ToB企服应用市场:ToB评测及商务社交产业平台
标题:
MySQL InnoDB索引原理
[打印本页]
作者:
耶耶耶耶耶
时间:
2022-9-16 17:23
标题:
MySQL InnoDB索引原理
数据库与I/O原理
数据会持久化到磁盘,查询数据是就会有I/O操作,相对于缓存操作,I/O操作的时间成本相当高昂。
I/O操作的基本单位是一个磁盘页面,比如16KB的页面大小。当数据量比较大时,单表数据就会分布在多个磁盘页面。
如果没有索引,就必须按顺序加载磁盘页面到缓存进行查找,判断数据是否存在。随着数据量的增长,磁盘I/O操作的次数也会越来越多。
因此,有必要通过一些辅助的数据结构来提交检索的速度。
从上面可以看出,想要快速读取到数据,可从以下几个方面着手
1. 如何尽量减少磁盘IO操作
2. 如何快速定位到数据所在的磁盘页面
3. 如何快速定位数据在磁盘页面内的位置
数据库索引是什么
索引是存储引擎用于快速查找记录的一种数据结构。
举个类似的例子,当我们要阅读《高性能MySQL》的第五章时,一般会先查找目录,找到第五章对应的页码,然后翻到对应页码即可。
目录一般不会超过10页,整本书有将近700页。
如果没有目录,那么我们只能顺序或者使用二分的方法来查找第五章,需要翻页的次数就会更多。
索引的作用与书籍的目录相似,用于辅助快速查找目标数据。
存储结构
记录(行)格式
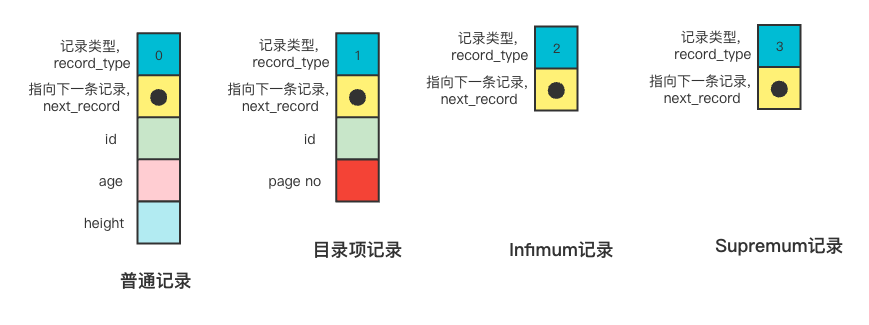
InnoDB支持四种记录格式,分别是REDUNDANT、COMPACT、DYNAMIC和COMPRESSED,MySQL5.7默认是DYNAMIC格式。
下图是DYNAMIC行格式的示意图
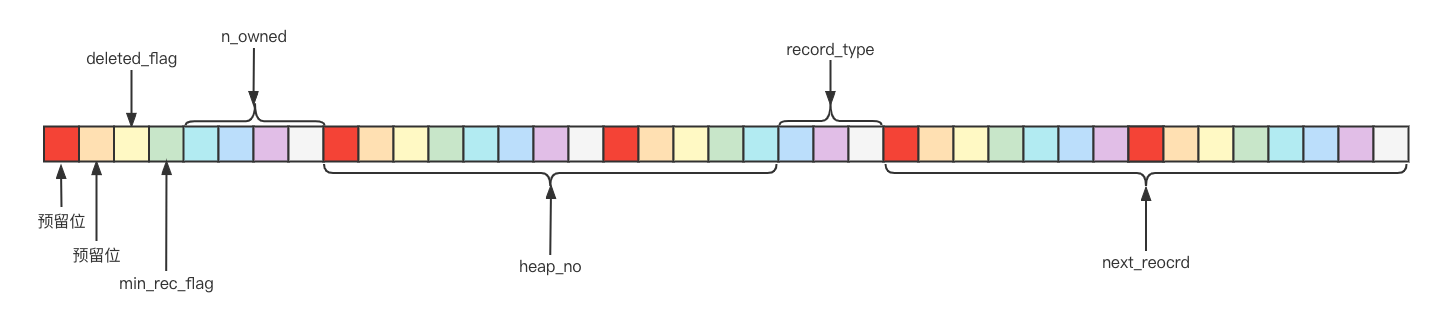
记录头信息的格式示意图如下
部分字段含义
deleted_flag:顾名思义,该记录是否被删除的标志
min_rec_flag:B+树每层非叶子结点中最小的记录项的标志
n_owned: 页面中分组的
heap_on: 表示当前记录在页面堆中的相对记录
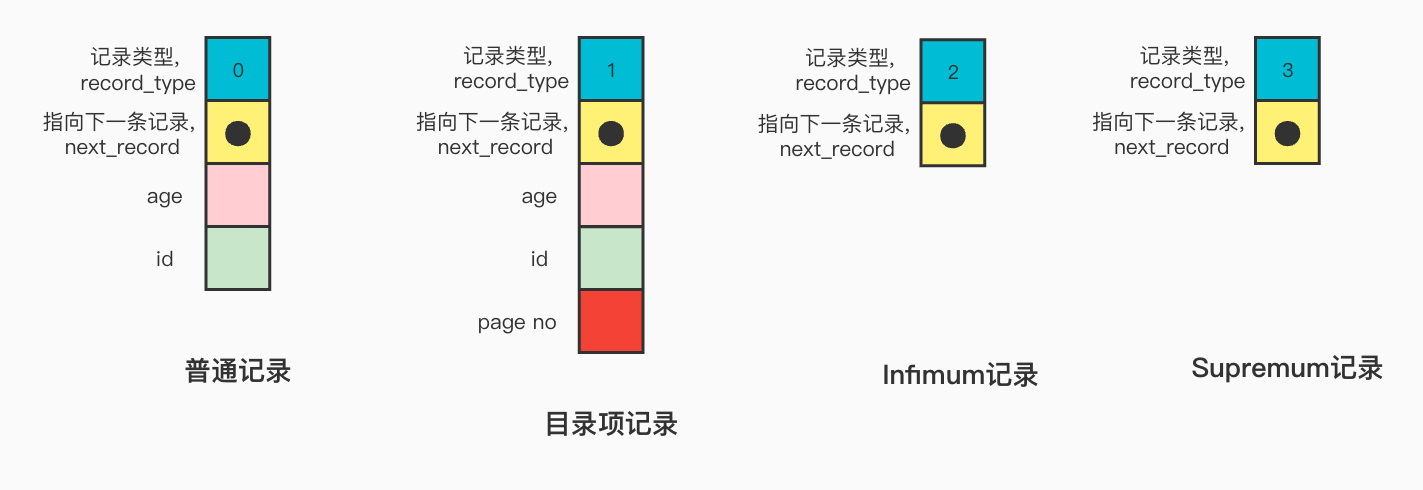
record_type: 表示当前记录的类型,0表示普通记录,1表示B+树非叶子结点的目录项记录,2表示Infimum记录,3表示Supremum记录。
next_record: 指向下一条记录,表示下一条记录的相对位置
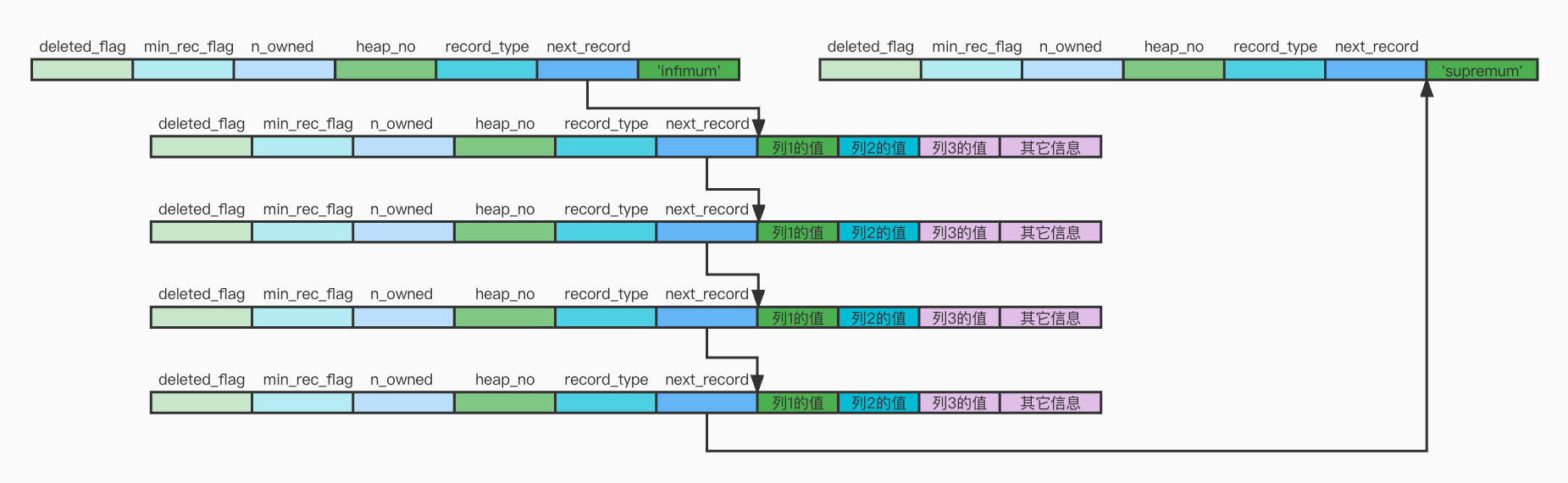
记录示例
所有页面都有两条虚拟记录,即Infimum和Supremum。
Infimum代表页面中的最小的记录,而Supremum则代表页面中最大的记录。
数据排序
页内的记录串联成一个单向链表。
如果表有主键,会根据主键排序;
没主键有唯一非空索引,会根据该索引排序;
两者都没有,InnoDB会自动生成一个row_id列并根据该列进行排序。
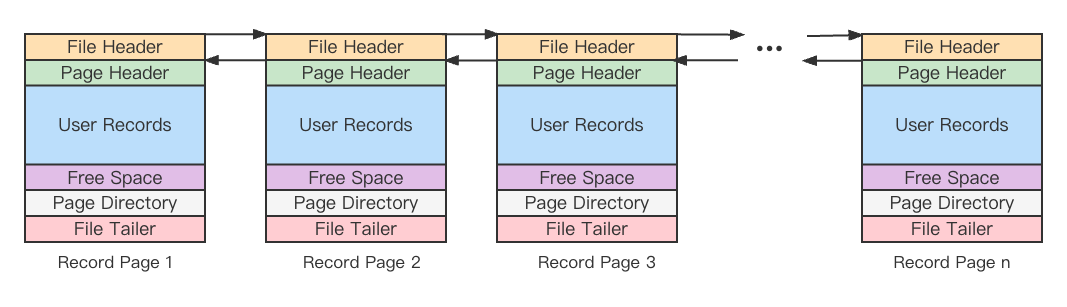
页面格式
页是InnoDB管理存储空间的基本单位,一个页的大小一般是16K。
数据页面的结构如下图
File Header:页面通用信息,如当前页号、上一页/下一页页号
Page Header:页面的各种状态信息,如分组数量,记录数
User Records:记录的有序链表
Free Space:页面中尚未使用的空间
Page Directory:对User Records数据进行分组,减少遍历链表的次数,加速查找
File Tailer:校验页面数据是否完整
数据查找
页面内的数据是有序的单向链表。
假设单行数据128B,而单个磁盘页面大小可以是16KB,因此一个磁盘页面最多可以存放128条数据。这样挨个查找太慢。
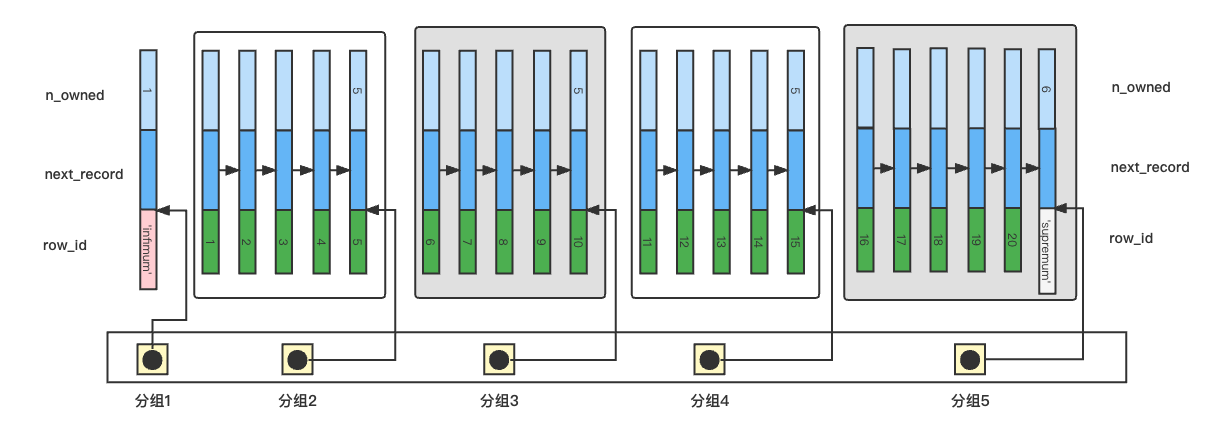
可以利用有序链表的特性,对有序数据进行分组,记录每组的最大值,形成一个有序分组列表。先二分查找有序分组列表,再查找分组内的数据。
这里就会涉及的行记录的n_owned和页面的Page Directory了,InnoDB分组规则如下
1. Infimum记录所在的分组只能有一条记录
2. Supremum记录所在的分组拥有的记录数量为1~8条
3. 其它分组拥有的记录数量为4~8条
4. 分组指向组内ID最大的行。
查找过程
下图是简化的行记录和Page Directory。
在上图中查找ID=17的记录
1. 利用分组进行二分查找,
(1 + 5) / 2 = 3,分组3的最大ID为10,因此继续在右半区间查找
(3 + 5) / 2 = 4,分组最大的ID为15,17位于右半区间,又应为5 - 4 = 1,因此,17位于分组5
2. 组内顺序查找
在分组内遍历单向链表,查找到ID=17的记录
B+树索引
B+树数据结构
在
B树详解
,这边随笔中介绍了B树的查找、插入、删除操作,可以深入理解B数的数据结构
CREATE TABLE `t_student` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`age` int NOT NULL DEFAULT '0' COMMENT '年龄',
`height` int NOT NULL DEFAULT '0' COMMENT '身高'
PRIMARY KEY (`id`)
KEY `age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=COMPACT
复制代码
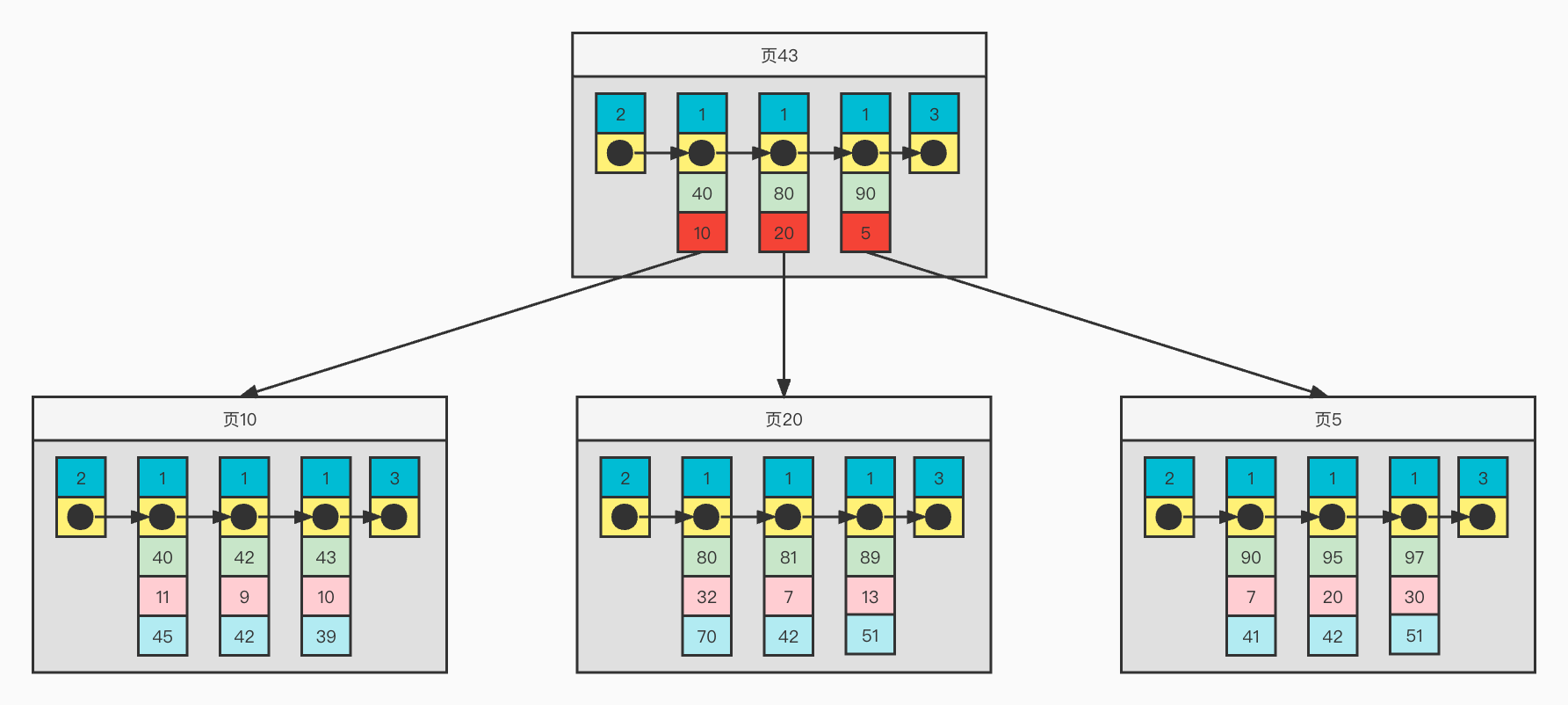
聚簇索引
为了方便画图表示,下面是简化的聚簇索引各种记录格式
聚簇索引结构举例
从上图可以看出,
1)页面内记录按照主键增长的顺序构成一个单项链表
2)对于普通记录,则是一个按照主键有序的双向链表
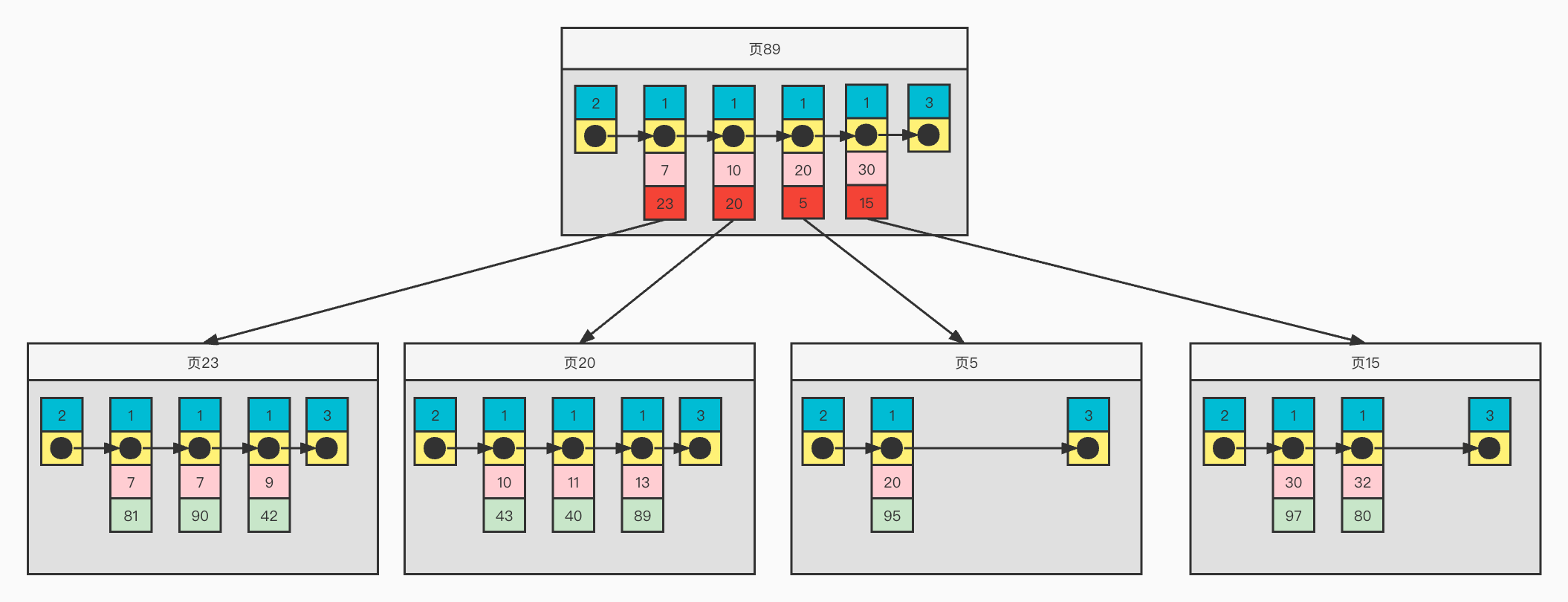
二级索引
为了方便画图表示,下面是简化的二级索引各种记录格式
二级索引结构举例
从上图可以看出,1)页面内记录按照二级索引age增长的顺序构成一个单项链表
2)对于普通记录,则是一个按照age有序的双向链表
3)普通记录并没没有包含完整的信息,而是的组合,需要取其它信息如height还需要进行回表
回表: 数据库根据索引(非主键)找到了指定的记录所在行后,还需要根据索引上保存的主键 ID 再次到数据块里获取数据。
建立索引的原则
1. 尽量使用占用空间少的索引
索引字段占用空间小,意味着单个页面可以存放更多的目录项目记录,使得B+数更加扁平,从而减少IO次数
2. 选择频繁作为查询条件的字段作为索引
频繁作为查询条件的字段作为索引,减少查询的时间,避免全表查询。
3. 选择区分度高的字段作为索引
例如性别只有男1女2两种情况,如果建立索引,目录项只有两条记录,意义不大。还增加了维护索引的成本。
4. 最左匹配原则
多个字段构成联合索引时,这几个字段的顺序十分重要。
假设有联合索引
目录项记录是先按a排序,如果a相等再按b排序,如果a和b都相等,再按c排序。
如果查询条件只有(b,c),则改索引并不会生效。如果只有(a),那索引只是部分生效。
InnoDB Row Formats
《MySQL是怎么运行的》
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4