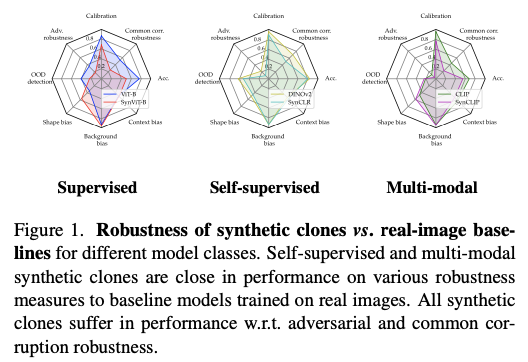
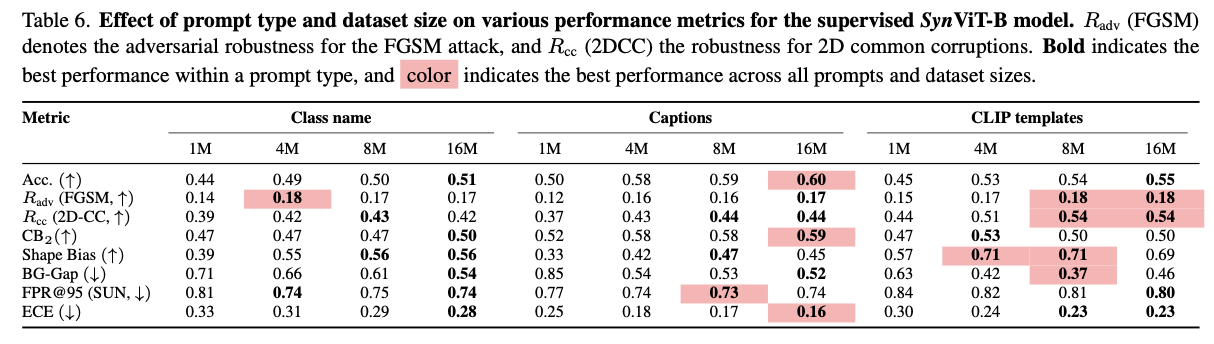
标题: AIGC期间,仅用合成数据训练模型到底行不行?来一探毕竟 | CVPR 2024 [打印本页] 作者: 王柳 时间: 2024-9-9 02:59 标题: AIGC期间,仅用合成数据训练模型到底行不行?来一探毕竟 | CVPR 2024 首个针对利用合成数据训练的模型在不同稳健性指标上进行详细分析的研究,展示了如SynCLIP和SynCLR等合成克隆模型,其性能在可接受的范围内靠近于在真实图像上训练的对应模型。这一结论适用于全部稳健性指标,除了常见的图像破坏和OOD(域外分布)检测。另一方面,监督模型SynViT-B在除形状偏差外的全部指标上均被真实图像对应模型逾越,这清楚地表明确对更好监督合成克隆的需求。通过详细的消融实验,作者发现利用描述或CLIP模板可以产生更稳健的合成克隆。紧张的是,将真实数据与合成数据混淆可以改善大多数指标上的稳健性衡量。
泉源:晓飞的算法工程条记 公众号 论文: Is Synthetic Data all We Need? Benchmarking the Robustness of Models Trained with Synthetic Images
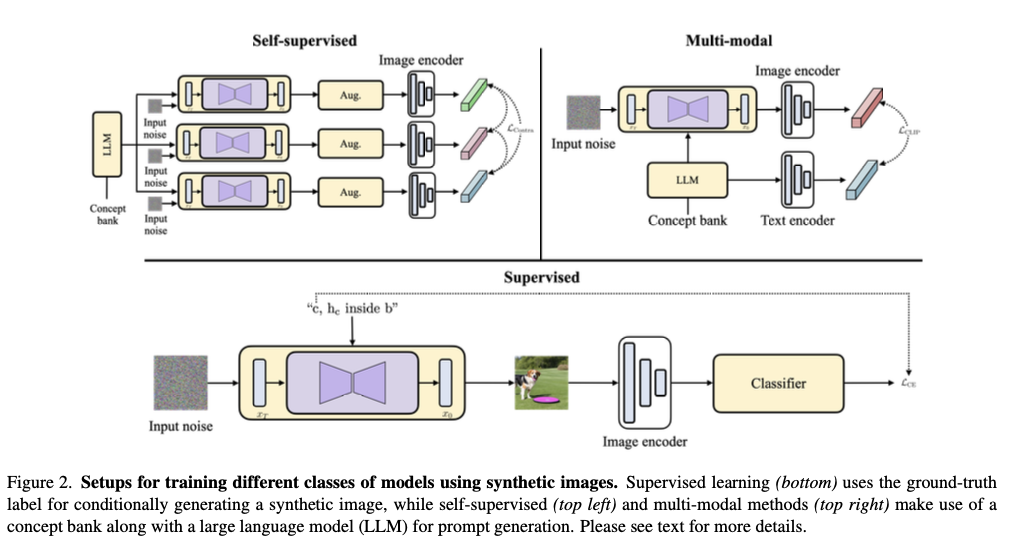
为了训练一个有监督的分类器,首先利用Stable Diffusion天生一幅图像,条件是提示“c, h c \text{h}_\text{c} hc inside b”。这里,c 是从数据集(例如ImageNet-1K)的全部类标签中随机采样得到的真实种别名称, h c \text{h}_\text{c} hc 是与 c 相干联的上义词(hypernym),b 表示Places365数据会合的365个种别之一。在WordNet层次布局中,c 的上义词是 c 在层次布局中的父节点。然后用天生图像的猜测标签和用于天生图像的采样真实种别标签之间交叉熵丧失( L CE \mathcal{L}_\text{CE} LCE )对分类器进行端到端训练,如图1(底部)。有研究创建了120万这样的提示,并天生相应图片来训练一个ResNet50模型。同样地,还有研究只利用类名c来天生1600万张图片,然后用天生图片和真实种别标签来训练ViT-B模型。
Self-supervised models using generated data
合成自监督模型即SynCLR和StableRep,首先从一个概念库中随机抽样一个概念标签。这个概念库通常是利用WordNet提取的同义词集或来自Wikipedia的常见单词、双字词组和标题构建的。然后将这个抽样的概念标签输入到一个大型语言模型(LLM)中,用于天生额外的上下文信息。终极提示由概念标签和上下文信息连接而成。然后利用这个提示来天生 n n n 张图像。之后,还会应用一些在SimCLR模型中也利用的增强(Aug.)。SynCLR模型利用多正对比丧失( L Contra \mathcal{L}_\text{Contra} LContra )进行训练,如图1(左上角)。
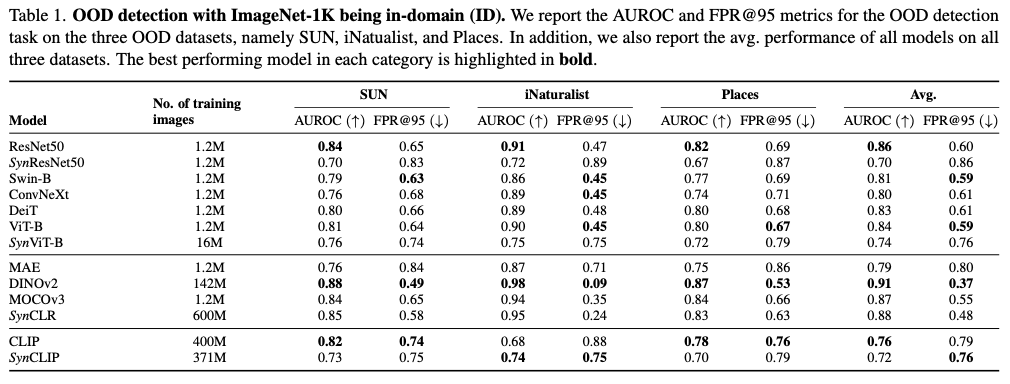
OOD检测对增强终极用户对模型的安全性和可靠性的信托至关紧张,因此需要评估在合成数据上训练对模型OOD检测能力的影响,确定一个模型在多大程度上可以或许区分来自训练数据分布(ID)的样本和来自另一种分布的样本。
OOD检测使命可以被表述为模型猜测概率上的二分类使命。对于权重为 θ \theta θ 的模型 F F F,如果该样本的最大猜测概率高于预界说的阈值 τ \tau τ ,即 max F θ ( x i ) ≥ τ \max F_\theta (x_i) \geq \tau maxFθ(xi)≥τ ,则将输入样本 x i x_i xi 分类为ID;如果 max F θ ( x i ) < τ \max F_\theta (x_i) < \tau maxFθ(xi)<τ ,则分类为OOD。OOD检测可以利用二分类的标准指标进行评估,例如AUROC。另外,作者还报告了在分布内样本的真正例率为95%时OOD样本的假阳性率(FPR@95)。
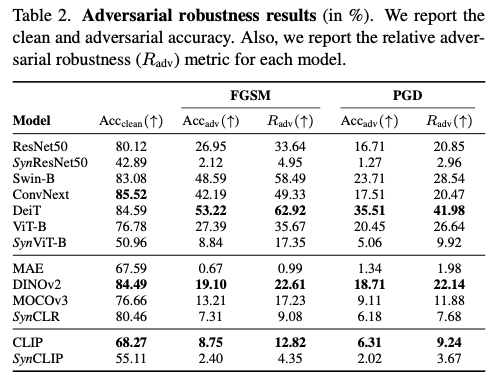
对抗学习旨在相识模型对于由对手操纵的例子的鲁棒性,这些例子在人眼看来好像相似,但会改变模型的猜测。作者想要探究在合成数据上训练的模型是否更容易受到对抗性攻击,利用了两种流行的白盒攻击方法,即快速梯度符号法(FGSM)和投影梯度降落(PGD)攻击。这些白盒攻击需要对手相识模型的梯度。FGSM攻击通过模型的猜测梯度相对于其输入的缩小步长 ϵ \epsilon ϵ 来扰乱输入图像,可以写成 x ^ i = x i + ϵ ∇ x i J ( θ , x i , y i ) \hat{x}_{i} = x_{i} + \epsilon \nabla_{x_{i}} J(\theta, x_{i}, y_{i}) x^i=xi+ϵ∇xiJ(θ,xi,yi) ,此中 x i x_{i} xi 表示输入图像, ∇ x i J \nabla_{x_{i}} J ∇xiJ 表示丧失函数相对于 x i x_{i} xi 的梯度, y i y_{i} yi 表示输入图像 x i x_{i} xi 的标签。PGD攻击是FGSM攻击的迭代版本,随后将对抗性输入的投影限制在围绕输入 x x x 的 ϵ \epsilon ϵ 球内。 ϵ \epsilon ϵ 值表示允许的最大扰动。作者在PGD和FGSM攻击中利用 ϵ \epsilon ϵ 值为1/255,PGD攻击的步数设置为20。
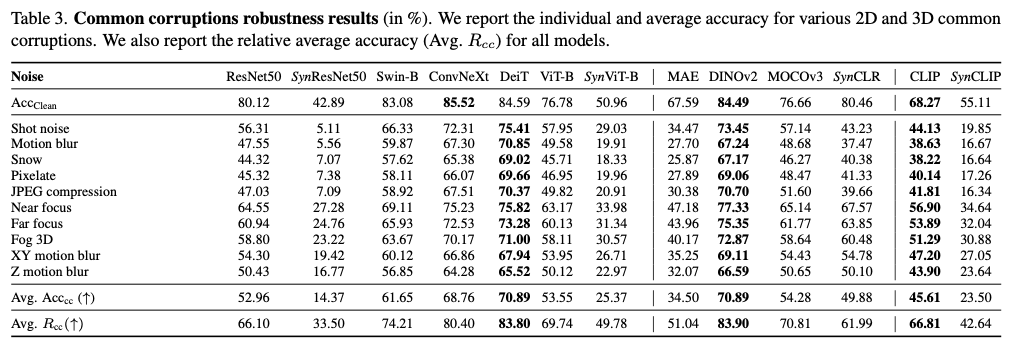
接下来,评估全部模型在现实世界中常见的噪声破坏下的表现,在ImageNet-C和ImageNet-3DCC数据集上进行评估。ImageNet-C包含19种自然发生的图像破坏,如高斯噪声、爆发噪声、运动含糊、弹性变换等。比如ImageNet-3DCC包含12种常见的思量了深度因素的破坏,例如 z z z 轴含糊、远近聚焦偏差等。
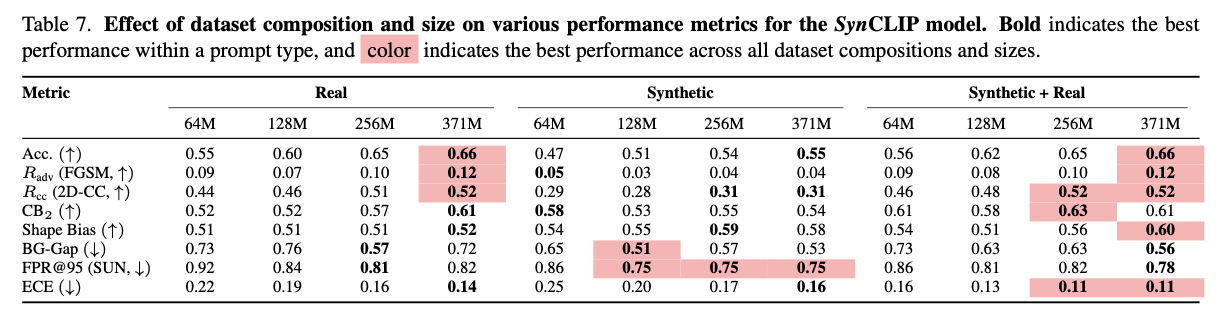
由于时间和资源的限制,作者仅报告十个常见破坏使命的结果(每个数据集各五个),分别清楚样本和破坏样本的准确率以及全部破坏的均匀准确率。作者还报告均匀 R cc R_\text{cc} Rcc 指标,该指标界说为清楚样本与全部破坏均匀准确率之间的相对准确率,即 A V G . R cc = Avg. Acc cc Acc clean AVG. R_\text{cc}=\frac{\text{Avg. Acc}_\text{cc}}{\text{Acc}_{\text{clean}}} AVG.Rcc=AcccleanAvg. Acccc 。结果见表3,可以得出以下结论:
Observation 4:与用真实图像训练的基准模型相比,合成克隆在图像常见破坏方面明显不敷稳健。
全部种别的模型中,合成克隆的均匀 R cc R_\text{cc} Rcc 明显较低。真实数据会合的图像自己就存在这些常见的破坏,因此在真实数据上训练已经可以或许使得结果模型对噪声更加稳健。现在合成图像缺乏这些破坏,使得合成克隆对常见图像破坏非常敏感。
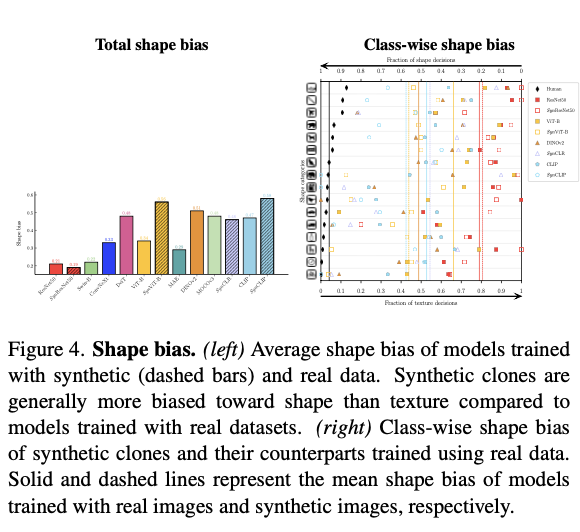
Biases
Context bias
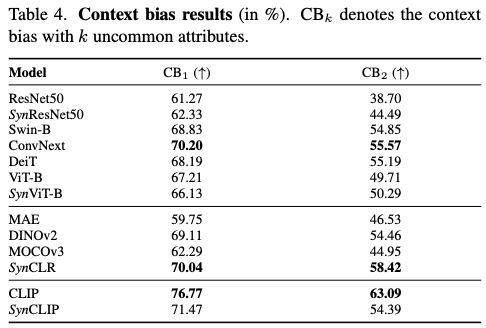
界说上下文偏差为模型倾向于利用上下文线索,例如位置来对物体进行分类,而不是现实利用物体表面。这种上下文偏差存在是由于大多数大规模数据集由从互联网上获取的未加筛选的数据组成。例如,与飞机在跑道上相比,飞机在森林中的图像几乎不可能存在。利用FOCUS(Familiar Objects in Common and Uncommon Settings)数据集来评估上下文偏差,该数据集包含大约21,000张图像。数据会合的每个图像都带有对象种别、时间、位置和睦候标签的注释。
FOCUS将数据集分成常见样本和不常见样本的子集。不常见样本在现实世界中很少见,例如“飞机在森林中”,大概在ImageNet数据会合由于用于构建的标签而罕见(例如,ImageNet中没有海上飞机的标签)。数据集被划分为互斥的分区 P k P_k Pk ,此中 k k k 是不常见属性的数量。总数据集被划分为四个分区,从 P 0 P_0 P0 (仅包含常见对象) 到 P 3 P_3 P3 (包含三个不常见属性)。
作者报告了 CB k \text{CB}_k CBk 指标(具有 k k k 个不常见属性的上下文偏差),它界说为在没有不常见属性的分区 P 0 P_0 P0 上的准确率与具有 k k k 个不常见属性的分区 P k P_k Pk 上的准确率之间的相对准确率,即 CB k = Acc P k Acc P 0 \text{CB}_k = \frac{\text{Acc}_{P_k}}{\text{Acc}_{P_0}} CBk=AccP0AccPk 。例如, CB 2 \text{CB}_2 CB2 衡量了 P 0 P_0 P0 和 P 2 P_2 P2 之间的相对准确率。结果见表4,可以得出以下结论:
Observation 5:与用真实数据训练的基准监督模型和自监督模型相比,自监督合成克隆对上下文厘革具有更强的稳健性。监督合成克隆SynViT-B的性能与在真实数据上训练的ViT-B模型相称。同时,SynCLIP对上下文厘革更为敏感,但其性能仍可与DINOv2和ConvNeXt等模型相媲美。