位运算(&)效率要比代替取模运算(%)高很多,主要缘故原由是位运算直接对内存数据进行操纵,不需要转成十进制,因此处理速度非常快。而计算hash是通过同时使用hashCode()的高16位异和低16位实现的(h >>> 16):这么做可以在数组比力小的时候,也能保证考虑到高低位都到场到Hash的计算中,可以减少辩论,同时不会有太大的开销。
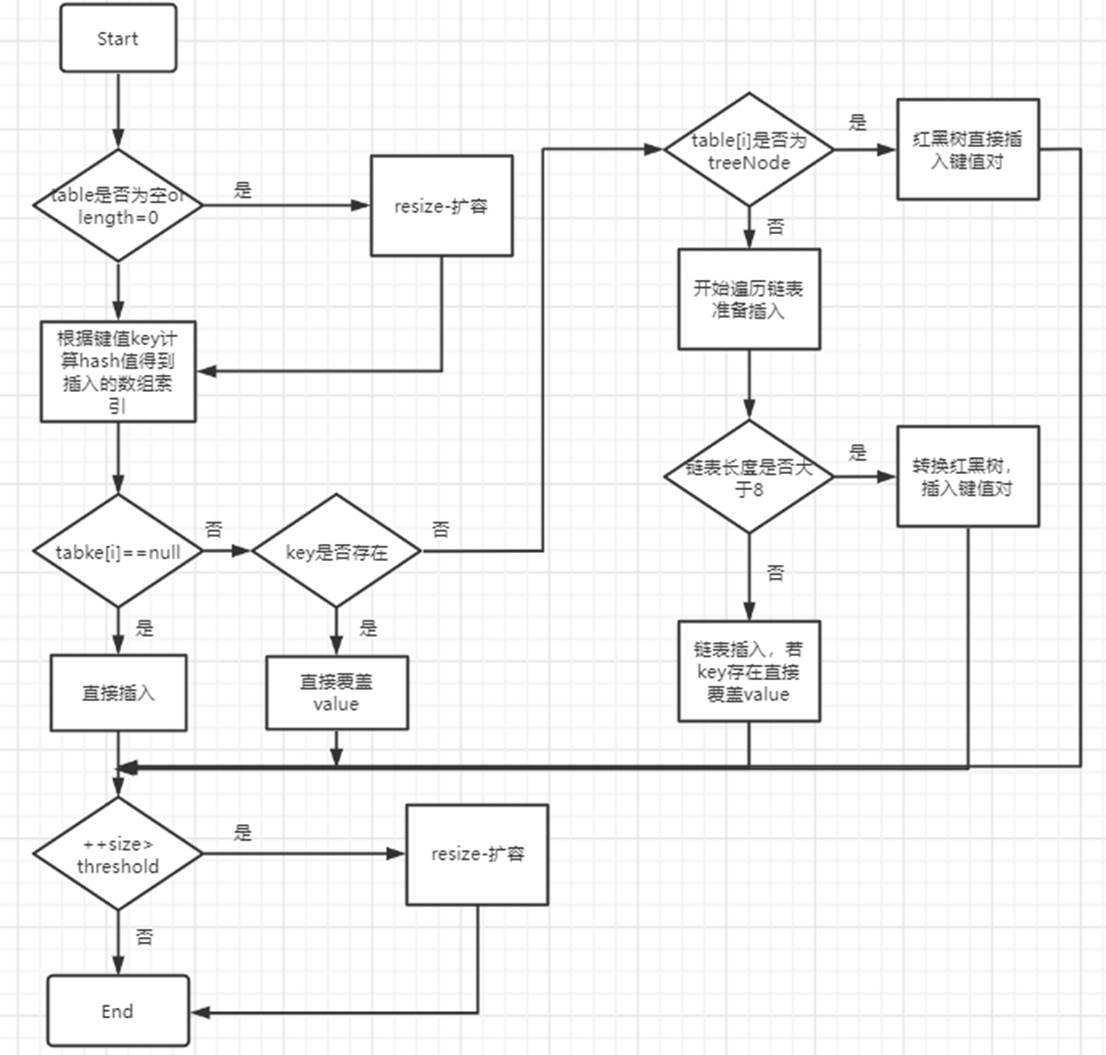
hash值实在是一个int类型,二进制位为32位,而HashMap的table数组初始化size为16,取余操纵为hashCode & 15 ==> hashCode & 1111 。这将会存在一个巨大的问题,1111只会与hashCode的低四位进行与操纵,也就是hashCode的高位实在并没有到场运算,会导很多hash值不同而高位有区别的数,最后算出来的索引都是一样的。 举个例子,假设hashCode为1111110001,那么1111110001 & 1111 = 0001,如果有些key的hash值低位与前者雷同,但高位发生了变化,如1011110001 & 1111 = 0001,1001110001 & 1111 = 0001,显然在高位发生变化后,最后算出来的索引照旧一样,如许就会导致很多数据都被放到一个数组内里了,造成性能退化。 为了制止这种情况,HashMap将高16位与低16位进行异或,如许可以保证高位的数据也到场到与运算中来,以增大索引的散列程度,让数据分布得更为均匀(个人认为是为了分布均匀)put流程如下:
一般来说,initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即 loaderfactor)默认为 0.75,如果暂时无法确定初始值大小,请设置为 16(即默认值)。HashMap 需要放置 1024 个元素,由于没有设置容量初始大小,随着元素增长而被迫不断扩容,resize() 方法统共会调用 8 次,反复重修哈希表和数据迁徙。当放置的集合元素个数达千万级时会影响程序性能。
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |