ToB企服应用市场:ToB评测及商务社交产业平台
标题:
【redis】数据量巨大时的应对策略
[打印本页]
作者:
干翻全岛蛙蛙
时间:
2024-9-8 10:08
标题:
【redis】数据量巨大时的应对策略
为什么数据量多了主机会崩
一台主机的硬件资源是有上限的,包括但不限于一下几种:
CPU
内存
硬盘
网络
…
服务器每次收到一个请求,都是需要斲丧上述的一些资源的~~
如果同一时刻处置处罚的请求多了,此时就大概会导致某个硬件资源不够用了,无论是谁人方面不够用了,都大概会导致服务器处置处罚请求的时间变长,乃至于处置处罚堕落
如果我们真的碰到了这样的服务器不够用的场景,我们可以:
开源
简朴粗暴,直接增长更多的硬件资源(什么不够补什么)
不过一个主机上面能增长的硬件资源也是有限的,取决于主板的扩展能力
节流(软件上优化)
针对步伐进行优化,优化代码(各凭本事)
通过性能测试,找到是哪个环节出现了瓶颈,再对症下药
操作起来很难!对步伐员的程度要求比较高
分布式系统
当一台主机扩展到极限了,但是还不够,就只能引入多台主机了
但不是说买来的新的机器直接就可以办理问题,也需要软件上做出对应的调解和适配。当引入多台主机了,我们的系统就可以称为“
分布式系统
”了
引入
分布式系统
是
万不得已
的,系统的复杂程度会大大大提高(指数增长),这样出现 bug 的概率就越高、加班的概率就越大、丢失年终奖的概率也随之提高
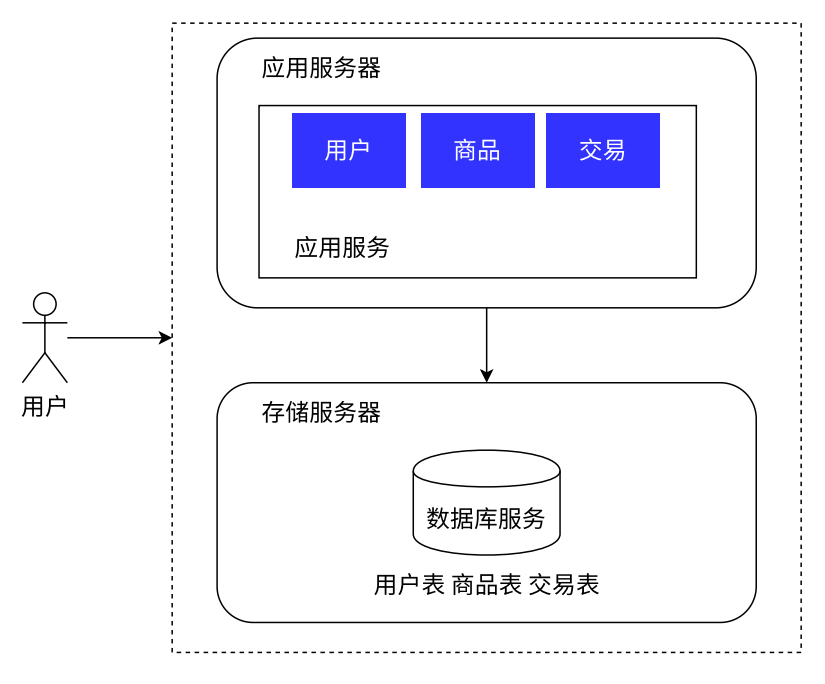
应用数据分离架构
之前应用服务和数据库服务部署在一个服务器上,意味着这一份硬件资源要给两人用
现在各用各的,还可以针对两种服务器的特点,配置不同的主机
应用服务器,里面大概包罗很多的业务逻辑,大概会很吃 CPU 和内存。就给其配置 CPU 配置高、内存大的主机
存储服务器,最主要的就是需要更大的硬盘空间、更快的数据访问速度。就给其配置更大硬盘的服务器,乃至还可以上 SSD 硬盘(固态硬盘)
分离了之后,能一定程度上的办理硬件资源不够用的问题。但是如果随着请求量进一步增长、数据量进一步增长,我们就需要进一步地增长硬件资源、调解服务器的结构
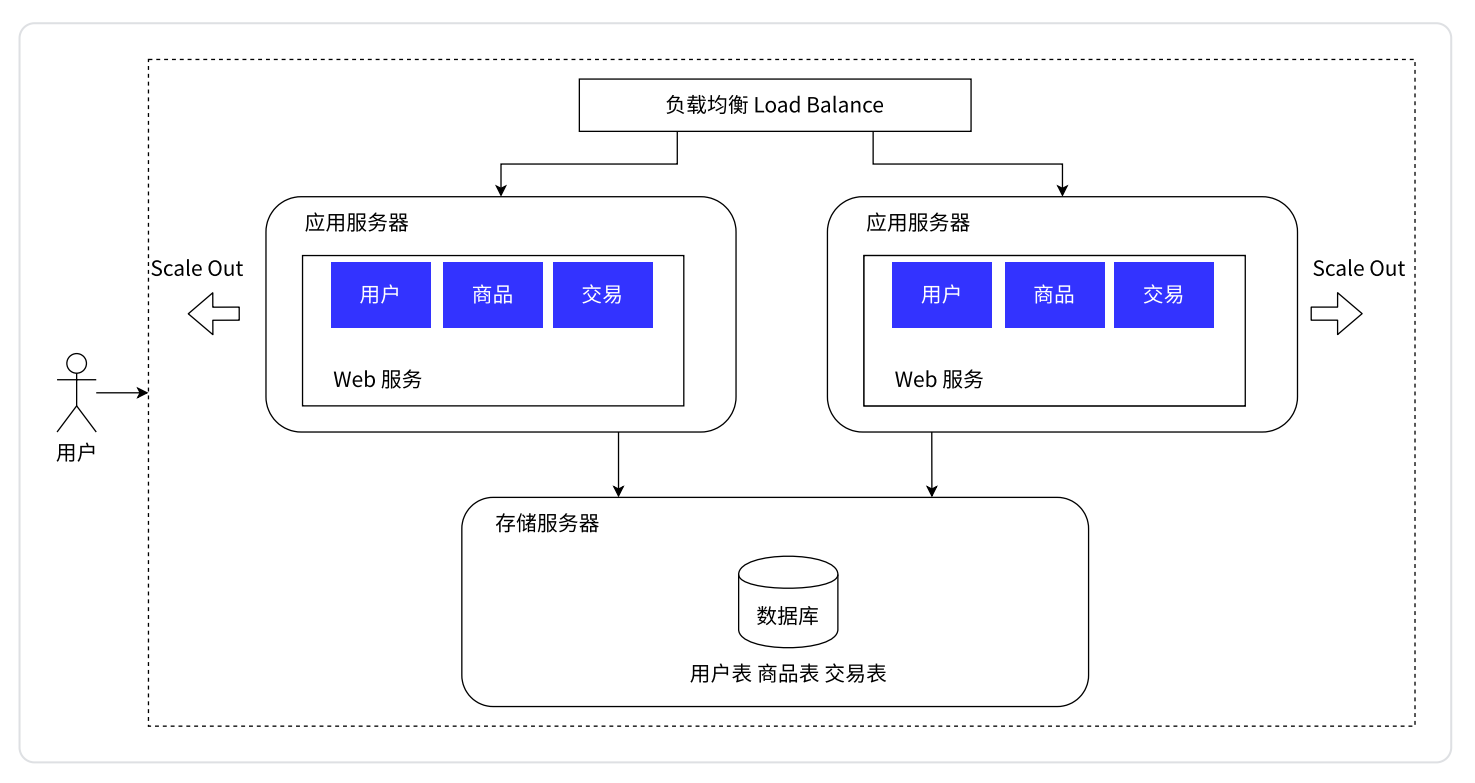
应用服务集群架构
引入更多的应用服务器节点
应用服务器大概会比较迟 CPU 和内存。如果把 CPU 和内存吃没了,此时应用服务器就顶不住了
此时引入更多的应用服务器,就可以有效办理上述问题
相当于是有了更多的 CPU 和硬件资源
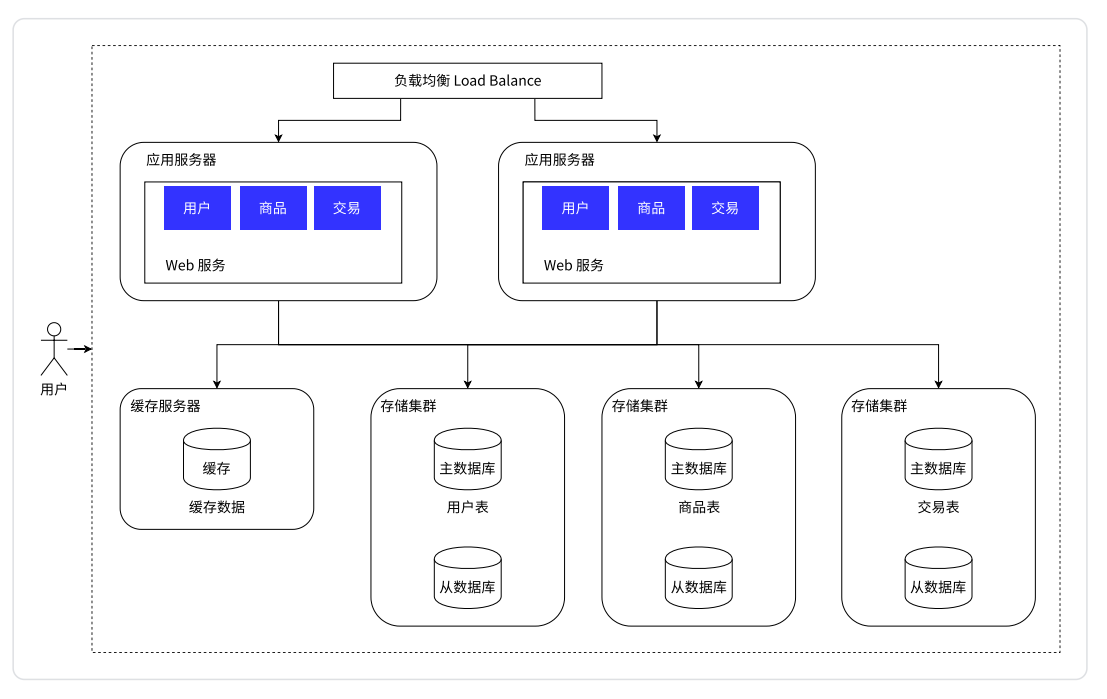
负载均衡器
用户的请求先到“负载均衡器/网关服务器”(单独的服务器)这里,然后由其对这个请求进行分发
现在我们有多个应用服务器了(图中是俩,实际上大概是多个),每个应用服务器都是能单独完成整个业务逻辑的,
此时引入多个应用服务器之后,就可以让每个应用服务器负担整体请求中的一部分
负载均衡器就像公司的一个组的领导一样,要负责管理,负责把任务分配给每个组员
假设有 1w 个用户请求,有 2 个应用服务器,此时按照负载均衡的方式,就可以让每个应用服务器负担 5k 的访问量
[!quote]
负载均衡器
负载均衡器就像公司的一个组的领导一样,要负责管理,负责把任务分配给每个组员
其内部有很多的“负载均衡”详细的算法
此时应用服务器的压力变小了,但“负载均衡器”不是一人负担了所有请求吗?他不会崩吗?
负载均衡器对于请求量的负担能力要远远凌驾应用服务器
负载均衡器是领导,他的职责是分配工作
应用服务器是组员,他的职责是执行任务
执行一个任务所花的时间远远超出分配一个工作所花的时间,所以负载均衡器斲丧的硬件资源是很少的
当请求量大到负载均衡器也扛不住的时间,只需要引入更多的负载均衡器(引入多个机房)就可以了
如上面讨论,增长应用服务器,确实能够处置处罚更高的请求量,但是随之存储服务器要负担的请求量也就更多了,此时仍是两个办法:
开源,引入更多的机器,
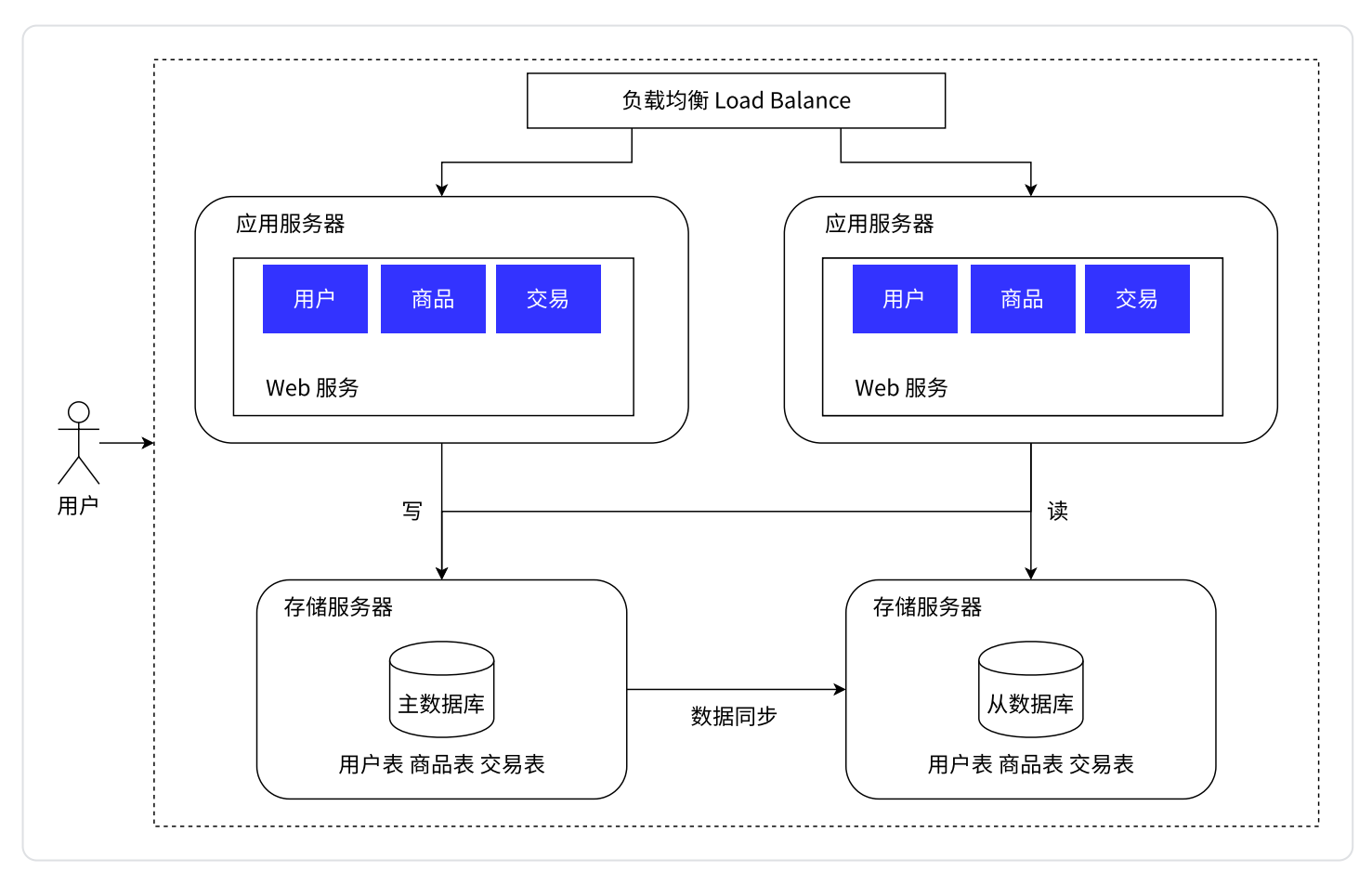
数据库读写分离
节流,门槛高
数据库读写分离
在这个图里可以看到,存储服务器酿成两台了(实际上大概有更多台)
主数据库(master),只负责
写
从数据库(slave),只负责
读
。是主数据库的“跟班”,这个数据库中的数据要从主数据库中进行同步
应用服务器需要
读
,就从“
从数据库
”中去读。需要
写
,就从“
主数据库
”中去写
这样就把每一台机器的压力降低了。在实际的应用场景中,
读的频率是比写要高的
主服务器一般是一个,从服务器可以有多个(
一主多从
),同时从数据库通过
负载均衡
的方式,让应用服务器进行访问
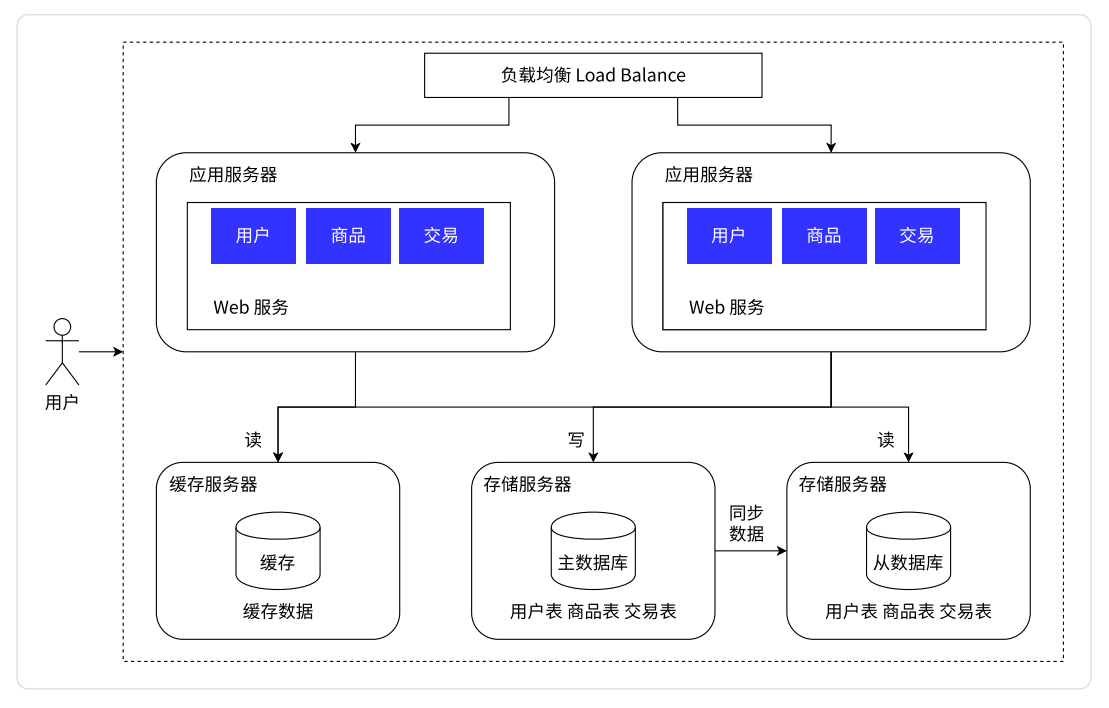
引入缓存
冷热分离架构
数据库天然有个问题——响应速度比较慢。所以将数据区分“冷热”,热点数据放到缓存中,缓存的访问速度往往要比数据库要快很多
缓存中只是放一小部分
热点数据
(会频仍被访问到的数据)
数据库里面存储的仍然是
全量数据
,只是相比之下
热点数据
会被放在
缓存
中
二八原则
,20% 的数据能支持 80% 的访问量,更极度的情况能到一九
后续应用服务器在读取数据的时间,就可以先读缓存,如果这个数据在缓存中存在,就不需要读数据库中的数据了;如果不存在,就再去读数据库。由于二八原则,所以大部分的访问都可以直接在缓存中找到答案
这样数据库的压力又进一步降低了
同时缓存读的又快,又节流了时间
此时就相当与缓存服务器在帮助数据库服务器负重前行
分库
引入分布式系统有两个方面:
应对更高的
请求量
(并发量)
应对更大的
数据量
虽然一个服务器存储的数据量可以到达几十个 TB,但是仍然会存在一台主机存不下数据的情况。当出现这样的情况时,我们就需要
多台主机来存储
针对数据库进行进一步拆分==>
分库分表
,原来一个数据库服务器,这个数据库服务器上有多个数据库(指的是逻辑上的数据集合,create database 创建的谁人东西)
现在就可以引入多个数据库服务器,每个数据库服务器存储一个大概一部分数据库
将不同的表分到不同的机器上
分表
如果某个表非常大,大到一台主机存不下,也可以针对表进行拆分
将一张表拆成五张表,用五个服务器去存储,每个服务器都存储原表中的一部分
这样的话我们引入的存储空间就更多了
详细分库分表如何实践,还是要团结实际的业务场景来开展
微服务
是什么
上面已经演化出了一个比较复杂的分布式系统,可以处置处罚更多的请求,同时可以存储更多的数据。但是这样的演化远远不是终点。在实际工作中还会对应用服务器做进一步的拆分
当应用服务器中要做的功能太多、太复杂,就需要将应用服务器拆成更多的部分
每一部分只负责其中的一小部分功能
之前应用服务器,一个服务器里面做了很多的业务,这就大概会导致这一个服务器的代码变得越来越复杂。为了更方便于代码的维护,就可以把这样的一个复杂的服务器,拆分成更多
单一的,但是更小的服务器
==>
微服务
服务器的种类和数量就增长了
每组服务器都有各自的存储集群和缓存模块
注意:微服务本质上是在办理“人”的问题
当应用服务器复杂了,势必就需要更多的人来维护,当人变多了,就需要配套的管理,把这些人组织好
划分组织结构,分成多个组
每个组分配领导进行管理
分成多个组就需要进分工
代价
引入微服务,办理了人的问题,但是付出的代价:
整个系统的性能会下降
本来用户、商品、交易这些模块都是直接在进程内相互调用的。而现在需要通过网络,进行跨主机通讯
网络通讯比进程内调用慢太多太多了
访问最快的是 CPU、其次内存、才到硬盘,硬盘自己就比内存慢很多了
拆出更多的服务,多个功能之间要更依靠网络通讯,而网络通讯的速度大概比硬盘还要慢,这样系统的性能就会下降很多
想要保证性能不下降太多,只能引入更多的机器,更多的硬件资源(充钱,大厂不差钱)
幸运的是,由于硬件技术的发展,网卡现在有“
万兆网卡
”,读写速度已经能凌驾硬盘读写了,这样才导致微服务的通讯操作不至于“太慢”
不过就一个字——
贵
万兆网卡还需要配上万兆路由器、万兆交换机,乃至是能支持万兆带宽的网线…
所以,这些就不是一些中小公司折腾的起的,还是只有一些大厂能玩得转
系统复杂程度提高,可用性受到影响
服务器更多了,出现问题的概率就更大了,这就需要一系列的手段,来保证系统的可用性
更丰富的监控报警机制
配套的运维人员
上风
办理了人的问题
利用微服务,可以更方便于功能的复用
比如电商系统里面的用户模块,大概在很多模块中多需要用到,那我们就将其单独提取出来,给其他模块来调用
可以给不同的服务进行不同的部署
有的模块对于请求量/数据量处置处罚的不是很多,我们就给它少部署一点机器;有些重点的、负载量大的模块,我们就可以配置更好的机器
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4