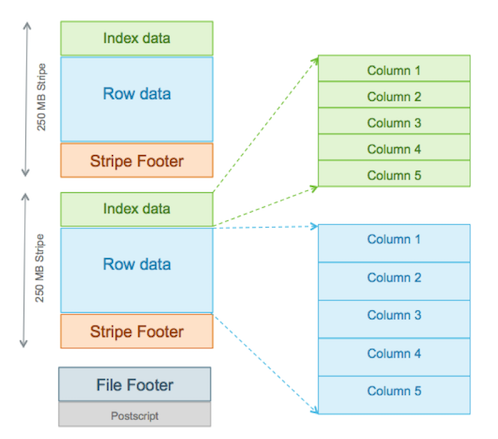
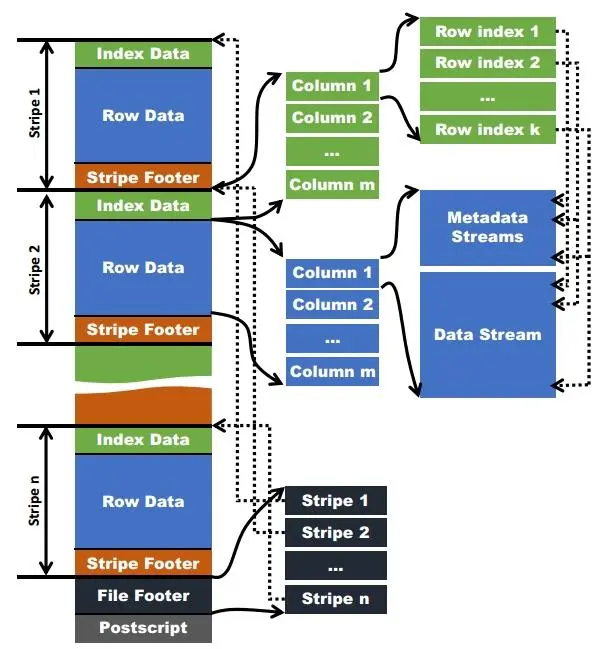
ORC的主体由多个Stripe(也成为条带)组成,类似于RCFile中的行组,但是其远远大于行组的4MB,最大可达到250M大小,更大的Stripe使ORC的数据读取更加高效。
每个Stripe彼此独立,这个很好理解,因为每行数据彼此独立,而每行数据不会在多个Stripe中。
在Hive中每个Stripe通常由不同的任务处理。列存储格式的定义特征是每一列的数据是分开存储的,从文件中读取数据的速度应该与读取的列数成正比。
Stripe又包含三个部分:Index Data、Row Data和Stripe Footer。索引和数据部分都按列划分,因此只需要读取所需列的数据。
Index Data
索引数据部分,存储每列的统计数据。Index Data在Stripe的最前面,因为它们只在使用谓词下推或寻找指定行时加载。(这里主要利用索引功能实现的,具体见下文条带级别索引)
Row Data