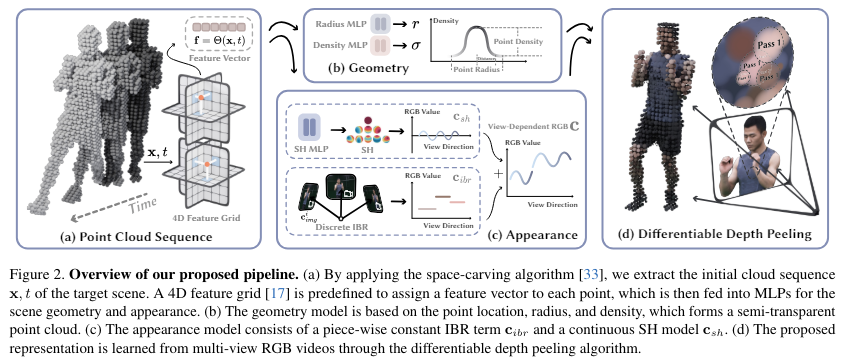
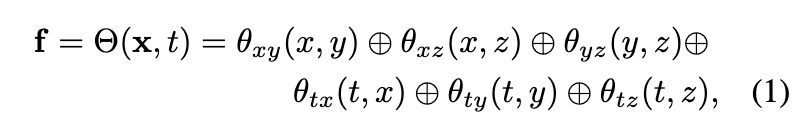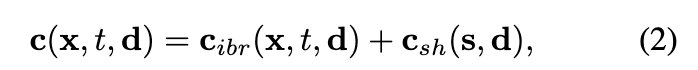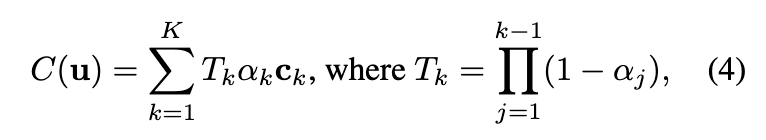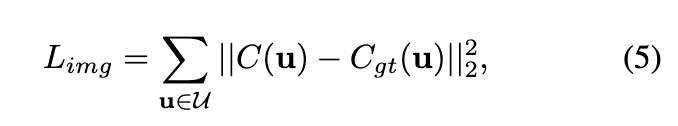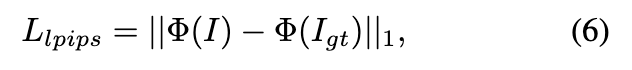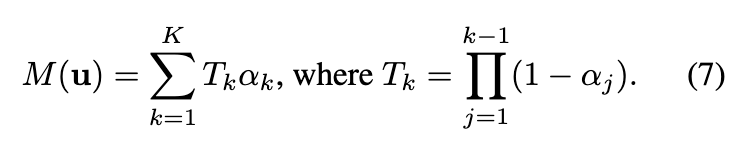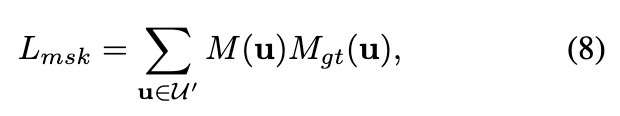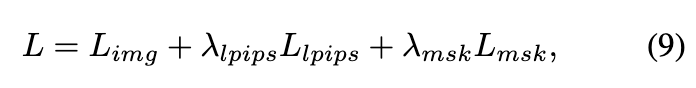在每个点上界说显式 SH 系数,如在 3D 高斯分裂 中。当 SH 系数的维度较高且动态场景的点数目较大时,该模型的巨细可能太大,无法在消费级 GPU 上训练。
基于 MLP 的 SH 模型。使用 MLP 来预测每个点的 SH 系数可以有用地减少模型巨细。然而,本文的实行发现基于 MLP 的 SH 模型难以渲染高质量图像。
连续视角依赖的图像混合模型,如 ENeRF。使用图像混合模型表示外观比仅使用基于 MLP 的 SH 模型具有更好的渲染质量。然而,ENeRF 中的网络将视角方向作为输入,因此无法轻松预盘算,从而限制了推理期间的渲染速率。
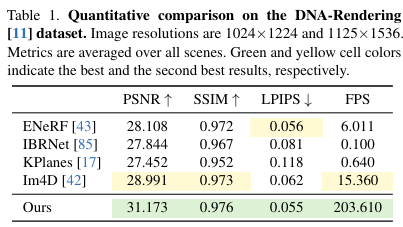
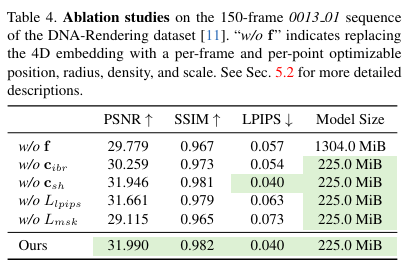
与这三种方法相比,本文的外观模型联合了离散图像混合模型 和连续 SH 模型 。图像混合模型 提拔了渲染性能。此外,由于其网络不将视角方向作为输入,它支持预盘算。SH 模型 实现了任何视角方向的视角依赖结果。在训练期间,本文的模型使用网络表示场景外观,因此其模型巨细合理。在推理期间,预盘算网络输出以实实际时渲染。
可微分深度剥离
研究者们提出的动态场景表示可以使用深度剥离算法渲染成图像。得益于点云表示,能够利用硬件光栅化器显著加速深度剥离过程。此外,使这一渲染过程可微分也很容易,从而能够从输入的 RGB 视频中学习本文的模型。
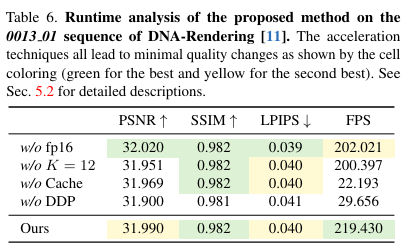
研究者们开发了一个自界说着色器来实现包含 K 次渲染通道的深度剥离算法。考虑一个特定的图像像素 u。在第一次通道中,本文的方法起首使用硬件光栅化器将点云渲染到图像上,为像素 u 分配最近的点 。记点 的深度为 。随后,在第 k 次渲染通道中,所有深度值 小于上一通道记载深度 的点都被丢弃,从而得到像素 u 的第 k 近的点。丢弃较近的点在自界说着色器中实现,因此它仍然支持硬件光栅化。在 K 次渲染通道之后,像素 u 有一组排序的点 。
基于点 ,使用体渲染合成像素 u 的颜色。像素 u 的点 的密度是基于投影点和像素 u 在2D图像上的距离界说的。
其中, 是摄像机投影函数。 和 r 分别是点 的密度和半径。在训练过程中,使用 PyTorch实现投影函数,因此方程 (3) 自然是可微的。在推理过程中,利用硬件光栅化过程高效地获得距离 ,这通过 OpenGL 实现。
记点 的密度为 。像素 u 的体渲染颜色公式如下: