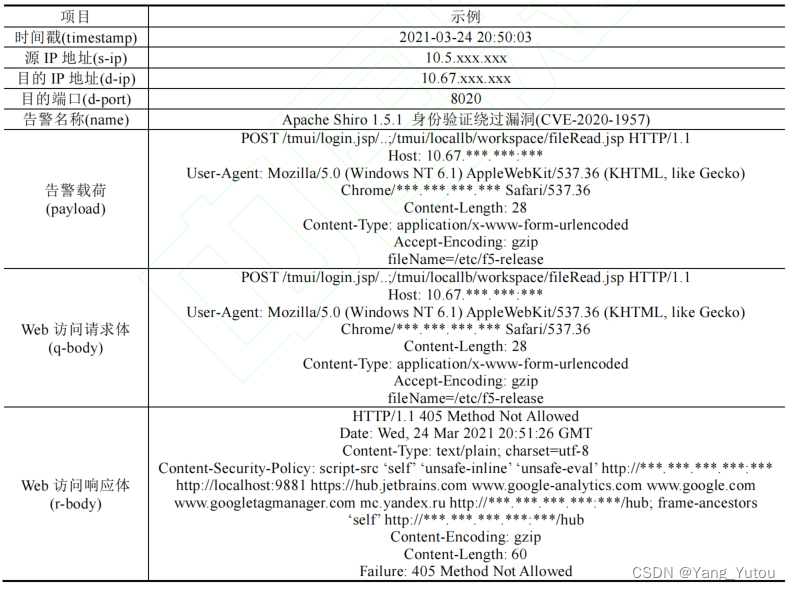 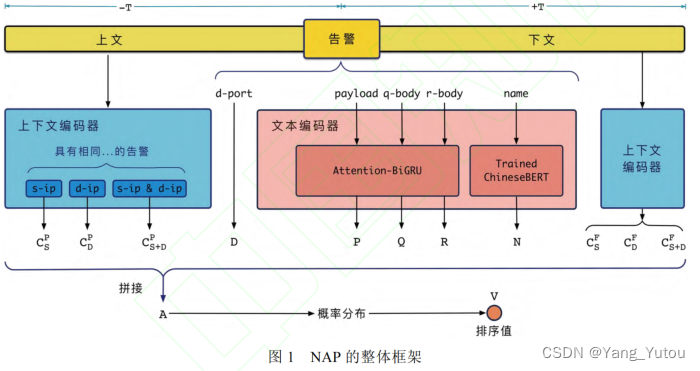 |
| 崔豪驿,鲍娌娜,苗德雨,等. 基于XGBoost 的网络安全设备告警误报检测模型[J]. 电力大数据,2021,24(7):31-39. | 1、从攻击时间、IP 地址、端口等原始数据特性中构造、提取、选择告警误报检测相关特;对于数据预处理和特性工程先容的较为详细。 2、对138万条告警数据举行了是否误报的0和1标注,比例为1:1 3、其次,利用XGBoost对告警误报准确分类辨认 |
| A.Valdes, K. Skinner. Probabilistic alert correlation, In Proceedings of the 4th International Symposium on Recent Advances in Intrusion Detection | 在概率框架上计算告警属性相似度 ,引入盼望相似度作为属性的权值计算总的相似度,通过调解相似度盼望和最小相似度。。。 |
| Bin Zhu,Ali A.Ghorbani. Alert correlation for extracting attack strategies. International Journal of Network Security,October 2005,3(2): 259-270. | 多层感知机和支持向量机实现告警关联,根据告警关联强度和时间间隔建立关联矩阵 |
| Oliver . Dain and R,K.Cunningham, Building scenarios from a heterogeneous alert stream. ACM Workshop on Data mining for Security Applications, June2001, pp.1-13. | 接收到新告警是,与末了一个告警举行关联比较,计算从属场景的概率 |
| 序号 | 可行方法 | 先容【算法】 |
| 1 | 非常检测筛选 | 有数报警、范例、端口等在统计分布中的利群检测。【孤立丛林】 |
| 2 | 告警聚合 | 1、融合多种特性实现告警收敛: 攻击范例特性的束缚:相似的告警范例; 空间特性束缚:相似的攻击源IP,源端口(随机),目标IP,目标端口; 时间特性束缚:告警之间的时间差阈值。 2、相似度计算:【Jaccard,欧氏距离,余弦距离】 |
| 3 | 告警聚类 | 设置告警阈值,判断是否误报。【k-means, DP-kmeans, DBscan】 |
| 4 | 告警关联 | 联合关联规则判断。【Max-IFP最大频仍项挖掘】 |
| 5 | 告警分诊 | 将全部告警分类划分为值得关注、攻击性低、可忽略等等级,必要标签,【XgBoost等树模型】 |
| 6 | 告警保举 | 对固定时间间隔的全部报警举行排序,通常只关注Top10。【基于源IP和目标IP的编码器+基于注意力机制和ChineseBert 的文本语义提取+排序模型】 |
| 7 | 告警载荷择要 | 1、择要生成。【LLM大语言模型】 2、告警词云。 |
| 8 | 安全问答 | 知识库+大语言模型。 |
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |