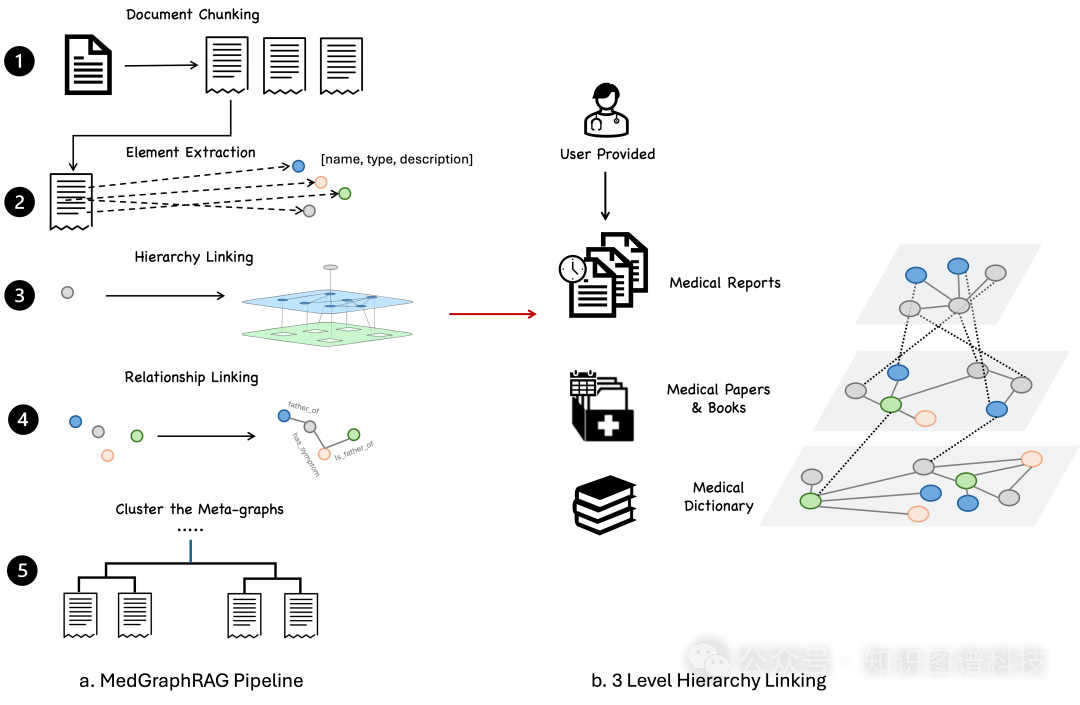
为了提高正确性,我们采用字符分隔与基于主题的分段相结合的混合方法。具体而言,我们利用静态字符(换行符号)来隔离文档中的各个段落。随后,我们应用文本的派生情势举行语义分块。我们的方法包罗使用命题转移,这从原始文本中提取独立语句 Chen et al. (2023)。通过命题转移,每个段落被转化为自给自足的语句。然后,我们对文档举行次序分析,以评估每个命题,决定是与现有块归并还是启动一个新的块。这个决定是通过LLM的零样本方法来做出的。为淘汰次序处置惩罚天生的噪声,我们实施滑动窗口技能,每次处置惩罚五个段落。我们不断调解窗口,通过移除第一个段落并添加下一个段落,保持对主题一致性的关注。我们设置一个硬阈值,最长的块不能凌驾LLM的上下文长度限制。在对文档举行分块后,我们在每个数据块的个体上构建图谱。
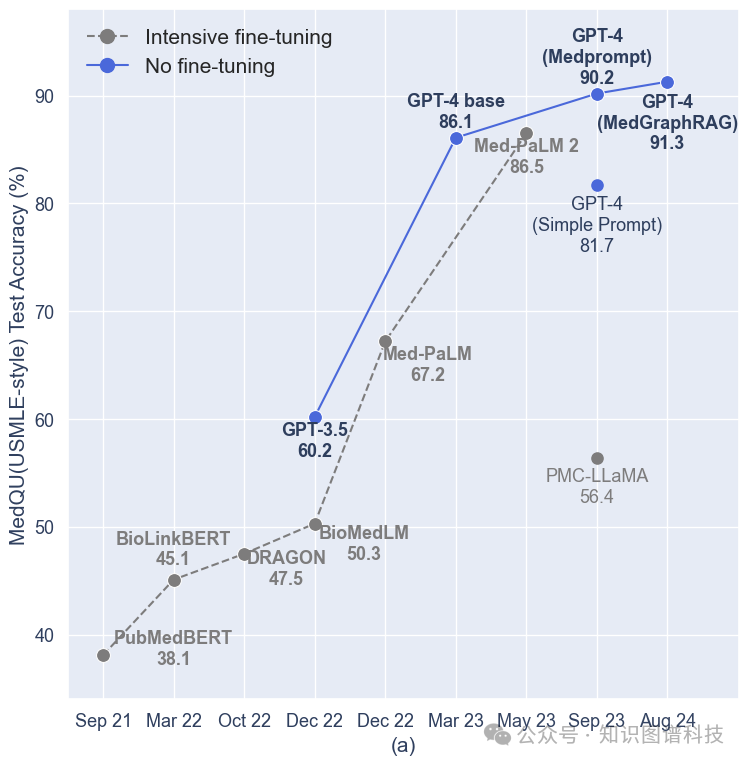
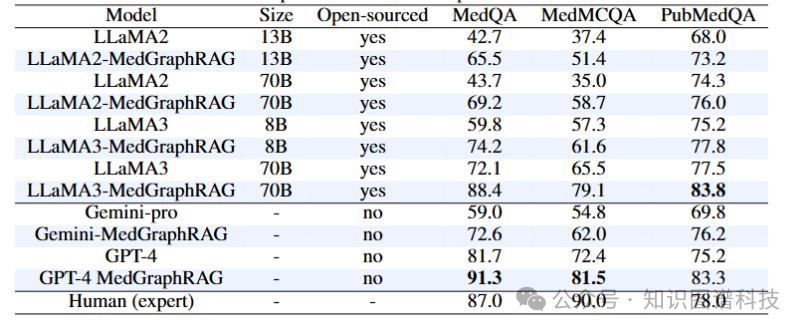
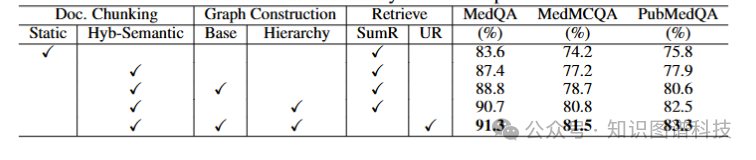
我们举行了全面的溶解研究,以验证我们提出的模块的有效性,效果如表2所示。本研究比力了多种文档切分、层次图构建和信息检索的方法。具体而言,在文档切分方面,我们评估了我们的混合静态-语义方法与纯静态方法的对比。在层次图构建方面,我们将我们的方法与LangChain中使用的基本构建方法举行了对比。在信息检索方面,我们将基于摘要的检索方法Edge et al. (2024)与我们的U-retrieve方法举行了比力。这些方法是在先条件到的三个问答基准上举行评估的。