ToB企服应用市场:ToB评测及商务社交产业平台
标题:
信也科技基于 Apache SeaTunnel金融场景的应用实践探索
[打印本页]
作者:
宁睿
时间:
2024-9-6 20:00
标题:
信也科技基于 Apache SeaTunnel金融场景的应用实践探索
媒介
作者:朱俊,信也科技,数据开发专家
离线开发不停是数据堆栈建设中紧张的一个环节。信也科技之前基于Azkaban构建了离线任务调度与开发平台,承载了公司
90%以上的离线任务调度需求
,以及玄策变量平台的每日变量跑批产出任务。
随着时间的积累,任务量级越来越大,Azkaban
难以运维与二次开发等题目日渐凸显
,给技能同学带来不小的负担。
从2023年下半年开始,借助内部创新项目标机会,开展了调度体系引擎升级的项目立项与调研,渴望在新调度体系的基础上,进一步规范
任务开发流程,进步运维服从,简化全链路血缘
的获取和维护。
在历时大半年的探索与落地过程中,调研了Apache DolphinScheduler与内部自研调度体系DataCloud之后,考虑到公司实际环境与用户使用风俗,终极决定在自研调度体系DataCloud的基础上,鉴戒Apache DolphinScheduler的架构思想与插件式设计理念,打造全新的调度引擎,并推出全新的一体化
离线任务开发运维平台——千帆
。
终极千帆平台乐成在生产环境上线,并开始推动汗青任务的迁移与迭代工作。
在调研Apache DophinScheduler的过程中,深刻领会了海豚调度结合Apache SeaTunnel打造
数据抽取→任务开发→数据推送一体化流程
的便捷性与实用性,对DevOps理念在数据工程中的应用也加深了一些明白和熟悉。
考虑到内部对于数据推送和互导这一场景依然存在着不少的痛点和题目,因此在千帆平台落地的过程中,经过技能选型与调研,
决定采用Apache SeaTunnel框架
来统一赋能数据集成与推送场景。
现状
在公司发展早期,由于快速迭代等缘故原由,很多内部体系都带有差别程度的数据推送能力。
这种烟囱式的开发固然带来了灵活适配,快速上线等利益,但随着业务不停成熟,
也渐渐呈现一些毛病
,比如多个平台自成体系,增加了全链路血缘建设的复杂度;权限难以打通与统一管理。
另一方面,作为数据开发的焦点调度引擎,Azkaban专注于调度本身,
并没有集成数据抽取,数据推送等功能
,须要数仓同学自行开发任务脚本实现这类功能,增加了开发本钱,且复用性不高。
鉴于这两个缘故原由,渴望在千帆里集成统一的,配置化的推数功能,来收口这些分散的推数场景。
以下是我们之前的架构
从上图可以看到,各种内部平台到各式各样的目标存储体系之间,存在
多种操纵数据导出的方式或者工具
,这些汗青遗留题目为后续的开发带来了一些未便之处。
痛点
(一)全链路血缘难打通
过去,由于推送任务分散在各个体系当中,当上游的离线计算任务数据质量出现题目的时候,各个下游依赖该张离线表产出任务的推送任务无法及时感知数据质量题目,进行阻断或者重跑。
这就导致了数仓同学发现某张离线表数据有题目而重刷了当天禀区数据时,须要泯灭较长的时间来查下游哪些推数任务须要进行重跑,是一个
不小的运维负担
。
理论上我们可以开发一个统一的血缘服务来汇总每个体系的血缘数据,构建跨体系的全链路血缘。
但是这须要去明白和统一差别体系的元数据,带来较高的开发本钱,倒霉于数据管理工作的开展。
(二)推送框架难统一
由于汗青缘故原由,基于Azkaban的调度平台固然能满足离线调度的需求,但是Azkaban是以command为任务运行的最小单元,每个command实际上一个或多个shell脚本的功能集合,这就造成了基于Azkaban的任务类型难以划分,同样的功能大概会复用差别的shell脚本,每个脚本对于开发运维同学来说都
相称于一个黑盒
,须要熟悉其中的逻辑才能把控。
我们在做千帆早期的设计和开发,想对接Azkaban时,就面临如许的题目。为了适配Azkaban底层的差别运行脚本,须要不停的在产品设计上增加Case来满足各种自定义脚本的参数和逻辑分支,来适配推送差别存储(如Mongo和StarRocks)的作业。
而对于其他拥有推送功能的体系来说,由于设计开发的人员差别,整体架构和使用场景差别,也会选择差别的实现方式来完成数据推送(比如采用impala JDBC、MapReduce等实现方式),这就造成了同质化的功能采用差别的技能实现,
不但维护难,出了题目也较难定位,且无法采用统一的产品设计逻辑来覆盖公司内部的业务场景。
(三)推送任务监控与管理难实现
上述题目造成了数据计算流程和数据推送流程之间的割裂,本来
数据抽取-数据计算-数据推送
应该在逻辑上是一个整体,现在须要开发人员分散地行止理。
当涉及到
权限,验数,链路排查
等题目时,这种一来二去带来了时间和沟通上的本钱。
同样由于实现方式的不统一,对于推送任务的服从和断点续传、Checkpoint、流控、监控Metric等高级功能,难以给出统一的实现方案,倒霉于整体的数据管理。
技能选型
在新体系调研开发过程中,我们对数据集成底层框架进行技能选型时,参考了其他公司在落地实践中的经验,我们认为针对我司的场景,须要从以下几个关键点来进行权衡:
性能:
数据集成框架须要具备高吞吐、低耽误、可观测的特点
安全摆设:
金融场景须要考虑数据的安全性,因此集成框架摆设依赖的其他组件越少越好,摆设环境与流程简朴,易于维护
易用性与扩展性:
数据集成框架应具有精良的扩展性和架构设计,易于针对个性化场景进行二次开发
社区生态:
数据集成框架应支持多种数据源和目标存储,社区活泼度高,拥有丰富的User Case
我们观察了一些较为流行的开源工具,主要集中在使用较为广泛的DataX、Sqoop、SeaTunnel。
以下是这三款产品的横向对比
对比项Apache SeaTunnelDataXApache Sqoop运行模式分布式,支持单机单机非分布式框架,依赖Hadoop MR实现分布式容错机制无中心化高可用架构,容错机制完善易受网络、数据源等因素影响MR模式容错处理惩罚未便摆设难度轻易轻易依赖Hadoop集群摆设支持数据源丰富度超过100种数据源20+种数据源只支持几种数据源自动建表支持不支持不支持断点续传支持不支持不支持单机性能很好较好一般可扩展性易扩展易扩展扩展性较差统计信息有有无与调度体系集成与DophinScheduler集成,也支持集成到其他调度体系不支持不支持社区非常活泼,乐成案例多一般已从Apache退役 结合上面的横向对比(部门参考了社区用户实践经验与官方文档)结论,基于我司的现状和痛点,综合考虑架构设计先辈性、灵活性、摆设运维本钱、社区活泼度等方面,我们终极选择了Apache SeaTunnel作为底层框架来统一任务推送与导出的流程与场景。
实践过程
在调研和落地过程中,我们基于
SeaTunnel 2.3.4版本
,主要做了以下一些适配和改造,以满足公司内部的导数场景和需求
(一)扩展Sink插件
支持PMQ
在2.3.4的基础上,我们扩展了connector-pmq模块,以接入公司内部的消息队列中心件PMQ。
PMQ是信也科技自研的一款消息体系中心件,在公司内部有广泛应用,支持了信贷业务各条线的消息传输与上下游数据链路,支持PMQ打通了数仓到业务体系的最后一环,实现了数据赋能业务的最后一公里。
支持跨集群HBase Kerberos认证
公司已有的一些业务平台依赖于自建的HBase集群存储,与数仓的大数据集群是两套体系,之前由于Kerberos认证的题目,难以从数仓的Hive表将离线计算结果写入业务平台的HBase集群,须要改造一个MapReduce程序去实现跨集群的Kerberos认证,增加了数仓开发同学的维护本钱。
千帆平台在SeaTunnel 2.3.4版本的Connector-HBase模块上增加了对Kerberos认证的支持(复用了Connector-file-base-hadoop模块中对Kerberos相关的Config),实现了配置化天生任务读取Hive表跨集群导入标签平台的业务需求,现在这块后端已经实现,产品设计交互和前端页面操持在下个迭代支持。
数据传输流程优化
在信也科技,有一些离线数据经过内网专线跨机房传输的需求,过去由于没有统一的平台工具支持,往往是数据开发同学产出离线报表且验证无误之后,通知下游研发同学进行数据传输任务的启动。
由于数据跨机房传输对于数据质量和网络传输速率都有一定的要求,且有一些特定的处理惩罚逻辑,因此当传输失败或者数据错误时,往往须要研发同学人工参与,维护本钱较高,且无法做到流程自动化。
考虑到为减少人工维护本钱,我们也在积极与数据开发和研发同学沟通需求,通过SeaTunnel来支持这一业务场景,现在整个研发方案在沟通与设计中,操持在未来的版本上线。
(二)千帆平台支持推送任务类型
过去,基于Azkaban调度构建的离线开发平台产品(千帆前身),在功能上很难构建统一的推送任务,内部实现较难解耦,且完全依赖用户自己编写的汗青脚原来实现。
当其他平台的用户想要迁移到千帆平台时,往往面临着较高的本钱,须要将ETL的流程迁移到多个体系上来支持。
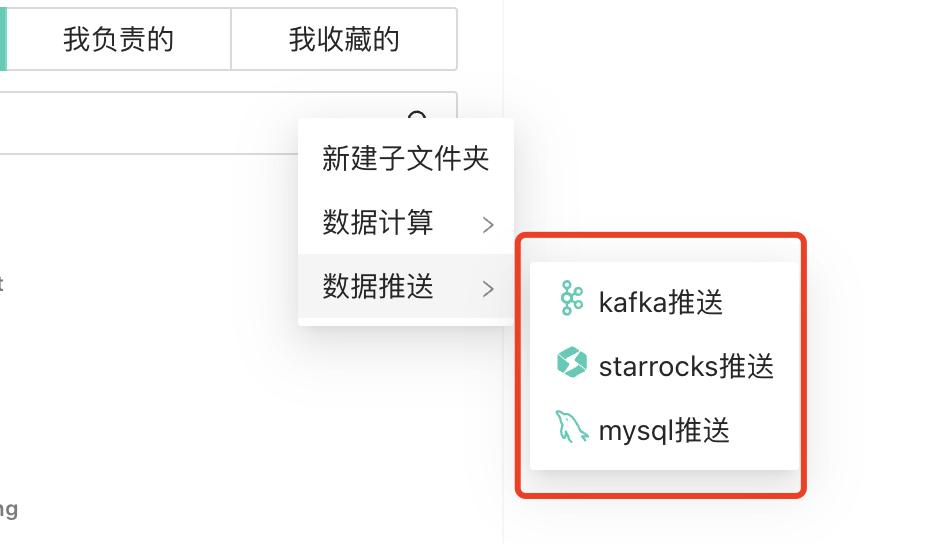
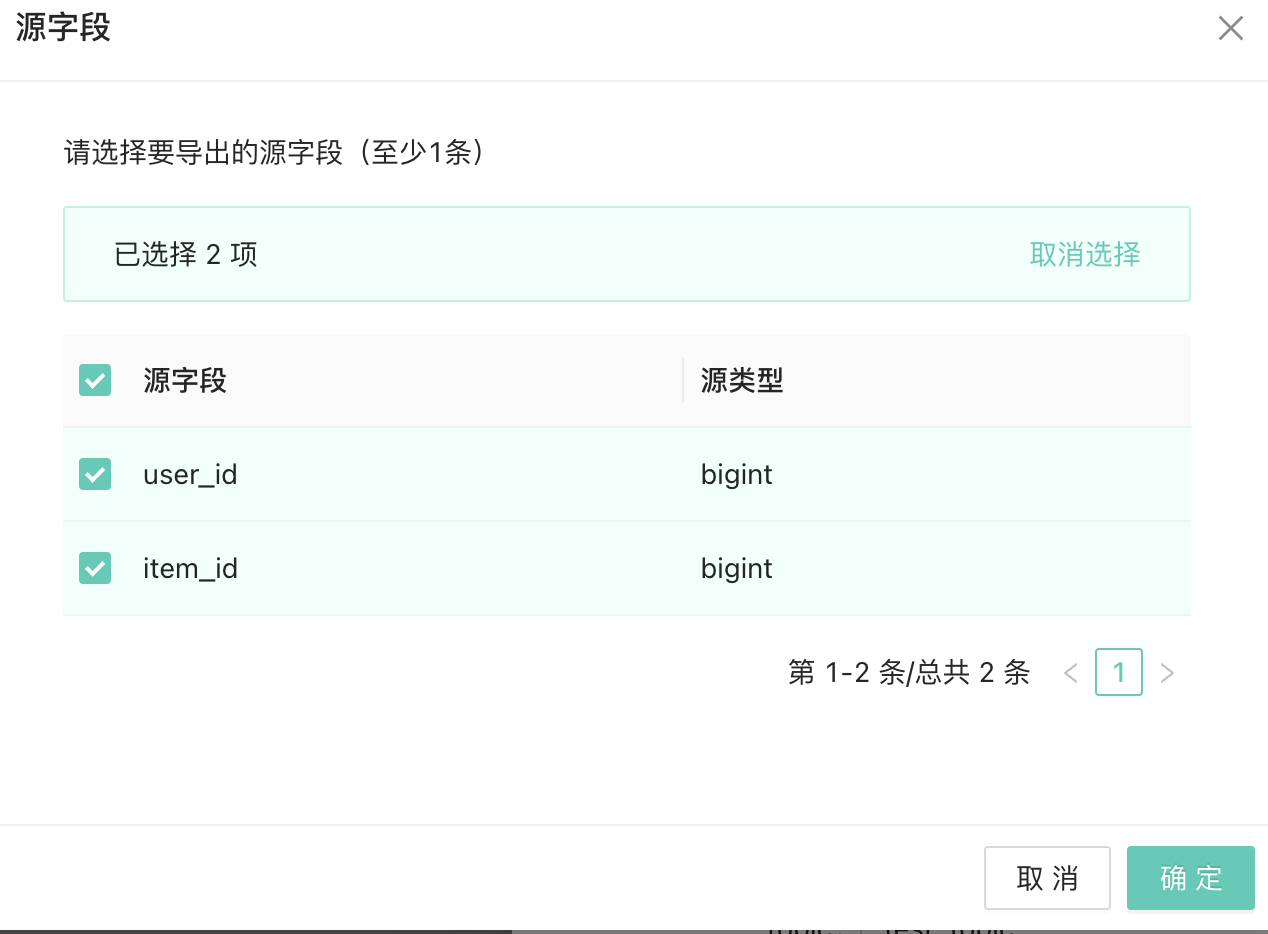
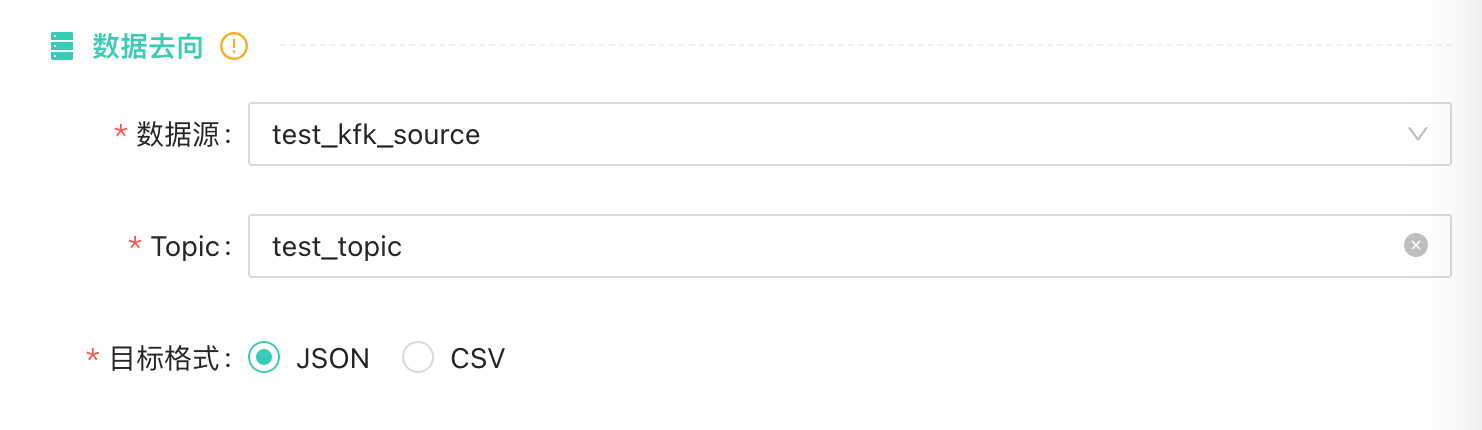
在新的千帆平台上,我们重构了推送任务体系,并且支持了
Kafka、StarRocks、MySQL、PMQ(内测中)
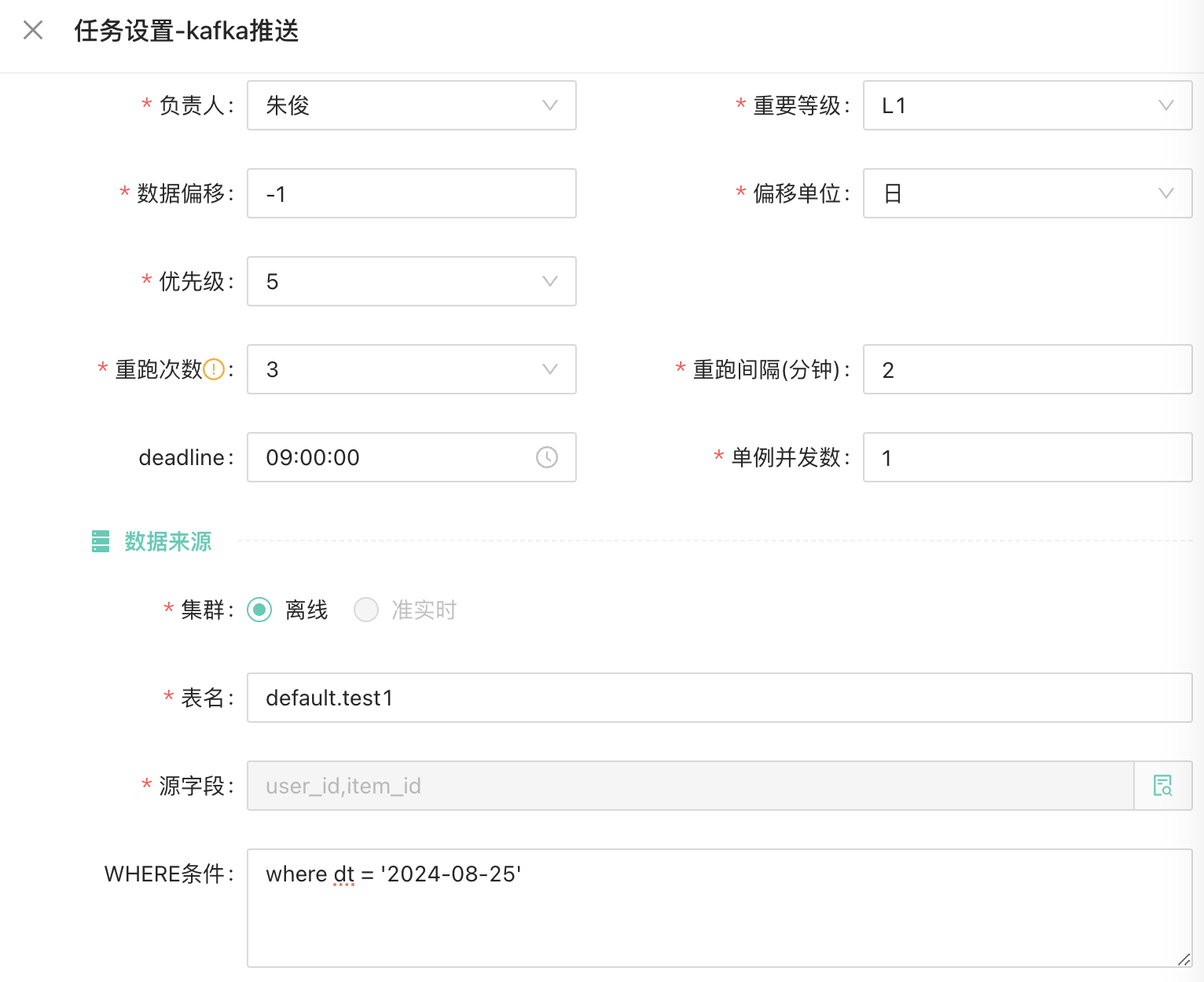
这几个任务类型,并实现了页面配置化到任务摆设生产、实例运维的CI/ CD流程,以下是我们产品的一些交互设计:
阶段成果
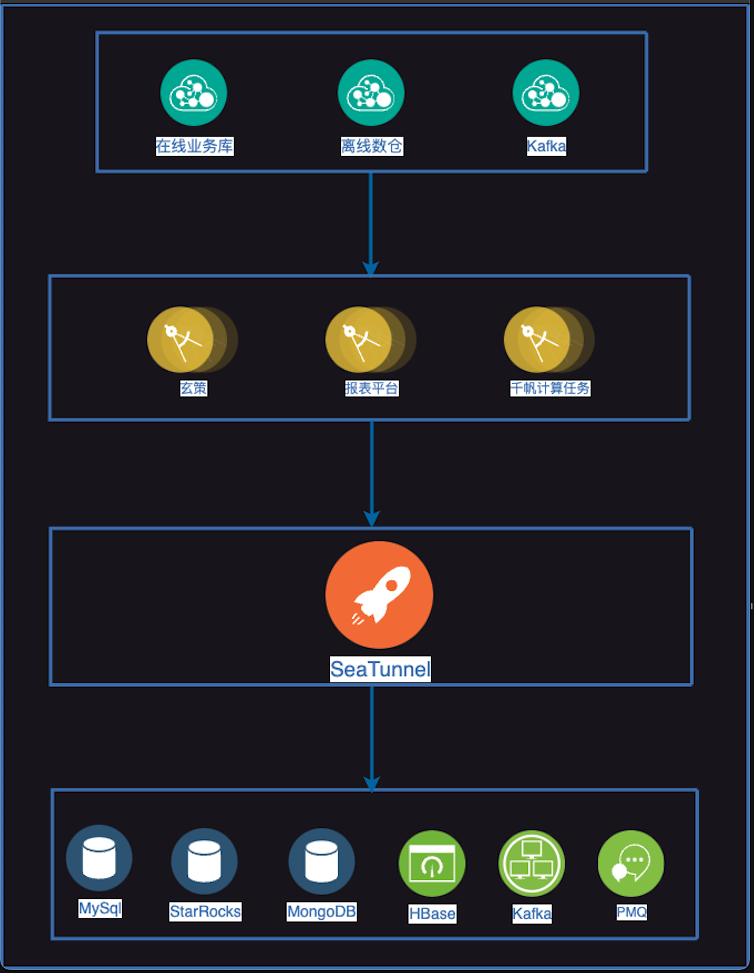
经过一段时间的迭代,Apache SeaTunnel作为新千帆平台的数据集成底座已经在生产环境上线,现在已有部门用户将一些试点任务迁移到千帆平台推送任务当中。
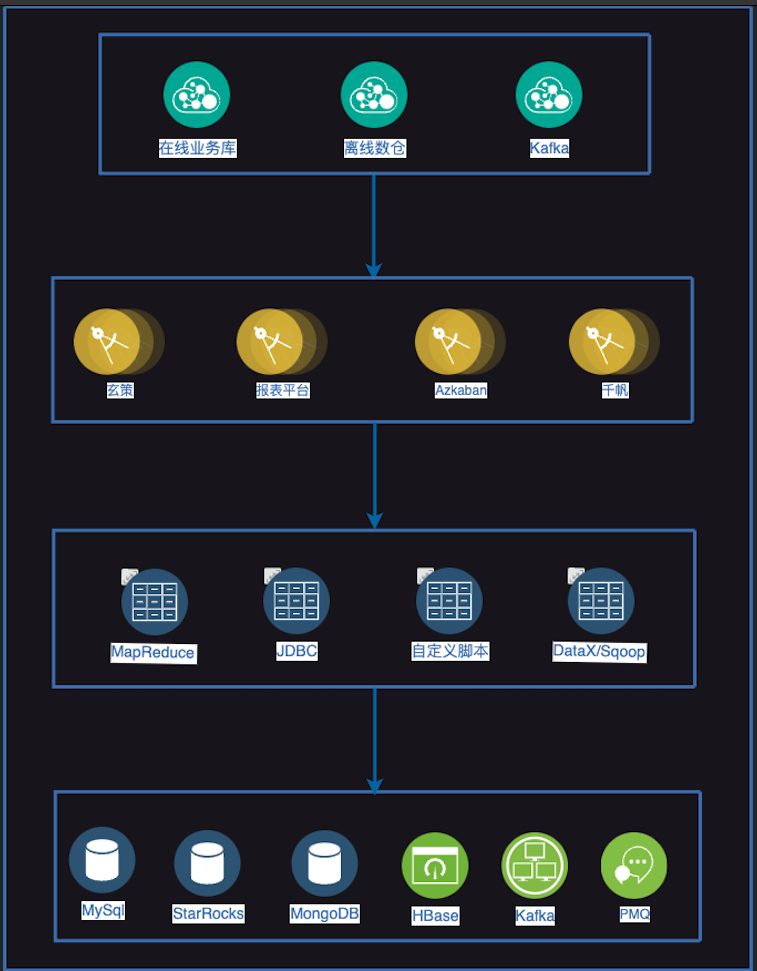
以下是我们重构之后的架构图
未来规划
接下来,我们渴望围绕Apache SeaTunnel去进一步扩展数据推送与互导的场景,进一步结合我司业务场景落地一些实际使用Case,渴望可以或许扩大业务场景的覆盖范围和提升推送质量和服从。
以下是我们近期渴望实验落地的一些工作方向:
扩大覆盖的下游Sink组件范围,尽大概覆盖到我司常用的存储组件及一些业务个性化使用的存储场景
实验切换推送任务的底层引擎,从Flink切换到Zeta,在推送Metric监控及资源调度上做一些实验
围绕推送数据质量和任务陈诉进行精细化建设与运营,推动汗青任务的迁移
最后,感谢Apache DolphinScheduler社区和Apache SeaTunnel社区在落地实践工作中的资助和指导,也衷心祝愿社区发展越来越好!
本文由 白鲸开源科技 提供发布支持!
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4