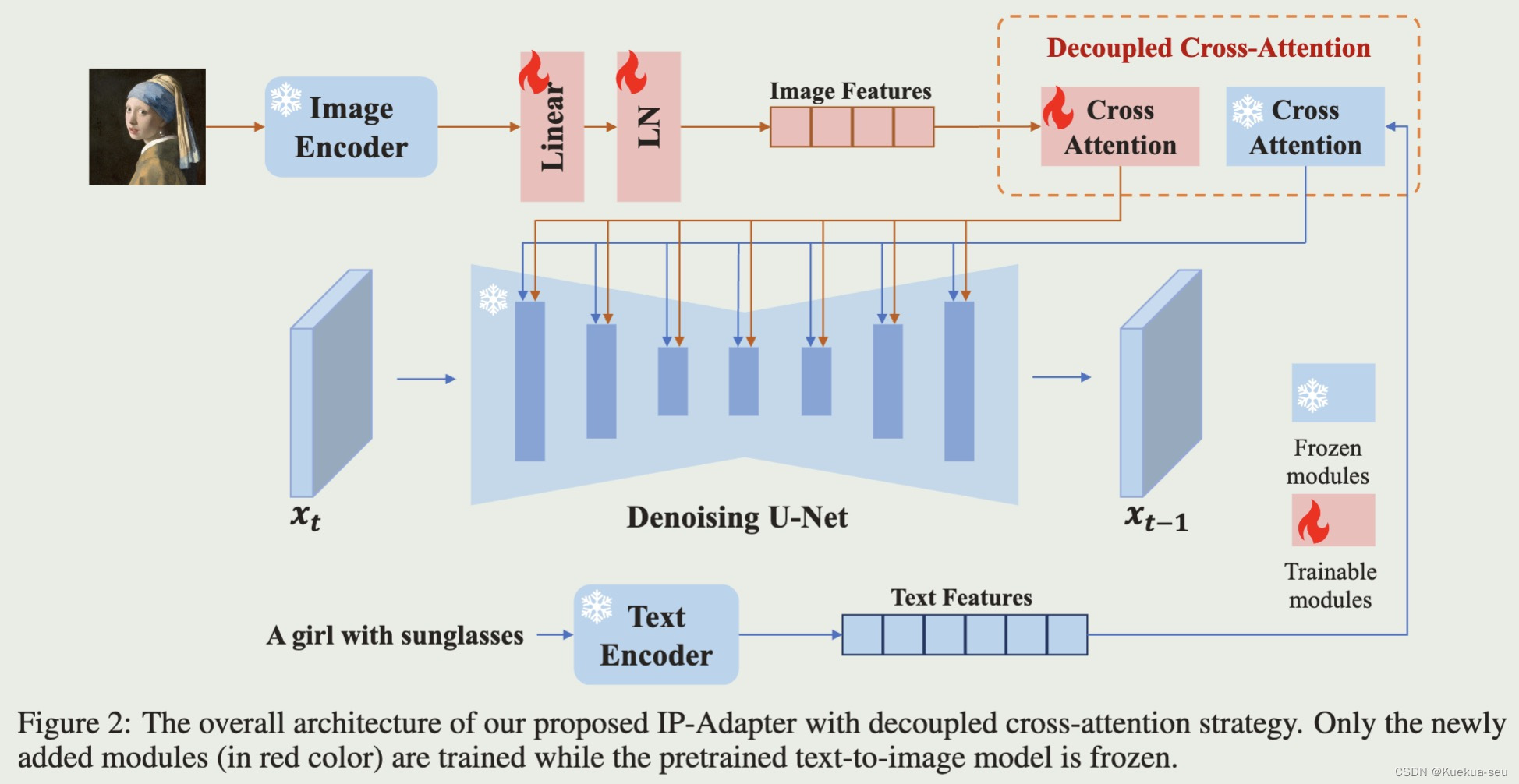
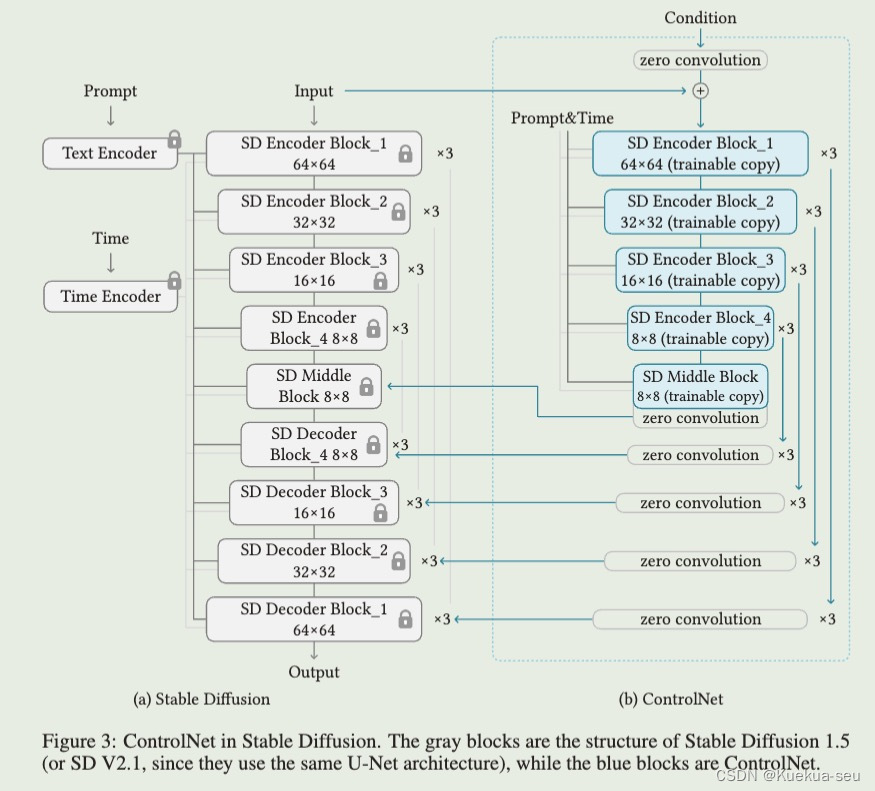
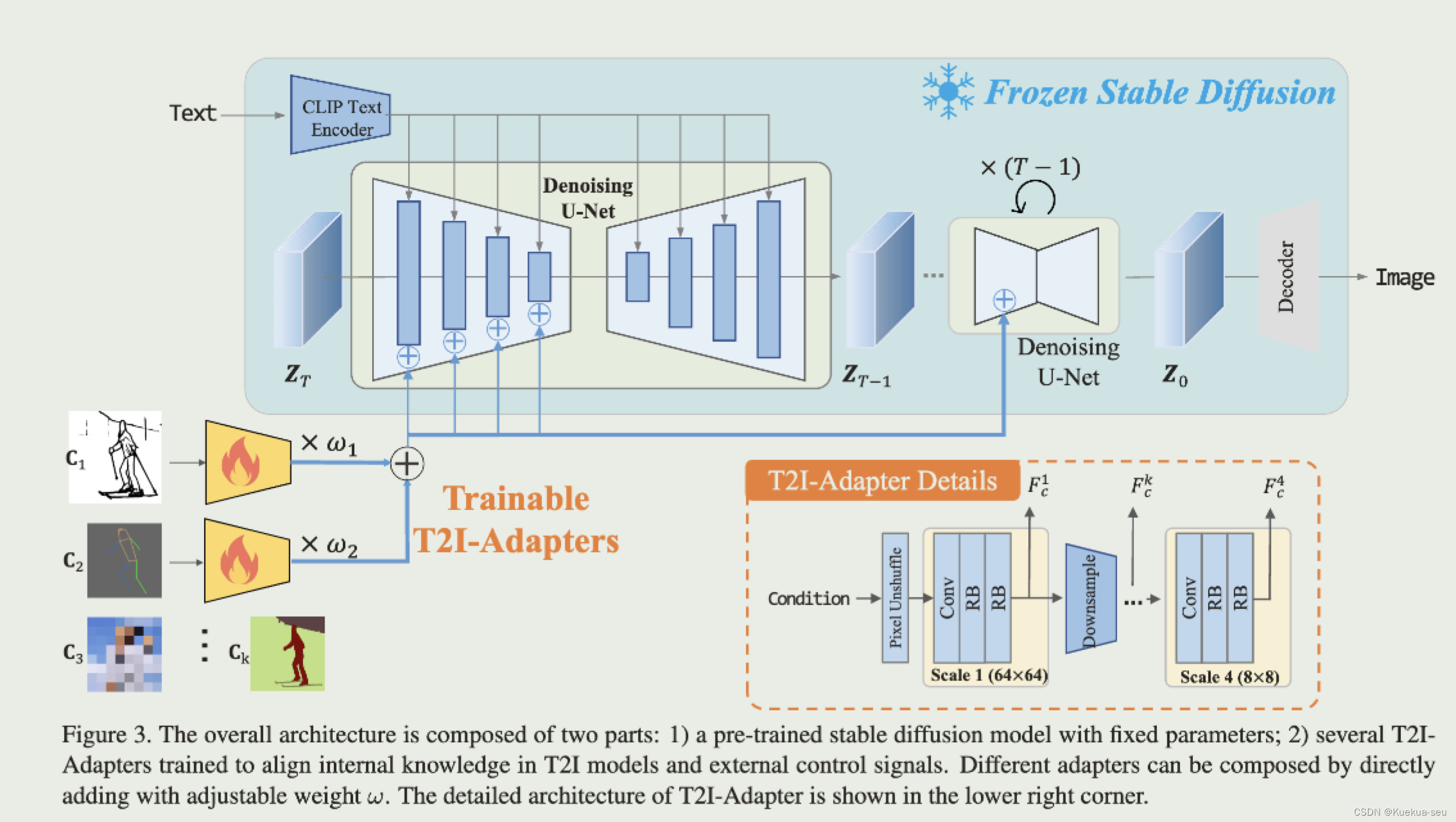
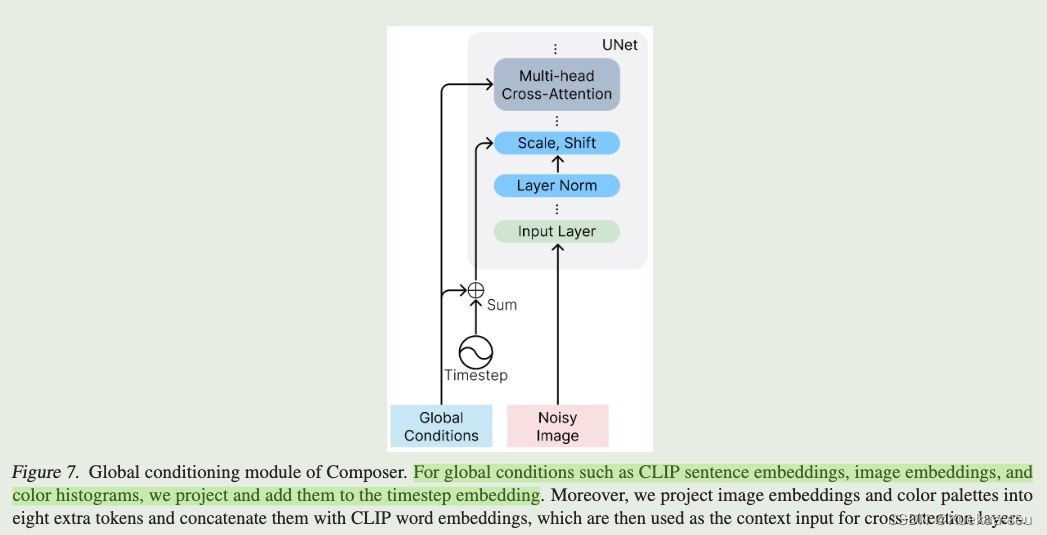
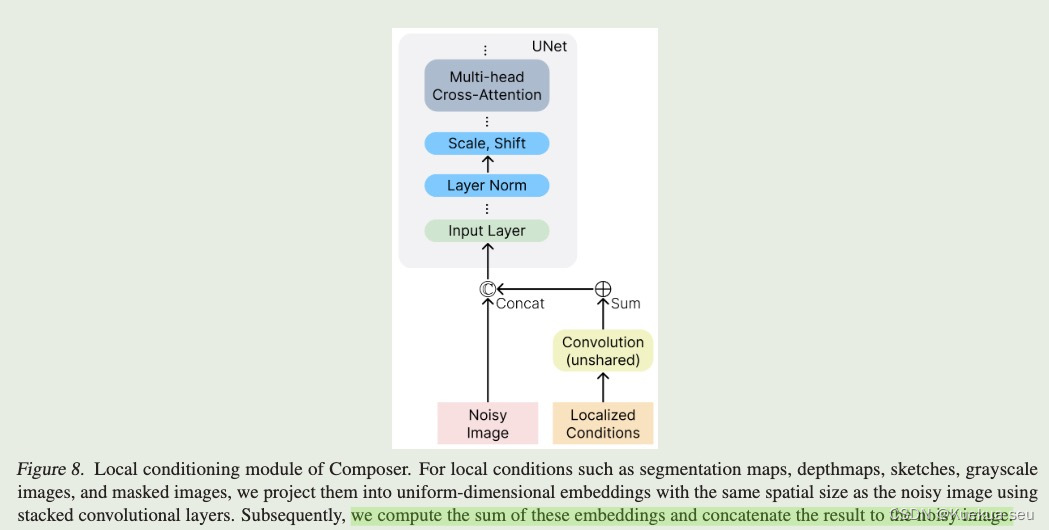
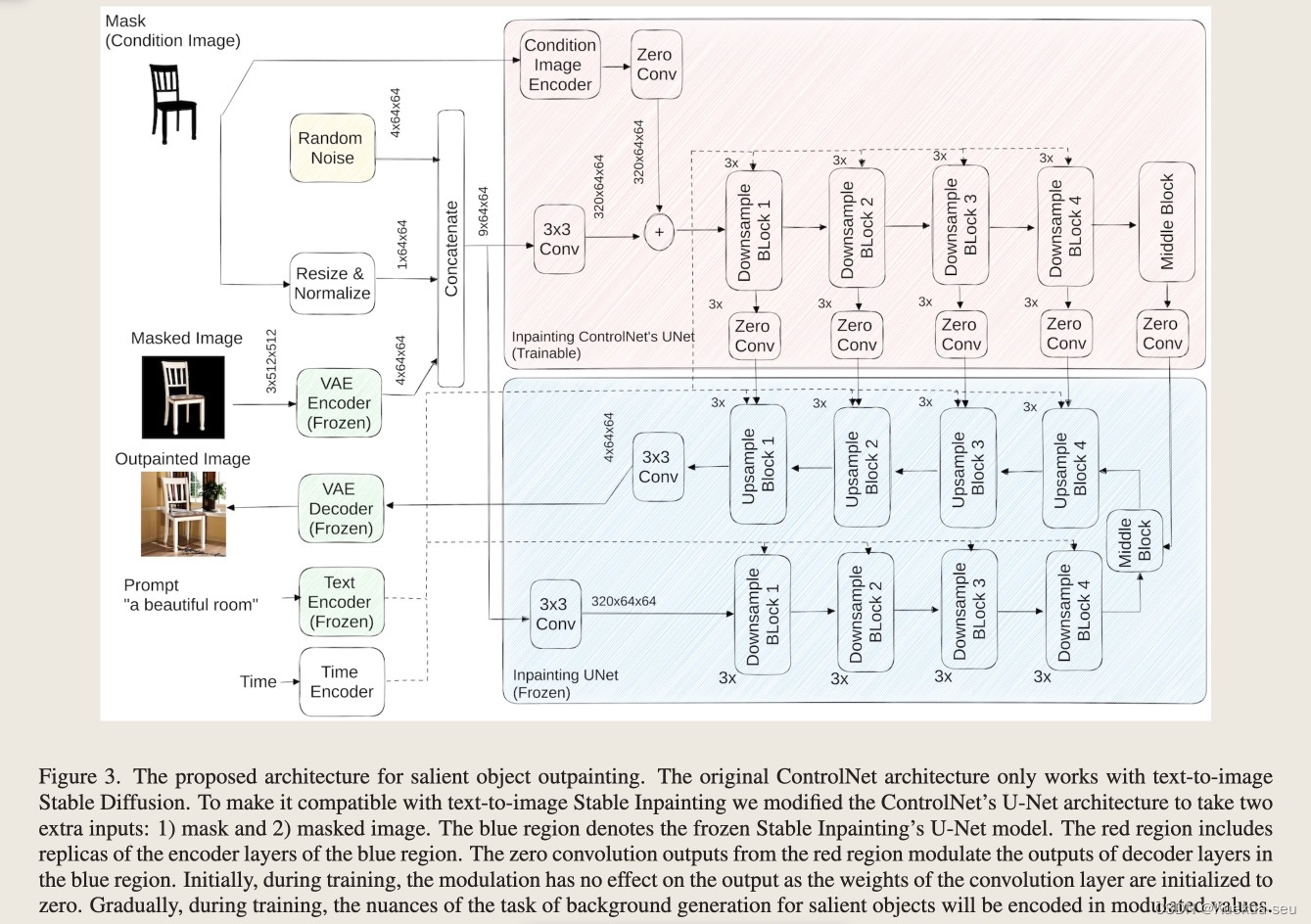
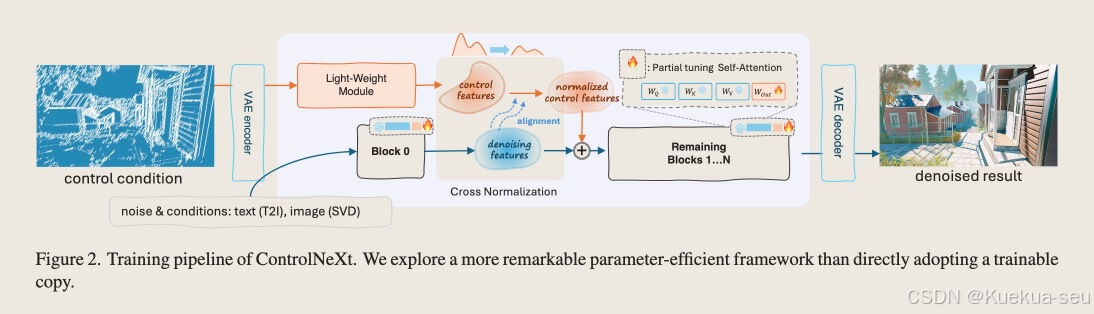
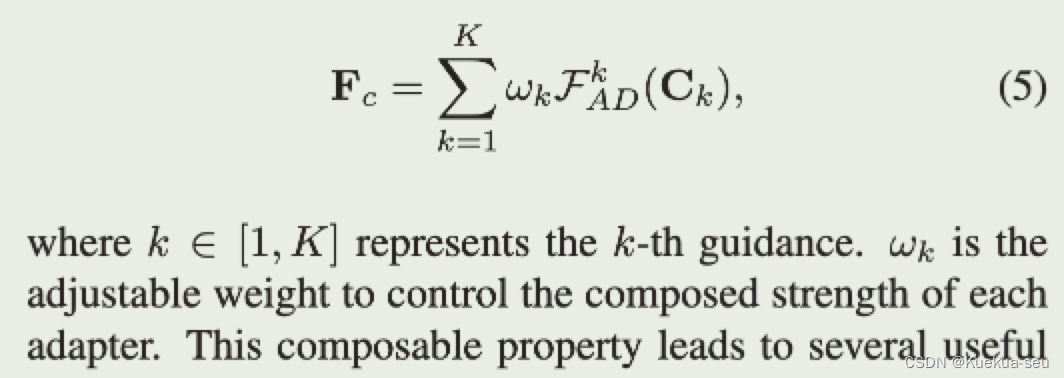论文地址
Enhancing Prompt Following with Visual Control Through Training-Free Mask-Guided Diffusion 办理问题:
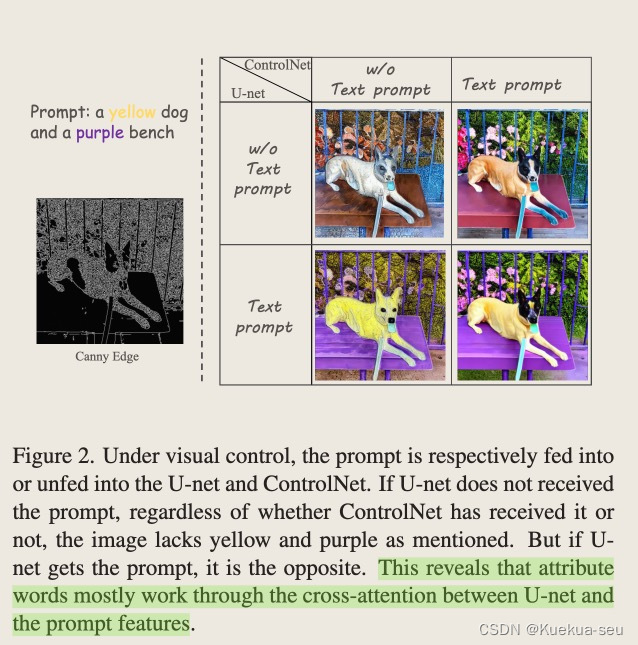
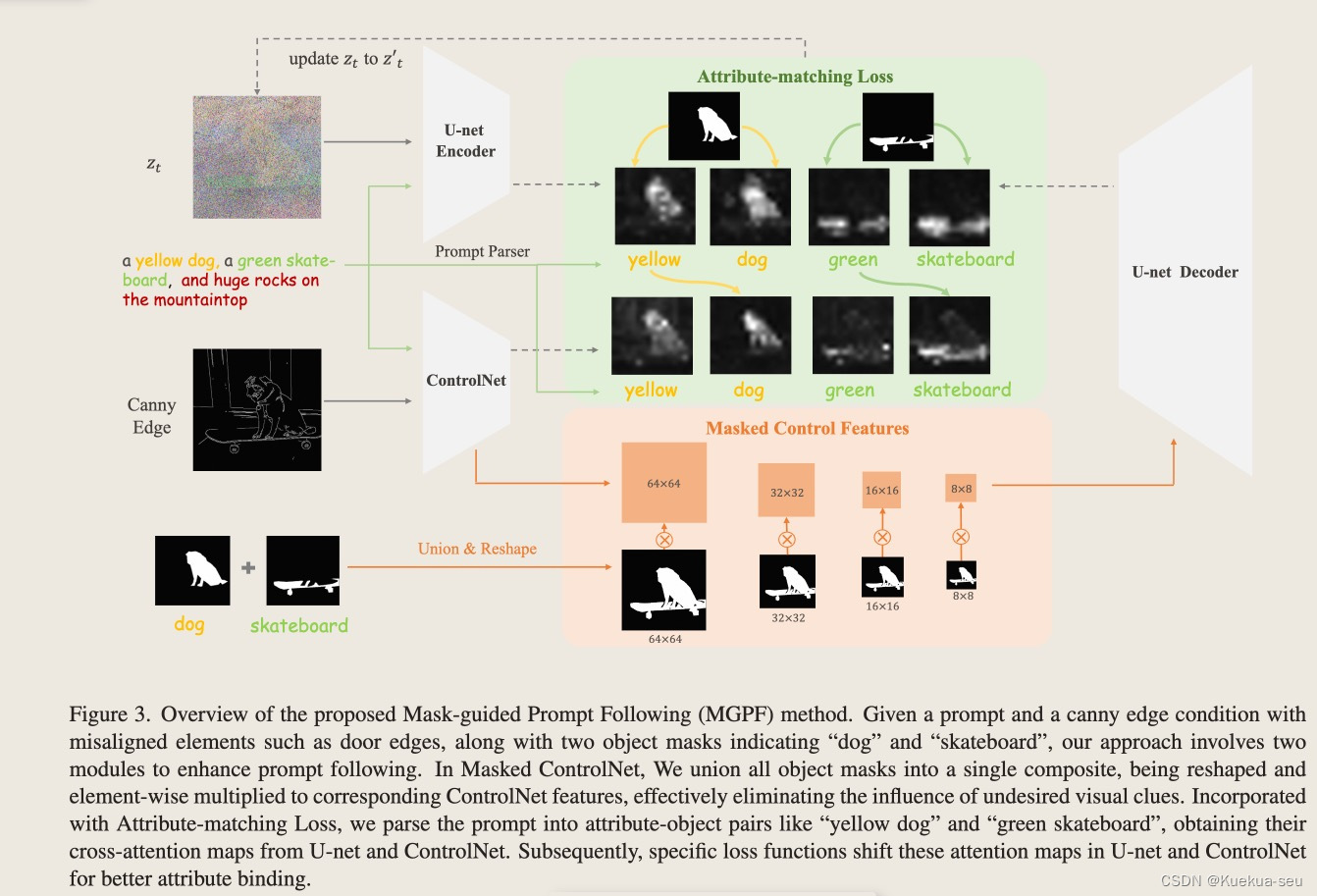
文生图任务中,广泛存在prompt无法准确控制物体属性(比如颜色等)生成的问题,作者思考是否可以通过将prompt拆分成物体-属性对,使用物体mask信息,在controlNet和SD UNet的attention map层创建两者的束缚 办理思绪:
不像controlNet将特性逐层参加unet,controlNeXt只参加到unet中间层,因为作者以为通过Cross normalization特性已经在高层次语义上对齐:the controls typically have a simple form or maintain a high level of consistency with the denoising features, eliminating the need to insert controls at multiple stages.