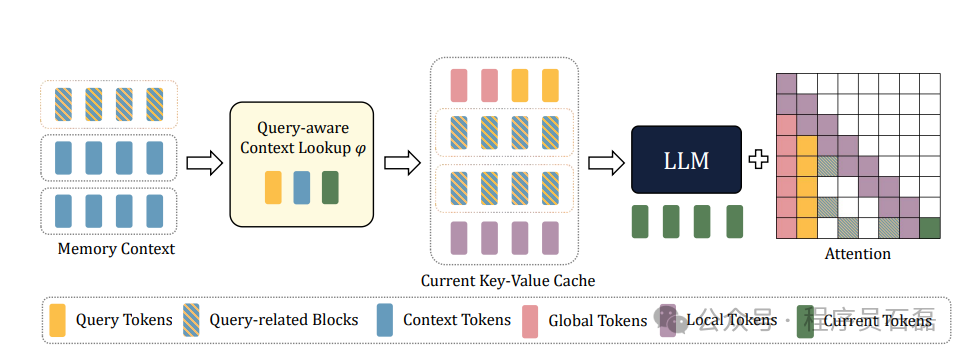
大型语言模型(LLMs)在明白和推理长文本上下文方面的本领是各范畴进步的关键。然而,它们在辨认相干上下文和记忆搜刮方面仍存在困难。为了解决这个问题,我们引入了Query-aware Inference for LLMs(Q-LLM)体系,该体系旨在像人类认知一样处理广泛的序列。通过专注于与给定查询相干的记忆数据,Q-LLM能够在固定窗口巨细内准确捕捉相干信息,并为查询提供精确答案。它不需要额外的训练,可以无缝集成到任何LLMs中。使用LLaMA3(QuickLLaMA),Q-LLM可以在30秒内阅读《哈利·波特》并准确回答相干问题。在公认的基准测试中,Q-LLM在LLaMA3上的性能提高了7.17%,在Mistral上的性能提高了3.26%,在无限基准测试中提高了7.0%,并在LLaMA3上实现了100%的准确率。我们的代码可以在https://github.com/dvlab-research/Q-LLM找到。
重要方法: