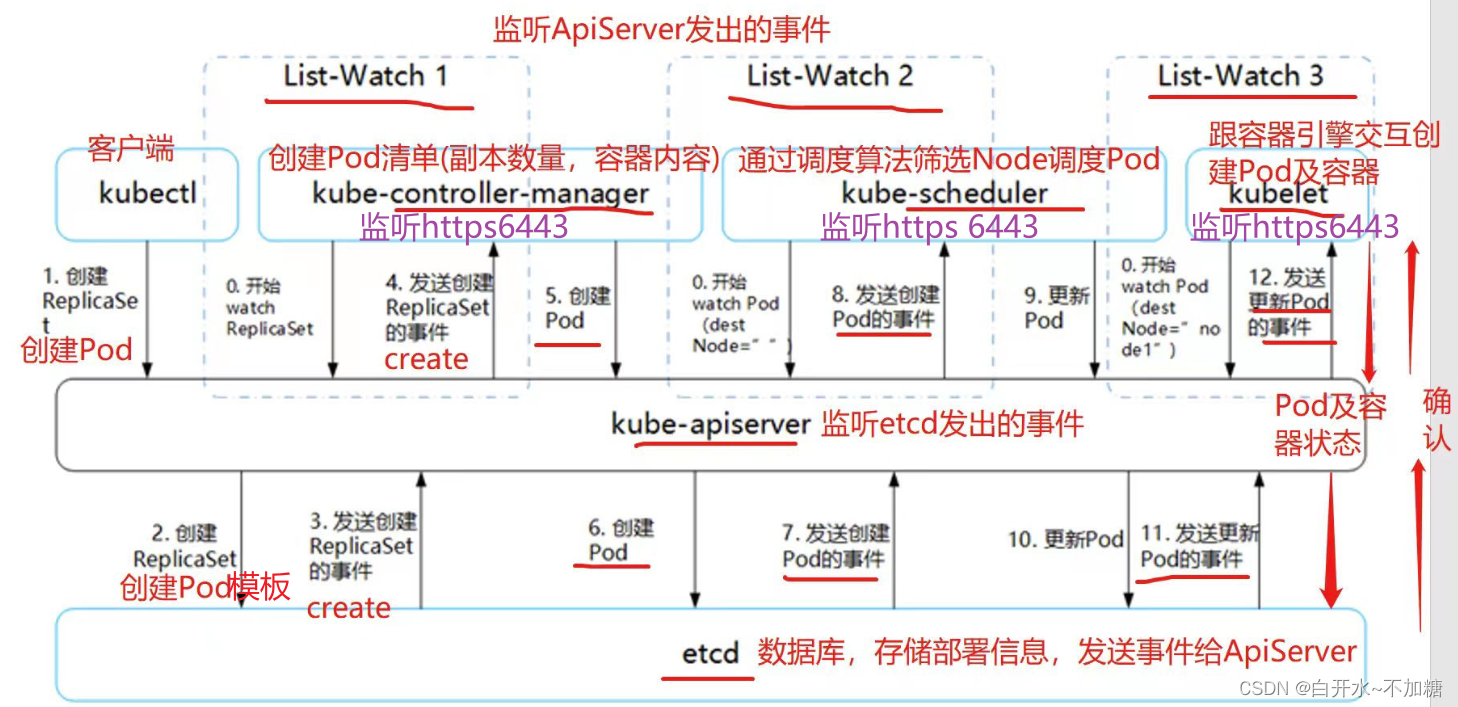

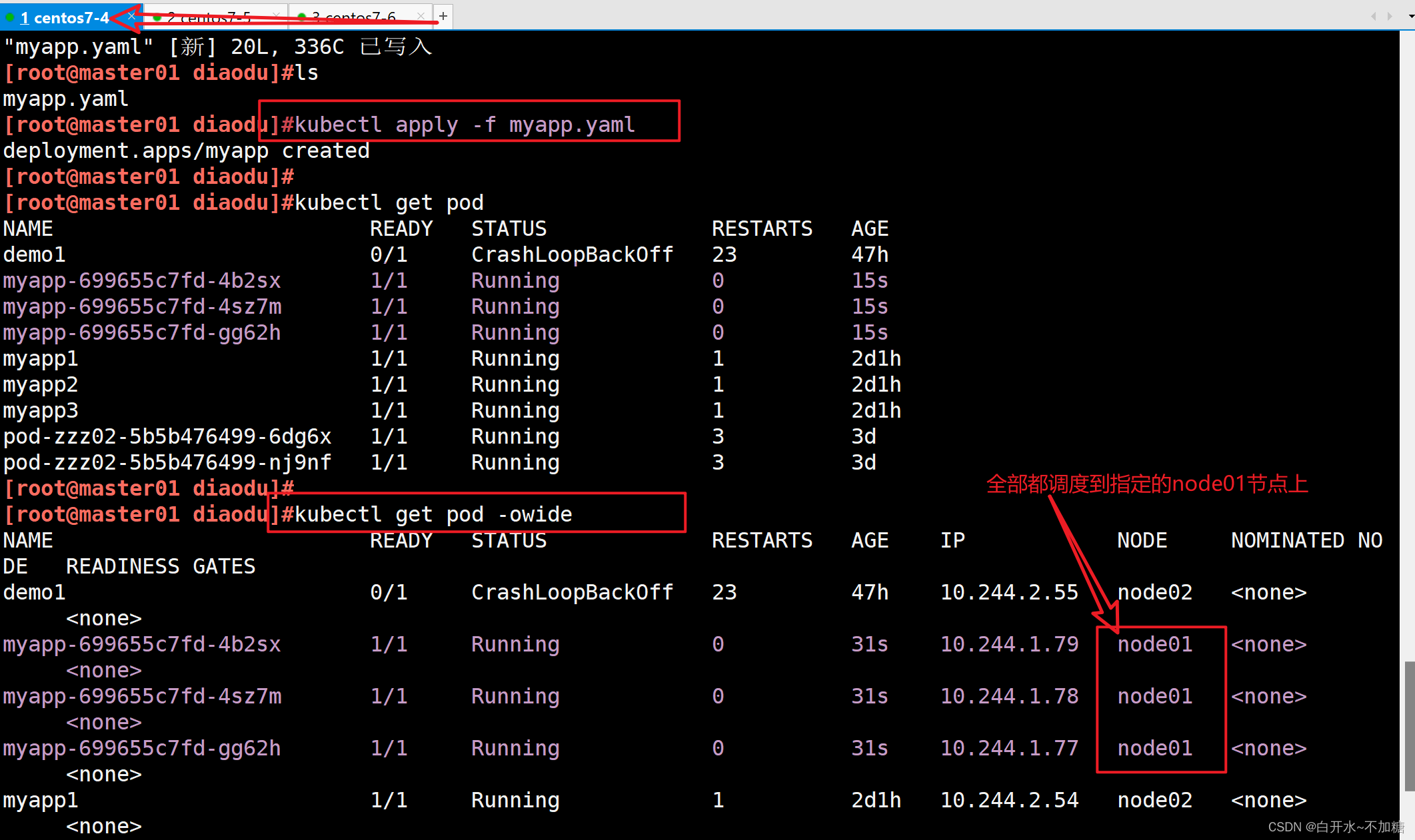
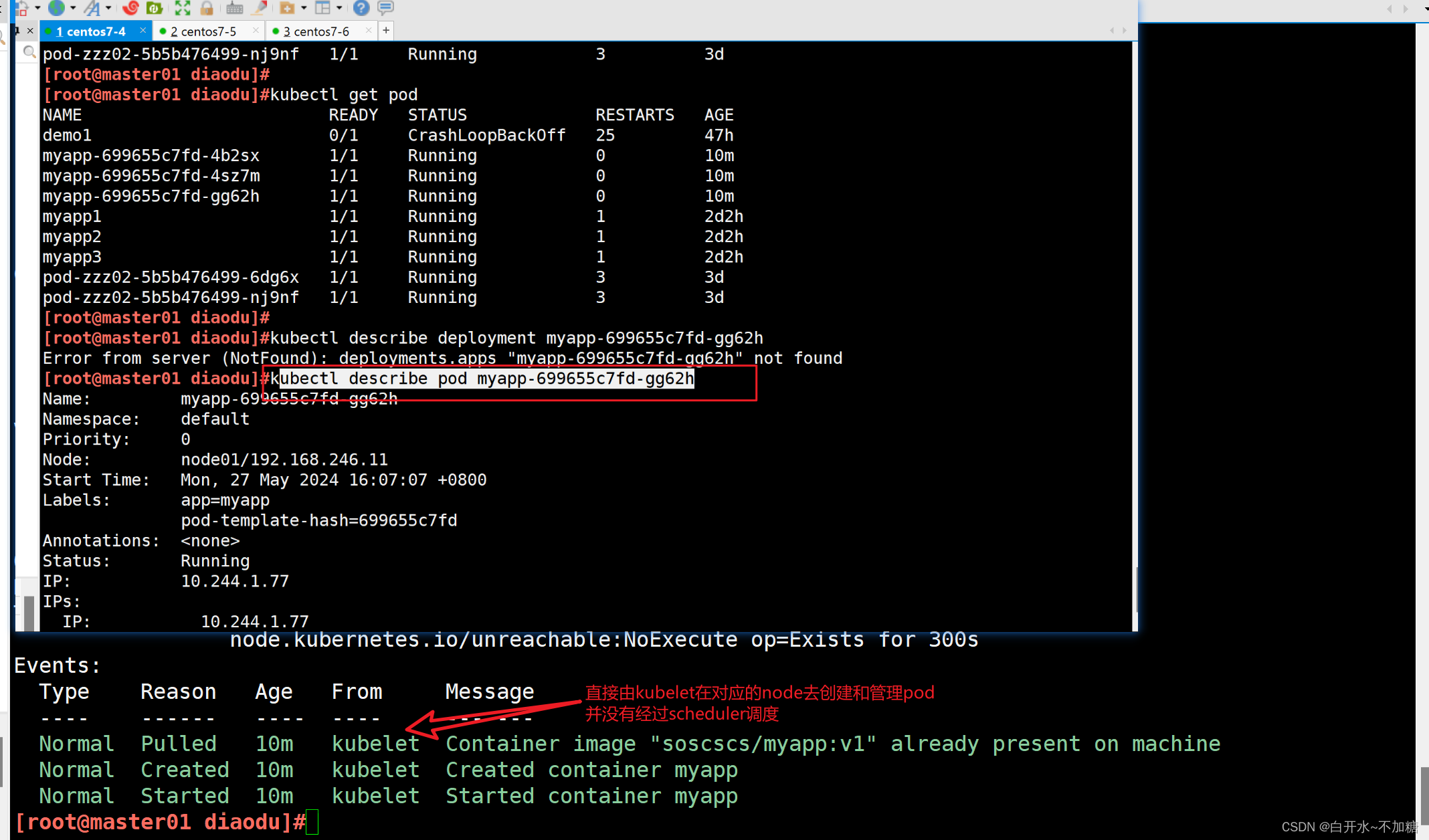

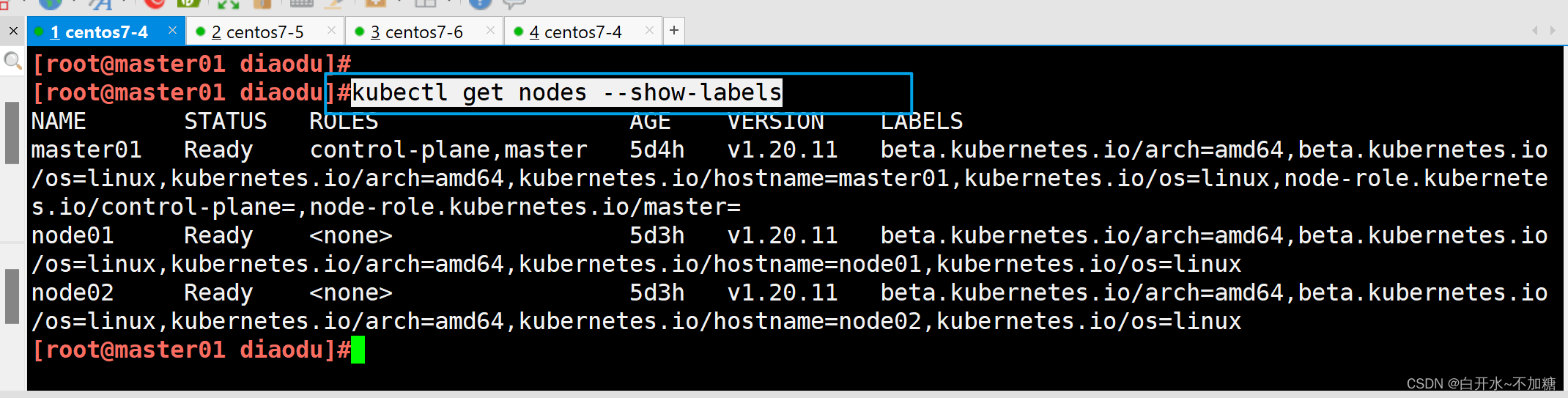









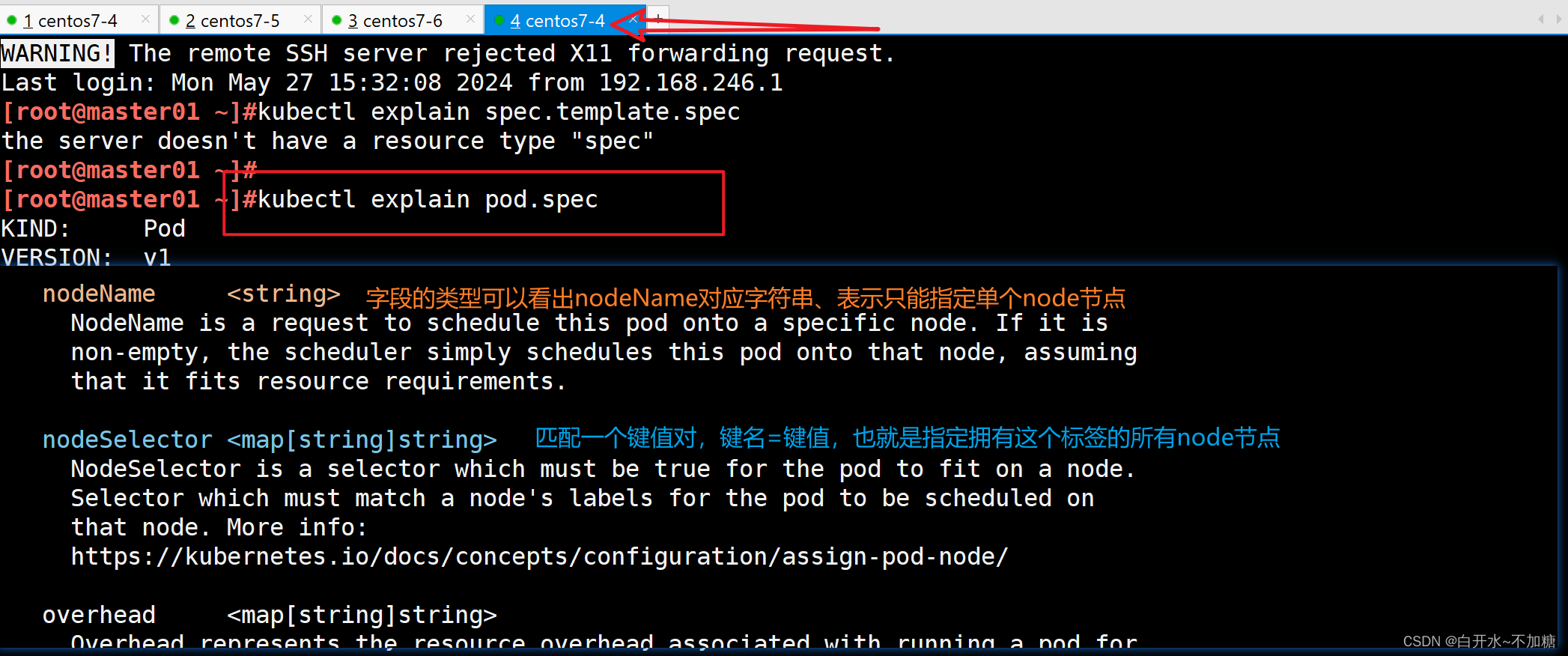
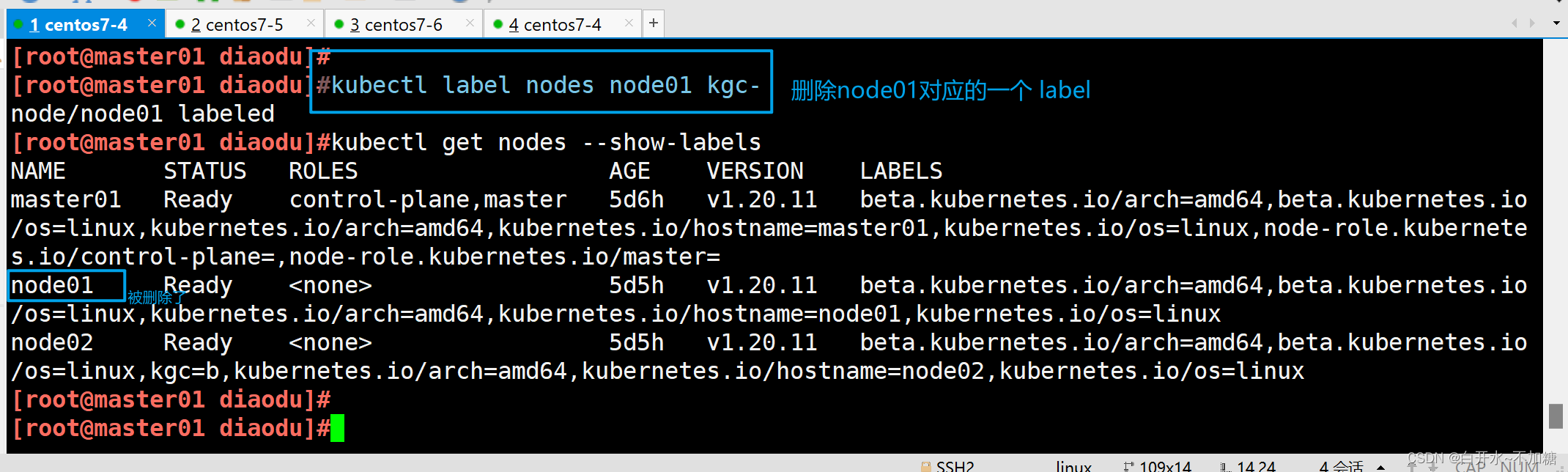


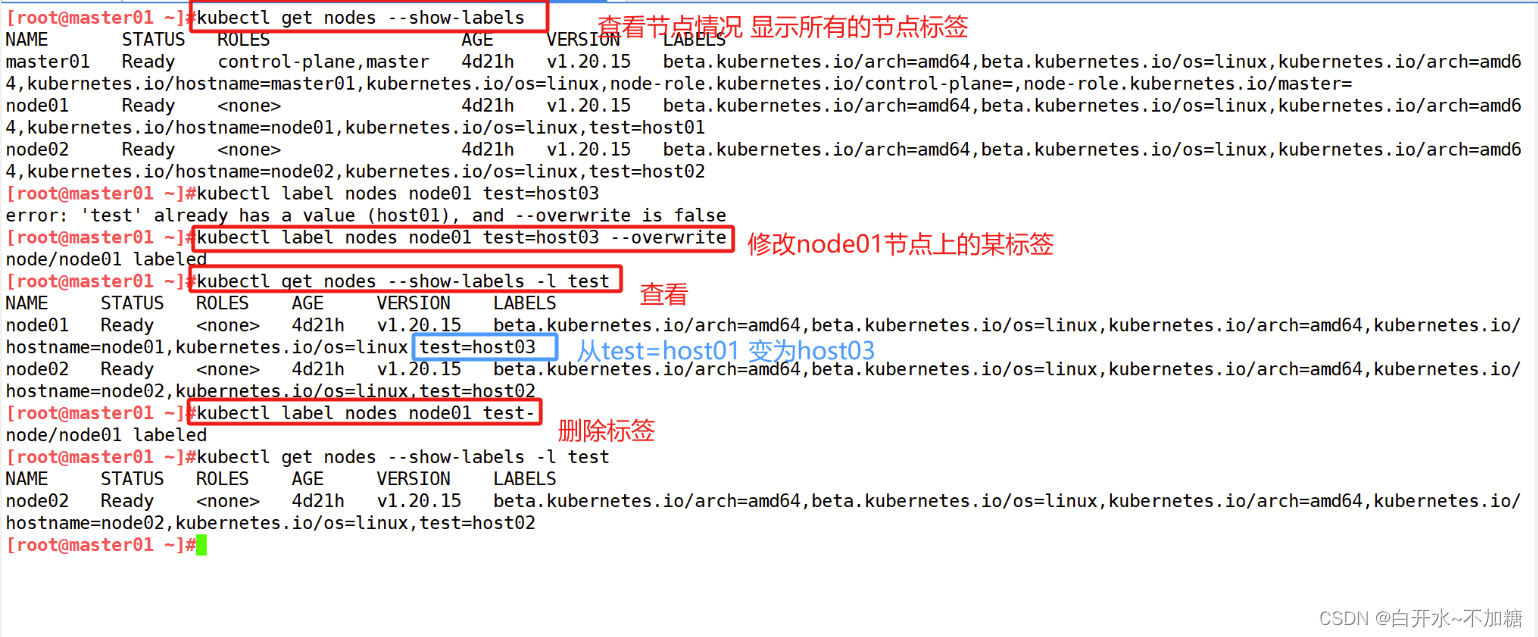
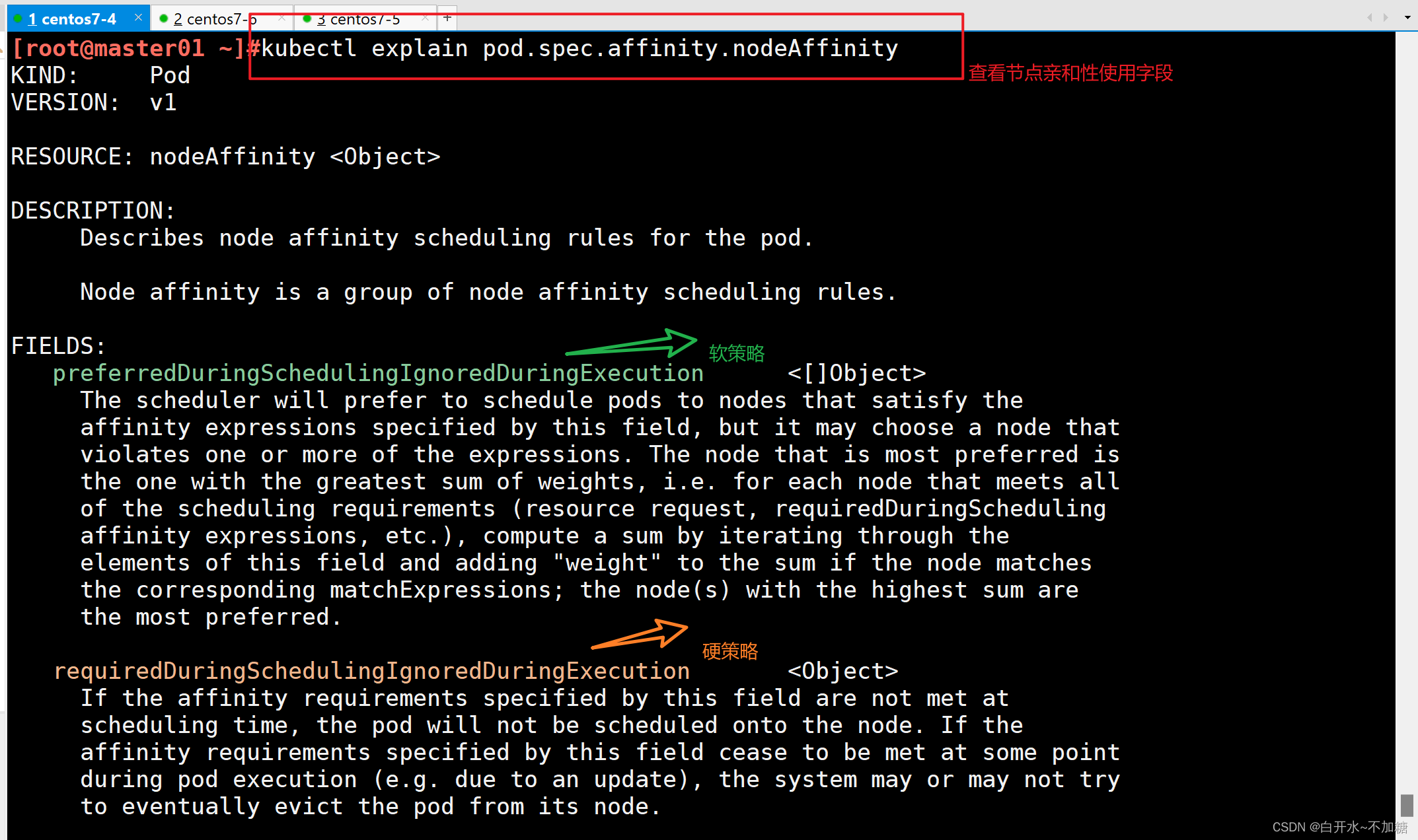




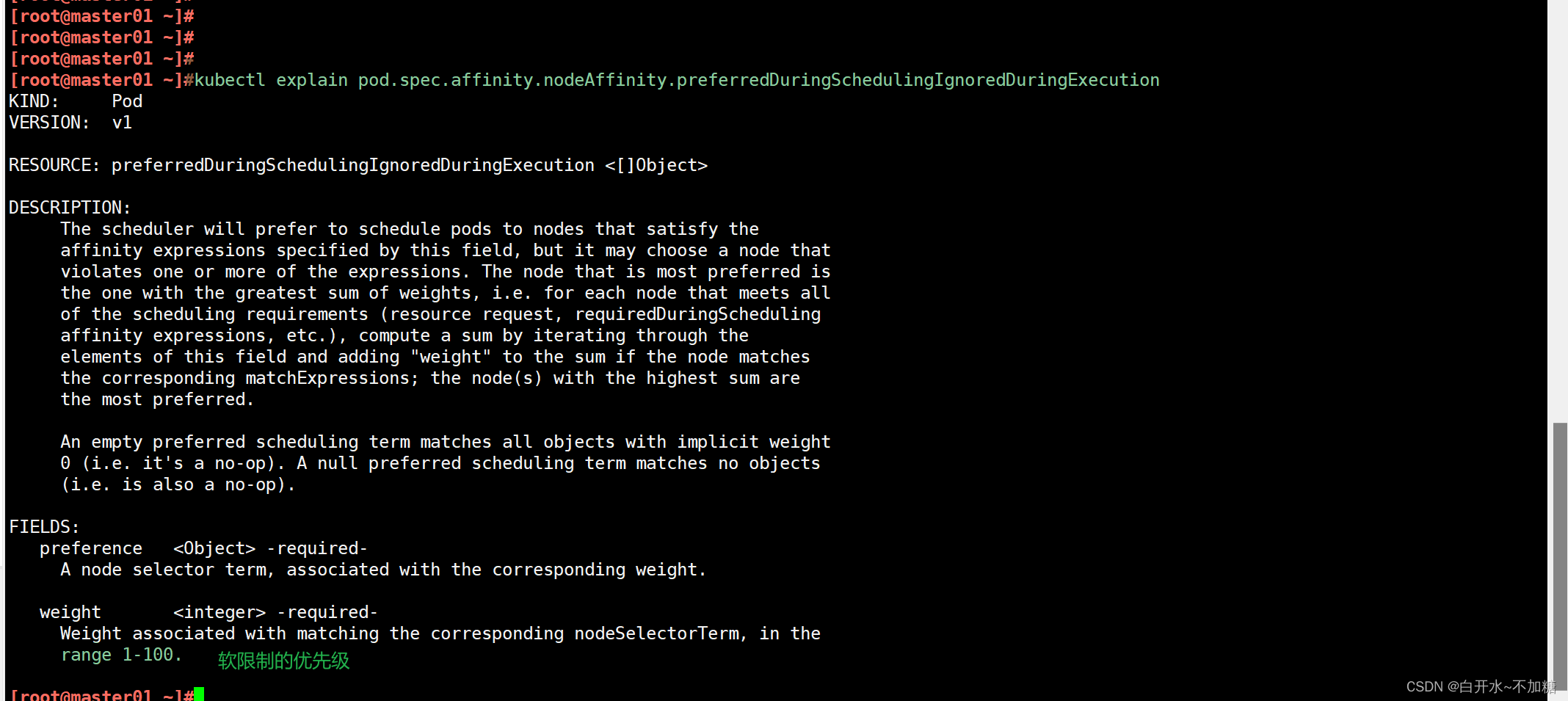
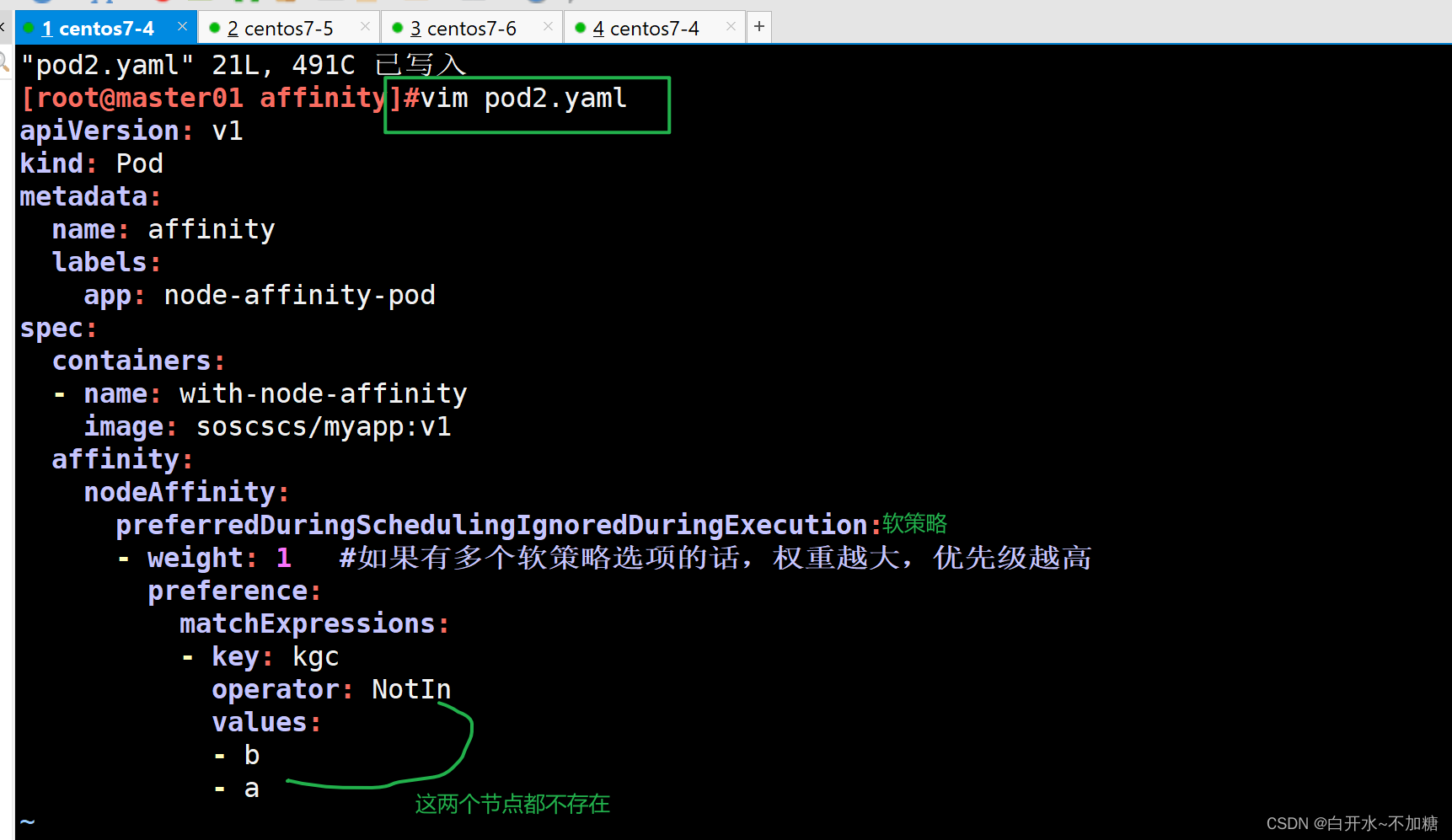


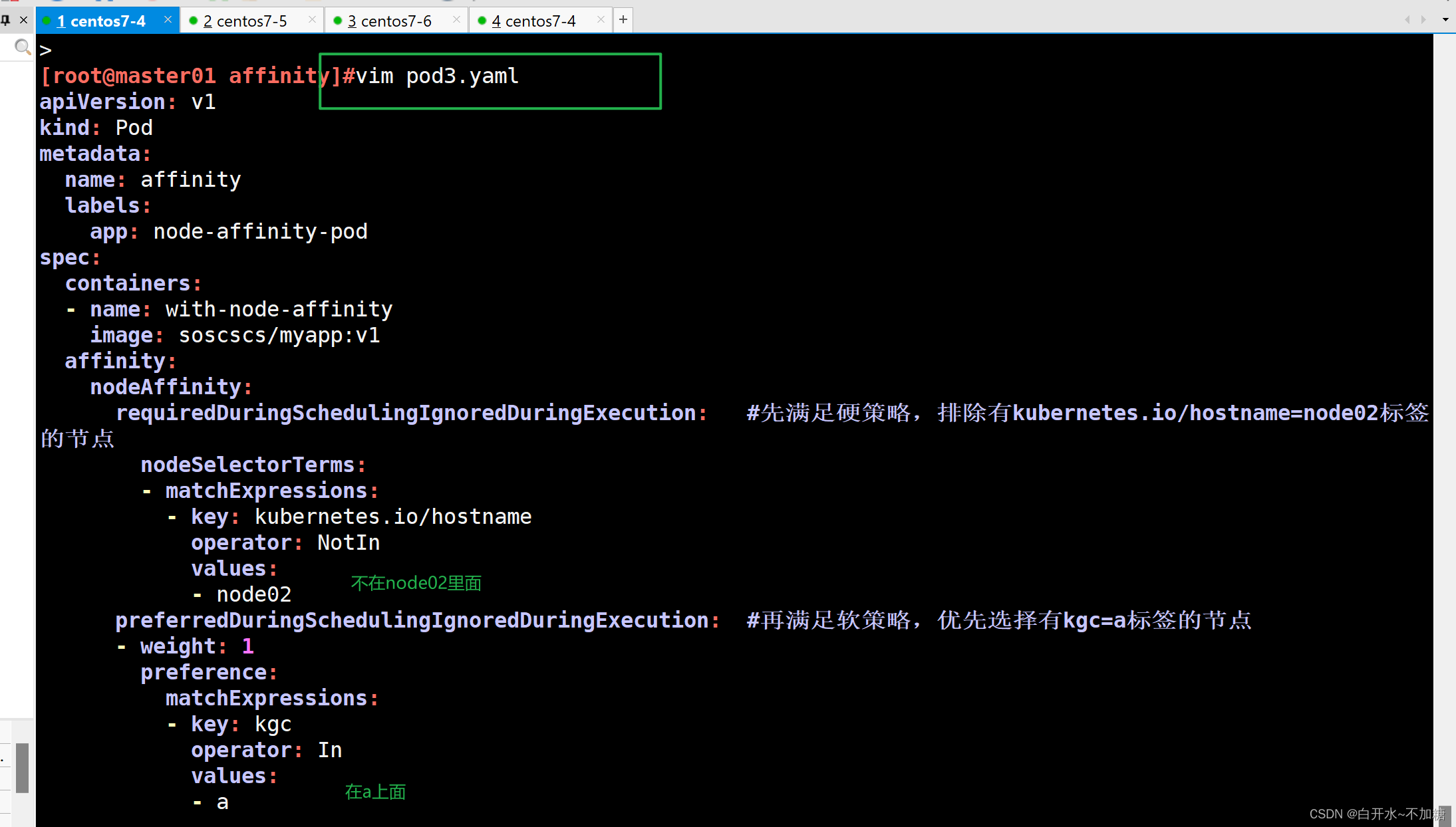
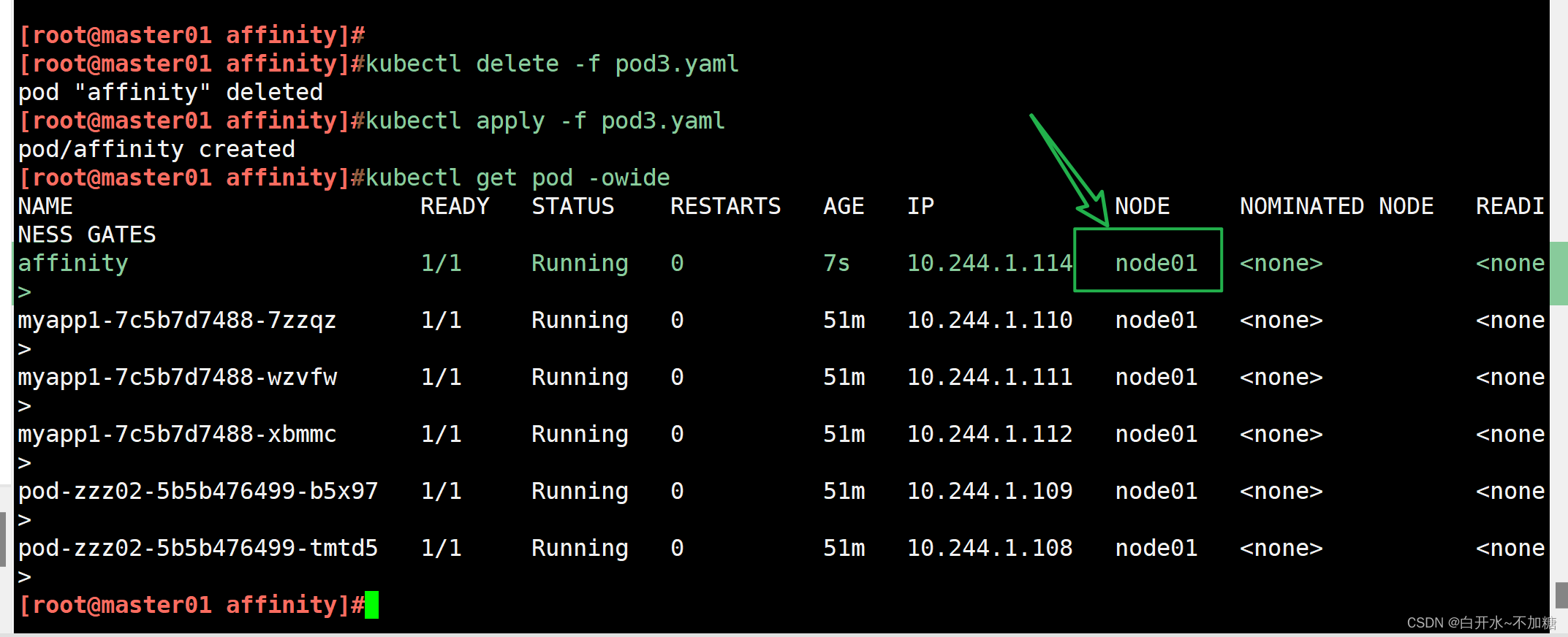



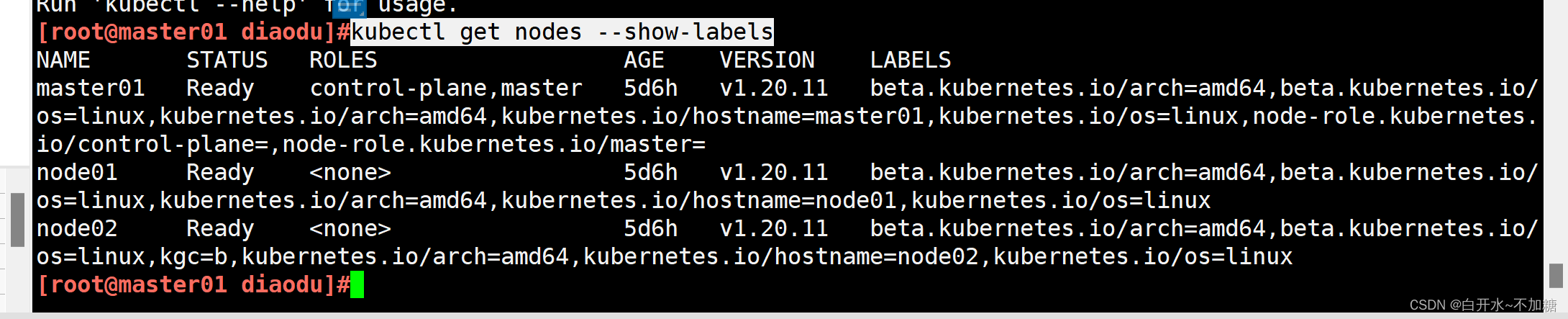
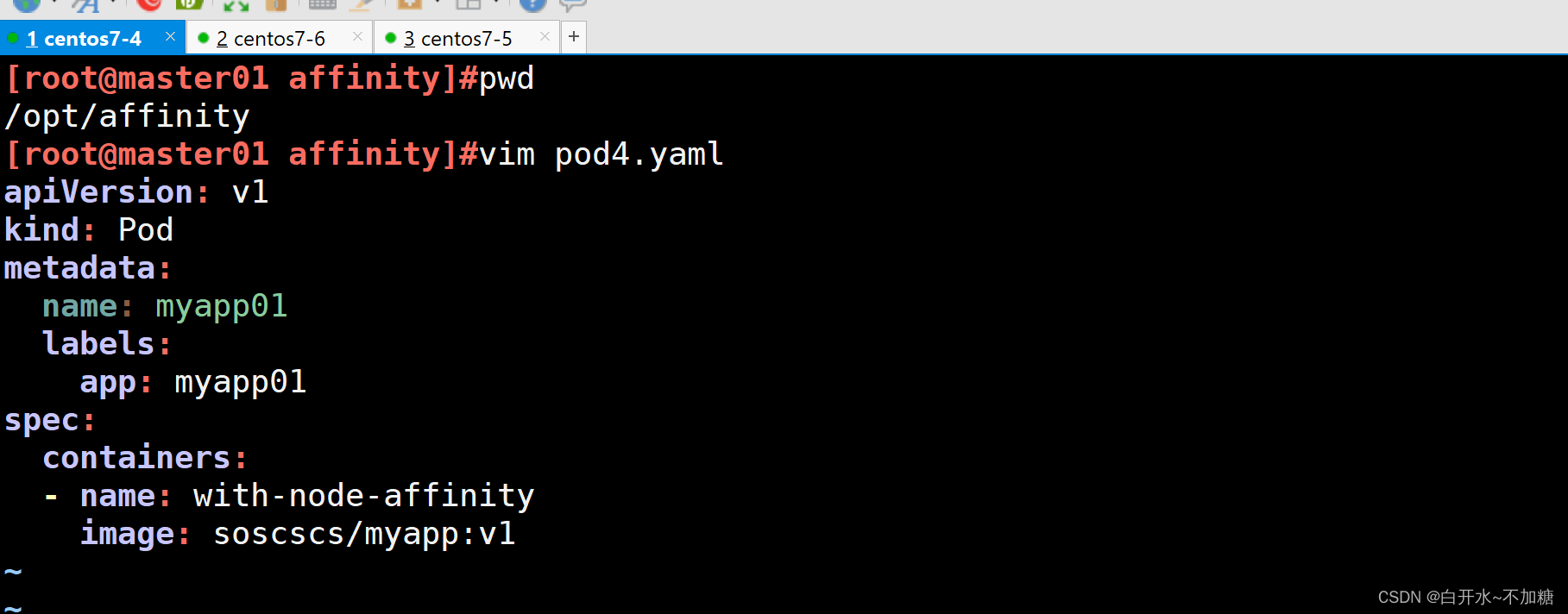
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
| nodeAffinity | 主机 | In, NotIn, Exists,DoesNotExist, Gt, Lt | 否 | 指定主机 |
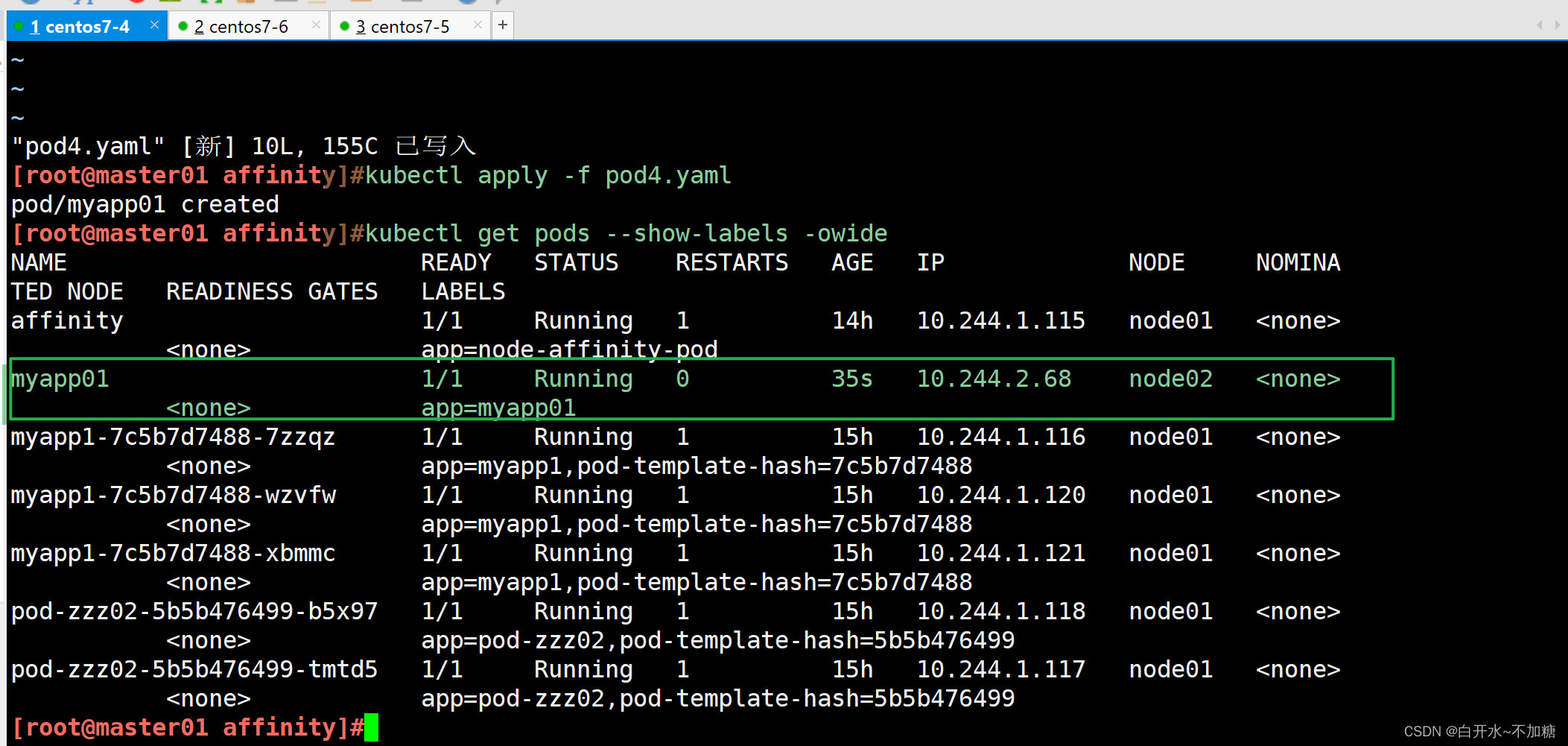
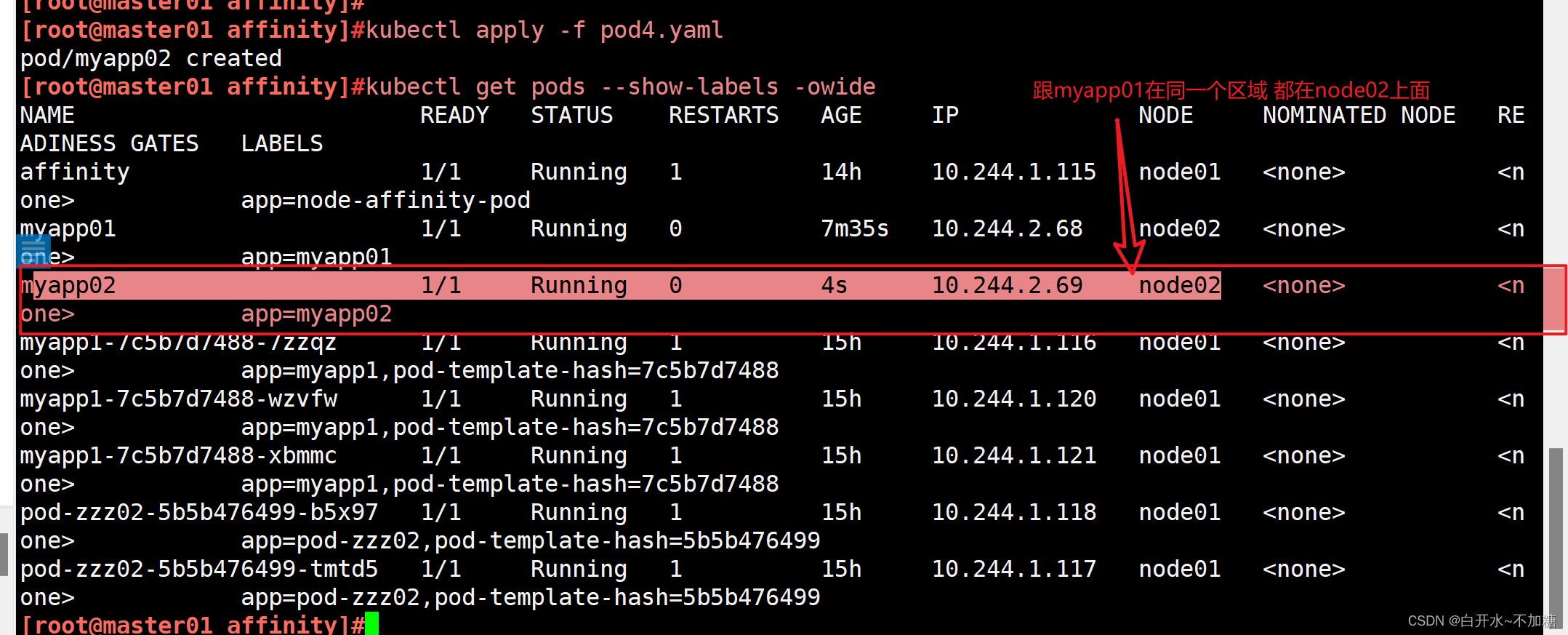
| podAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | Pod与指定Pod同一拓扑域 |
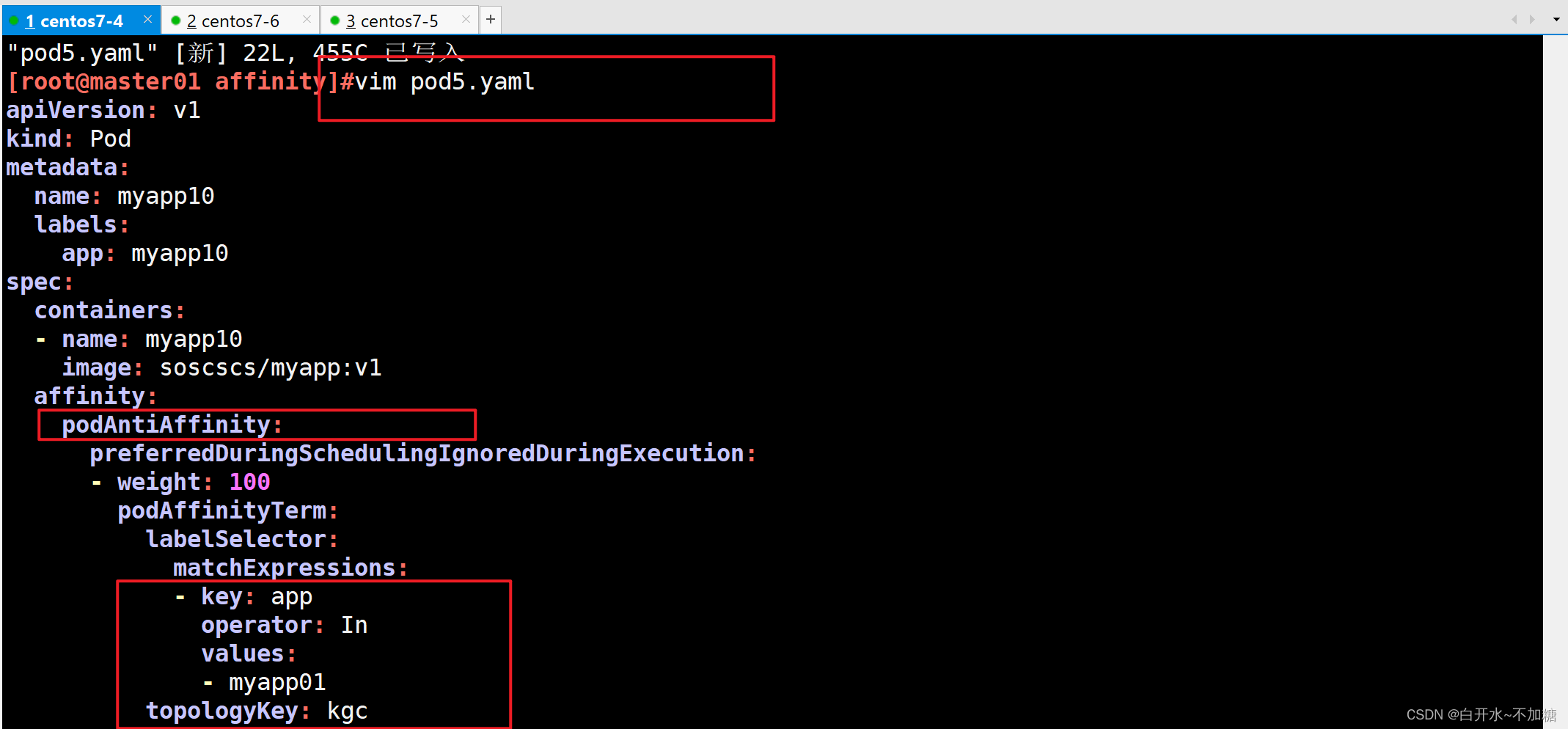
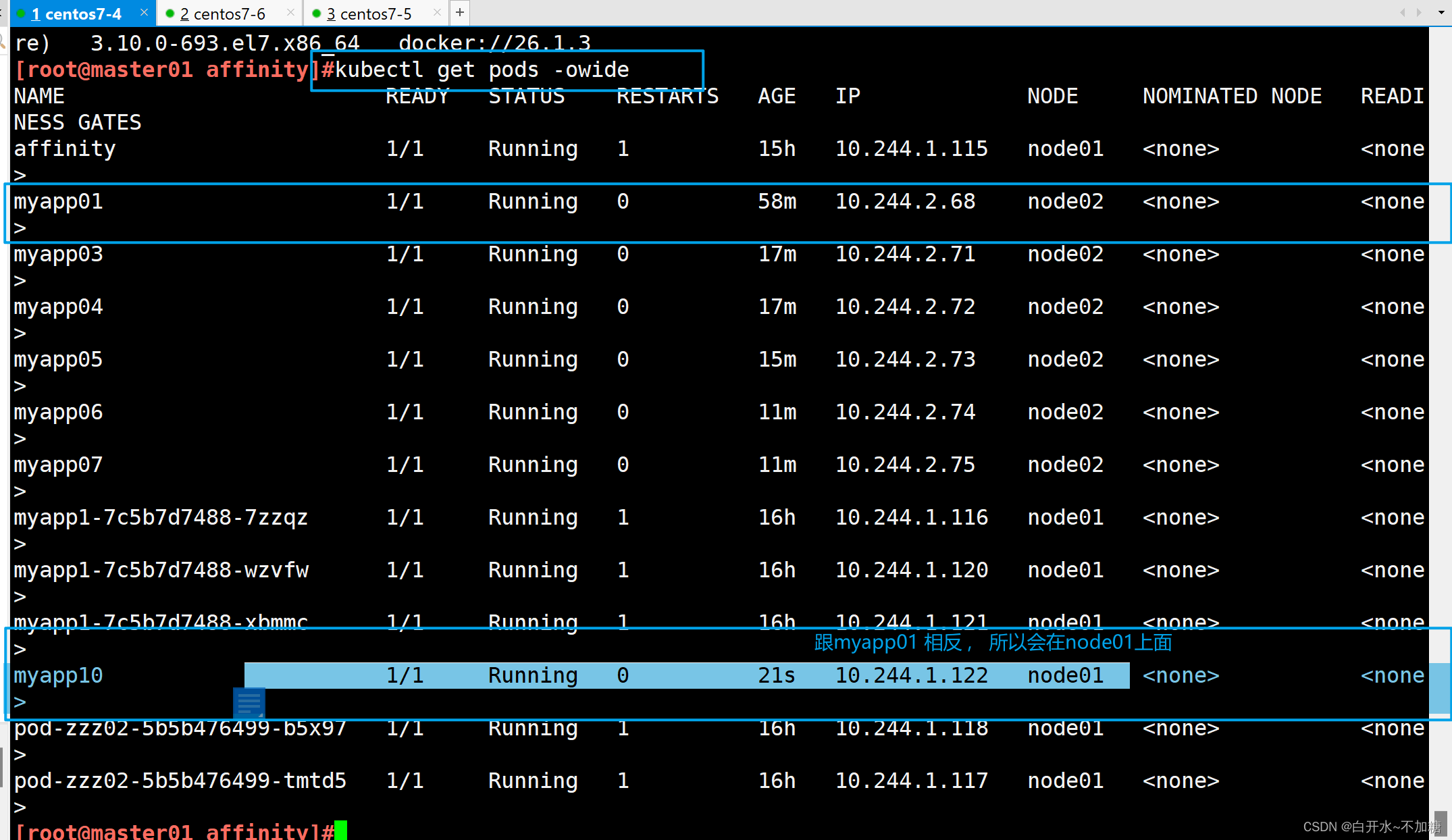
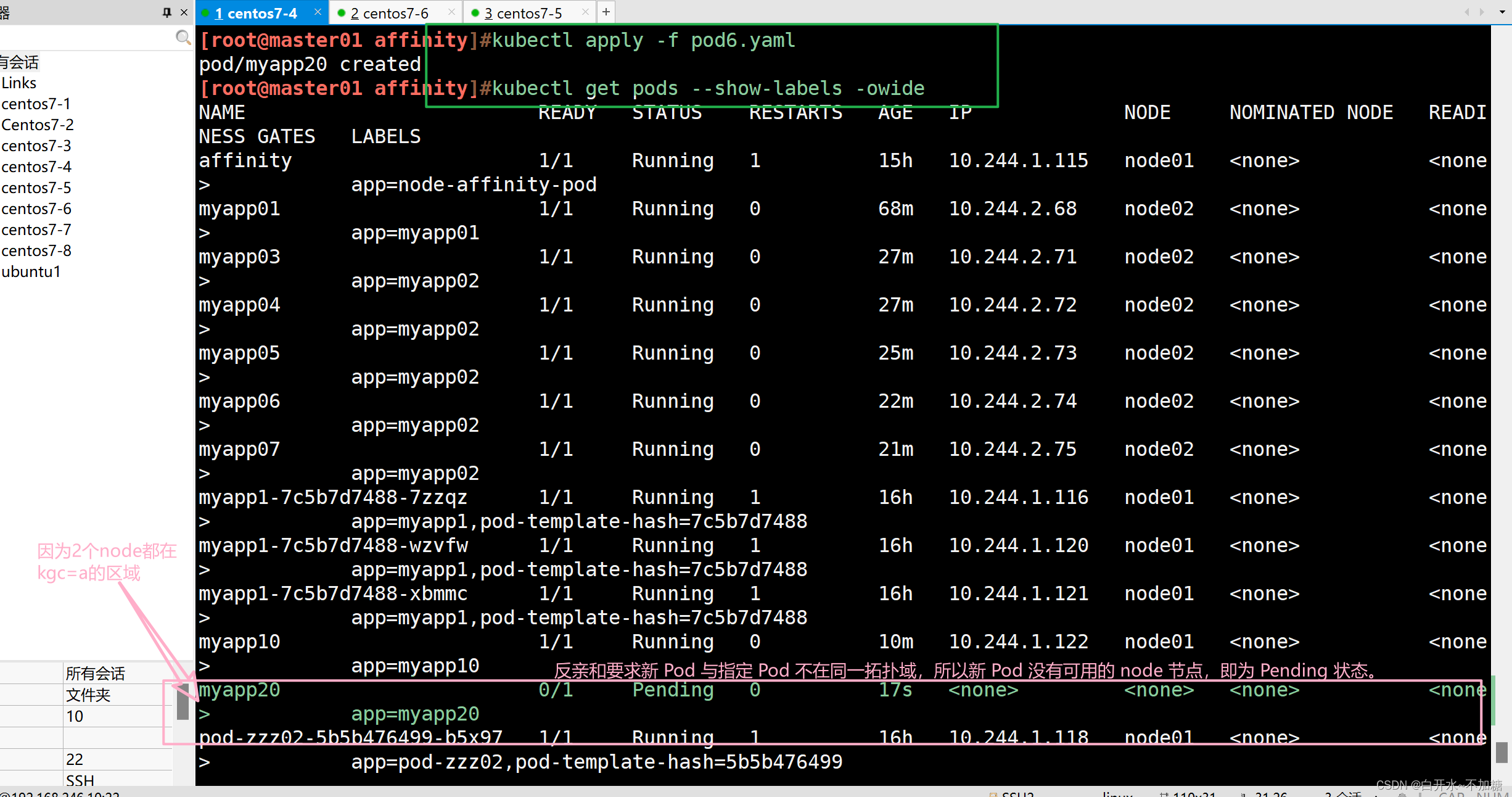
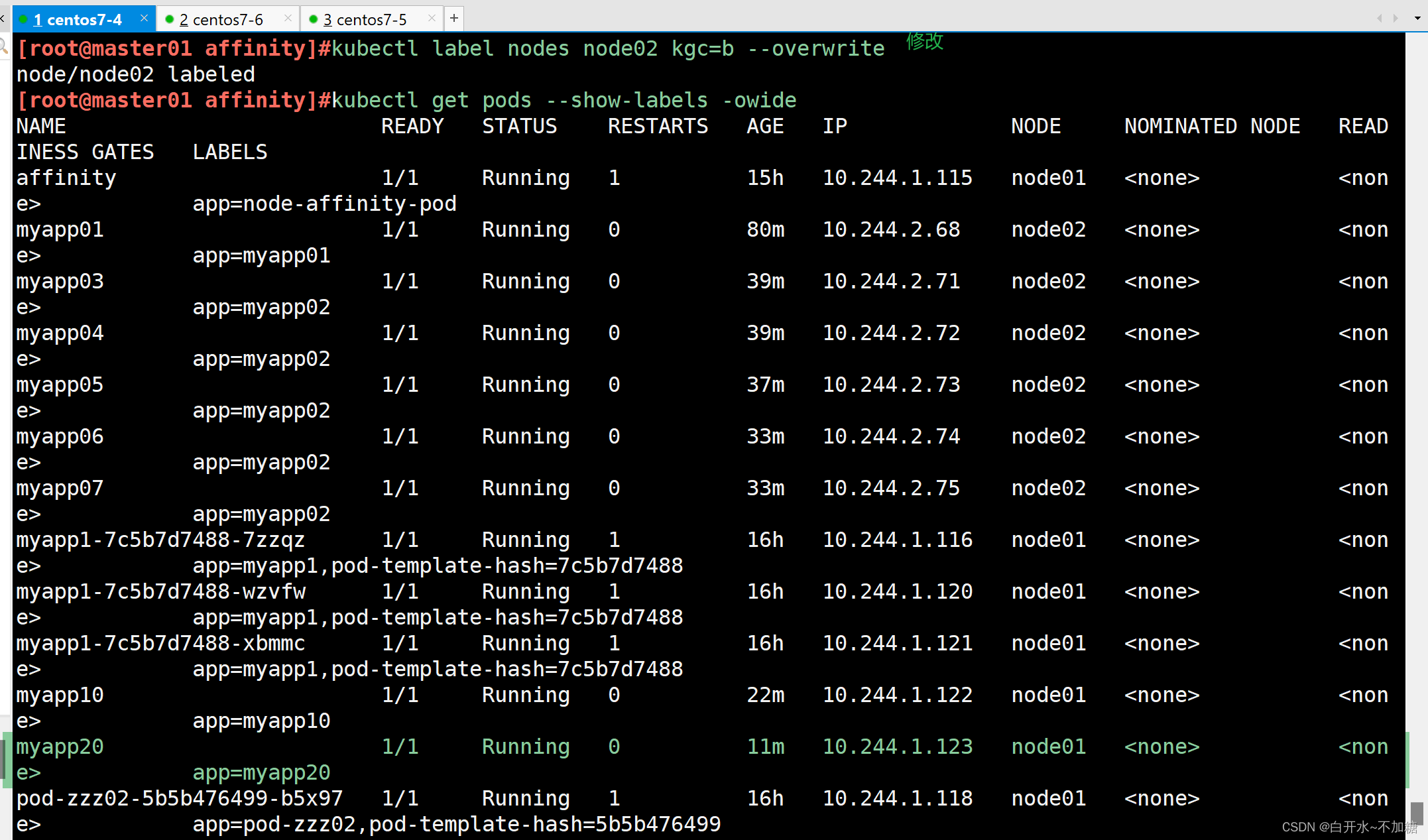
| podAntiAffinity | Pod | In, NotIn, Exists,DoesNotExist | 是 | Pod与指定Pod不在同一拓扑域 |




| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |