| 特性 | 阐明 |
| rust语言实现 | 市面上许多操作系统项目使用的C语言实现,我这里使用的rust实现,可以包管这个项目的代码由我手写实现。也表现了该项目的独特和新颖。 |
| 基于x86 CPU | x86是市面上最常见的CPU,基于这种通用大众化的CPU,也能阐明本项目用到的知识的通用。 |
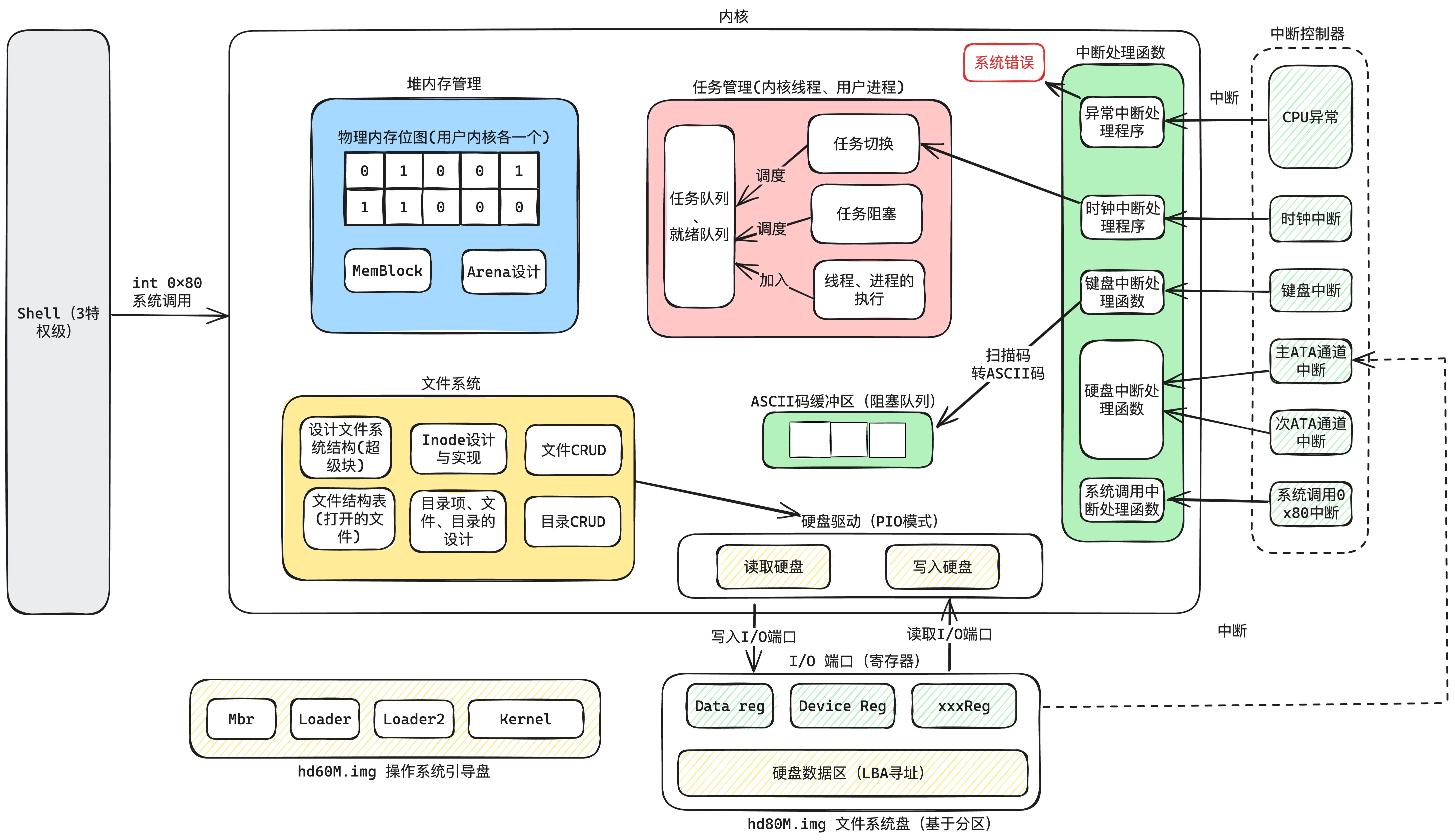
| 拥有OS的基本功能 | 本项目在实现操作系统的功能上,算得上是“麻雀虽小,五脏俱全”。基本操作系统的焦点功能都实现了:
这里只是对系统的基本先容,详细的先容可以看下面更加详细的先容。 |
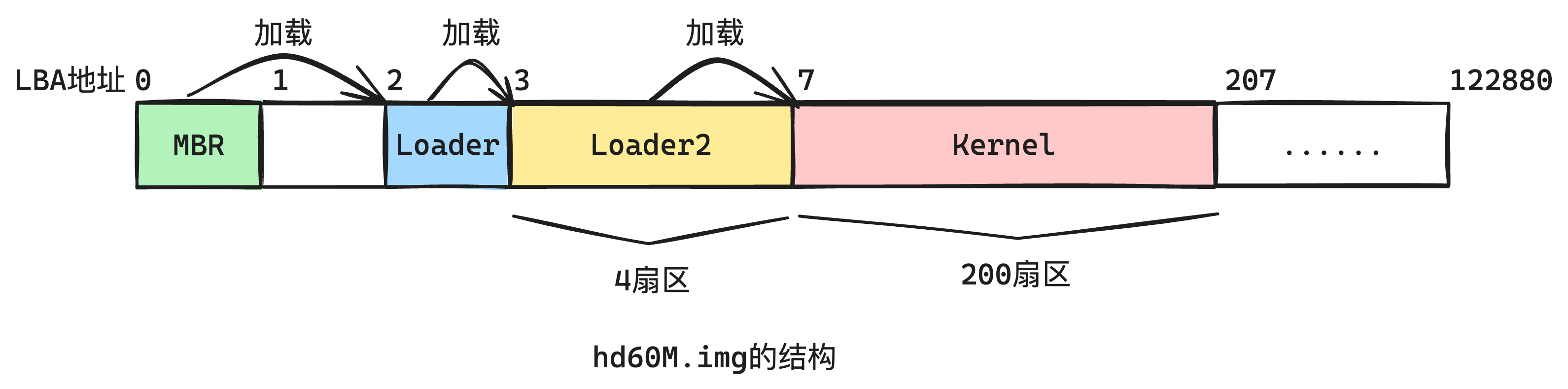
| mbr启动、Loader引导 | 本系统使用比较古老的BIOS启动,手写Mbr启动,并且手动实现Loader对系统进行引导。(mbr和loader均为rust实现) |
| 没使用任何第三方crate | 在市面上许多rust的系统引用了许多第三方的crate,好比blog_os和rCore os。本系统不使用任何第三方crate,全部功能都使用rust的core手动实现。 |
| 模块名称 | 模块范例 | 模块先容 |
| build | makefile生成 | make之后生成的文件 |
| cat | 用户程序(独立进程) (写入到文件系统,然后shell可以加载成为一个进程运行) | 自制的cat程序,把文件系统中的文本文件内容输出到控制台 |
| echo | 自制echo程序,把echo命令跟着的字符串输出到控制台 | |
| grep | 自制grep程序,根据输入内容,进行过滤,然后输出到控制台 | |
| common | 操作系统内核 源码 | common包,loader、loader2、kernel都会用到的常用工具 |
| mbr | mbr启动(16位),该模块就两个功能:
| |
| loader | loader启动(16位):
| |
| loader2 | loader2启动(32位):
| |
| kernel | 进入内核的最终实现,包罗停止、内存管理、线程进程管理、文件系统等等操作系统焦点,都在这个模块 | |
| rrt | Rust RunTime library | 我自制简单的用户程序运行时库,模拟了crt。为用户程序封装了_start入口和exit的调用。 |
| target | cargo生成 | rust使用cargo生成的二进制文件。忽略 |
| tests | 单元测试 | 在这个项目实现中,我写的简单的单元测试 |
| 名称 | 值 | 版本信息 |
| 操作系统 | MacOS | Ventura 13.0.1 |
| CPU | Apple M1 | |
| 编译器 | rustc |
|
| 包管理工具 | cargo |
|
| 自动化工具 | make | GNU Make 3.81 |
| elf文件二进制提取工具 | x86_64-linux-gnu-objcopy | GNU objcopy (GNU Binutils) 2.41 |
| elf文件dump工具 | x86_64-linux-gnu-objdump | GNU objdump (GNU Binutils) 2.41 |
| 名称 | 值 | 情况版本信息 |
| 虚拟机 | qemu-system-x86_64 | QEMU emulator version 8.2.1 |
| 虚拟机2 | bochs | Bochs x86 Emulator 2.8 |
| 命令名称 | 命令用途 | 命令展示 |
| pwd | 展示当前工作目次 | 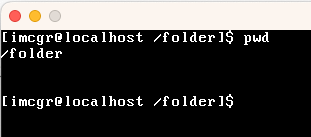 |
| ps | 查询当前的全部使命 | 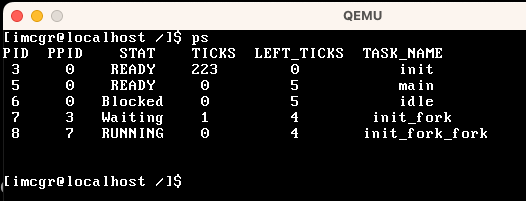 |
| clear | 清屏 | |
| ctrl + l快捷键 | 清屏 | |
| ctrl + u快捷键 | 删除当前行的输入 |
| 命令名称 | 命令用途 | 命令展示 |
| ls | 展示当前目次下的全部文件。 | 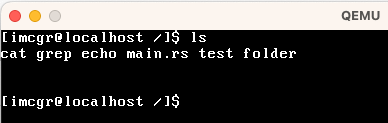 这里的cat、grep是可执行文件 |
| ls -l | 展示当前目次下的文件细节 | 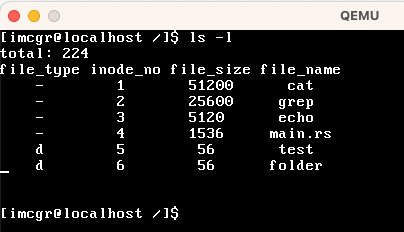 file_type中,"-"表示普通文件,"d"表示文件夹 |
| cd | 切换当前工作目次 | 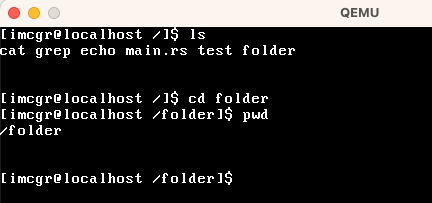 |
| mkdir | 在当前工作目次下,创建一个目次 | 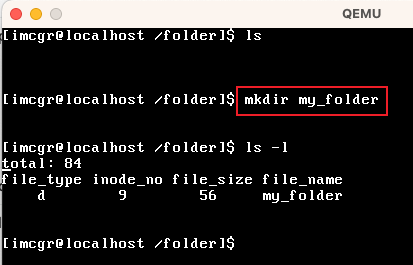 |
| rmdir | 删除某个目次名称 | 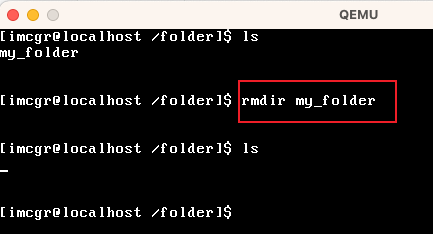 |
| touch | 创建一个普通文件 | 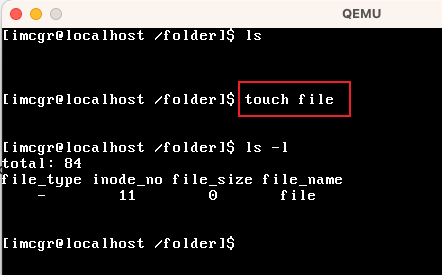 创建了一个名为"file"的普通文件 |
| 命令名称 | 展示效果 |
| echo | 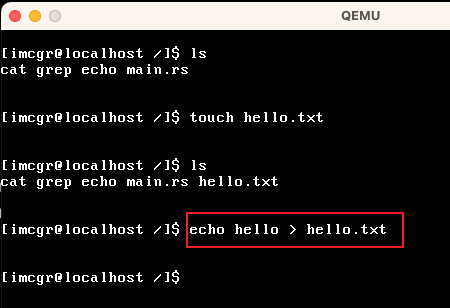 我这里先创建「hello.txt」文件,然后把"hello"字符串写入到 hello.txt文件中 |
| cat | 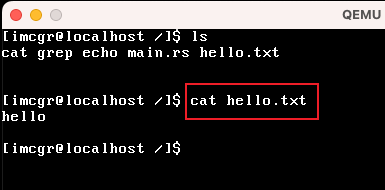 我这里使用cat命令,把hello.txt的文件内容输出 |
| ">"和">>"输出到文件 | 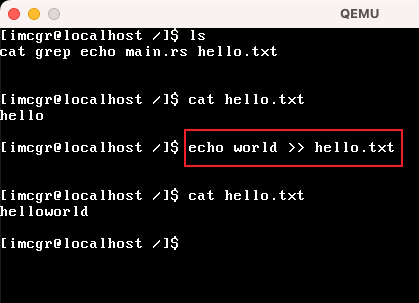 这里使用echo 和 ">>" 追加 数据到 hello.txt文件中 |
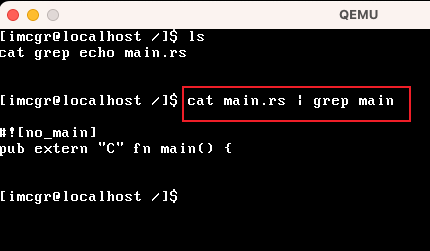
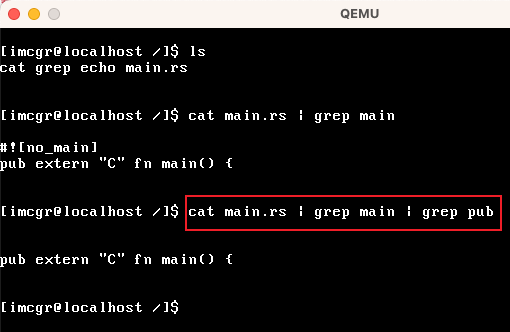
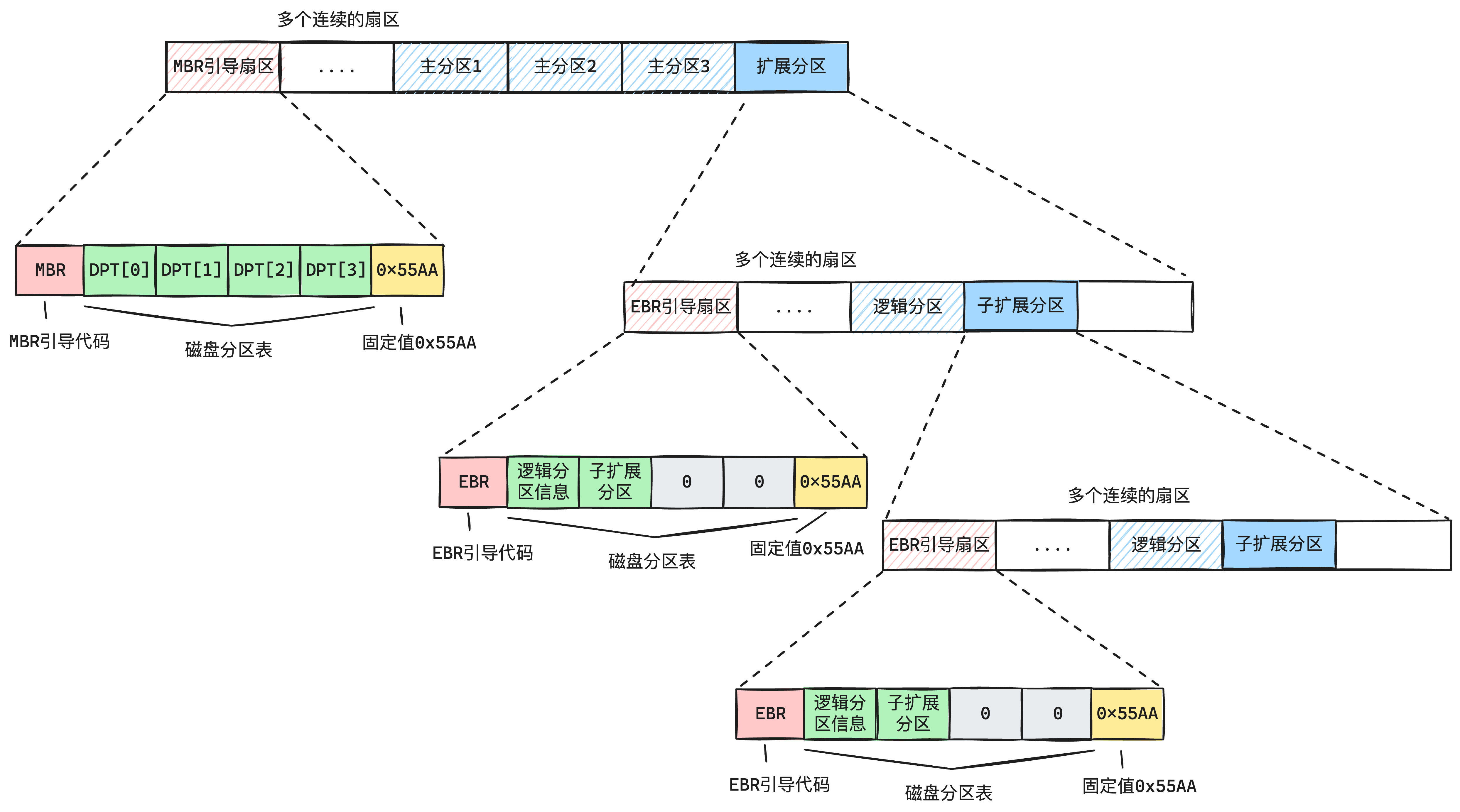
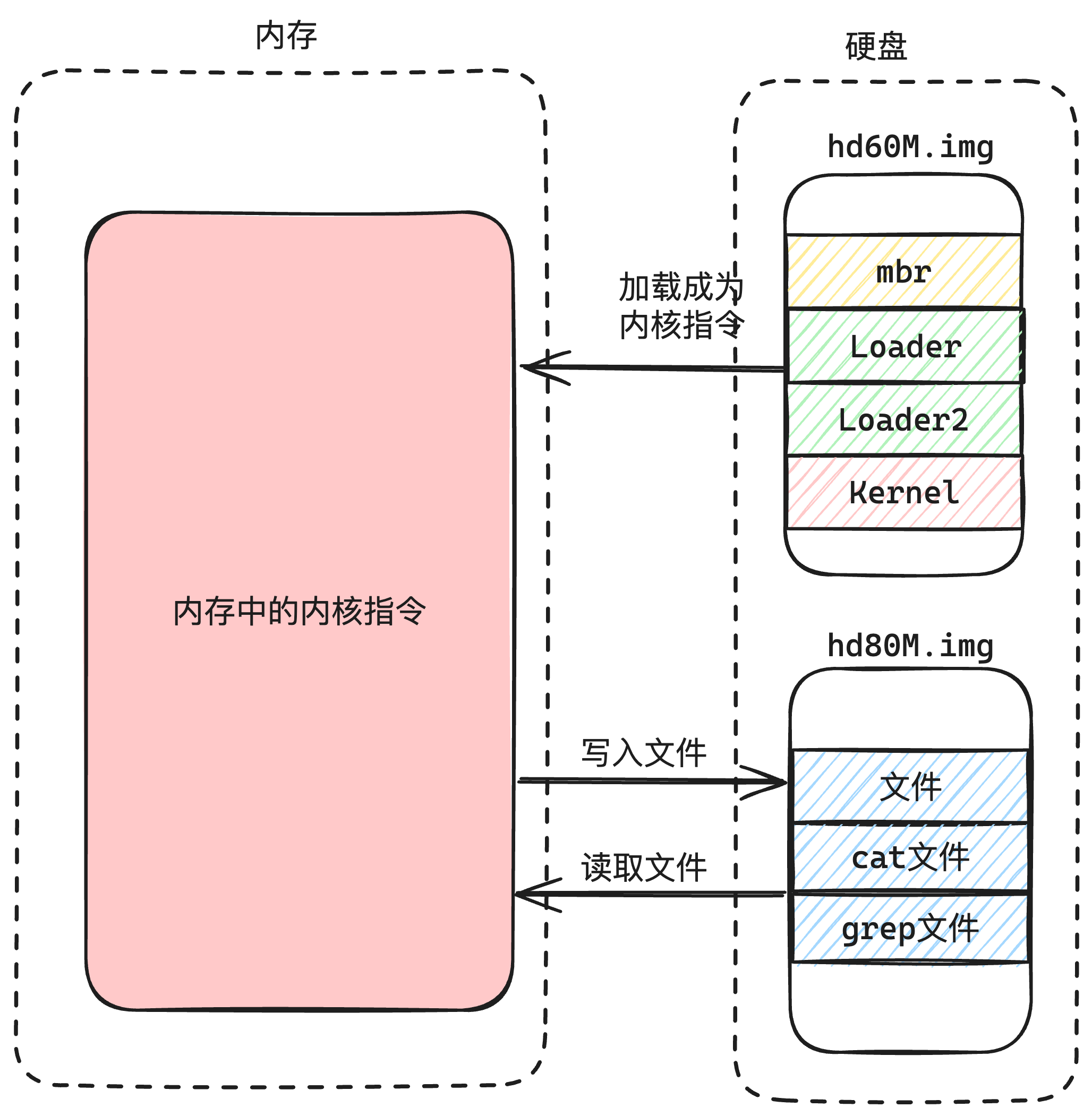
| 模块 | 作用 |
| mbr | 在我看来有两个作用:
|
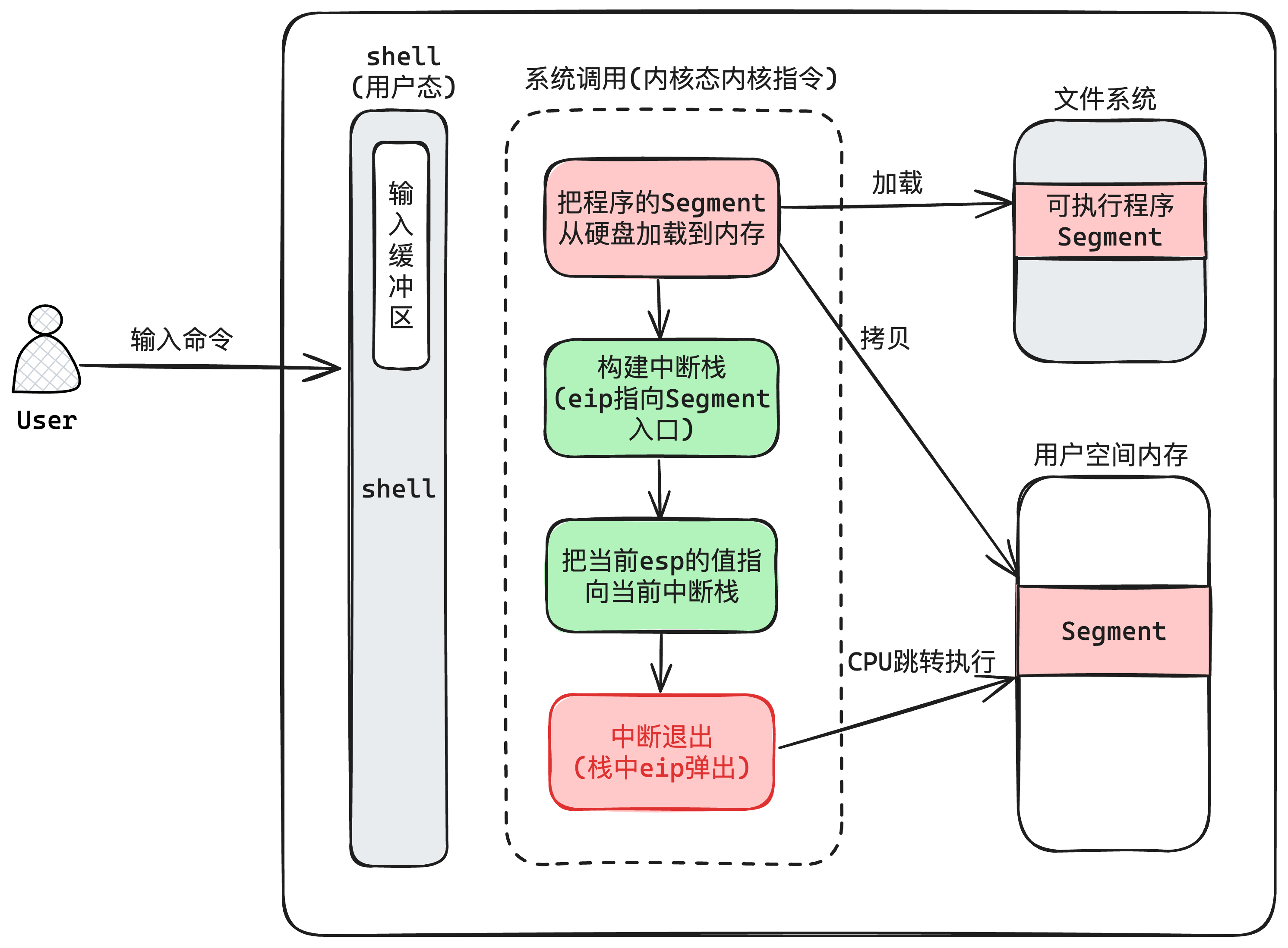
| loader | 在我的系统计划中,有两个作用:
|
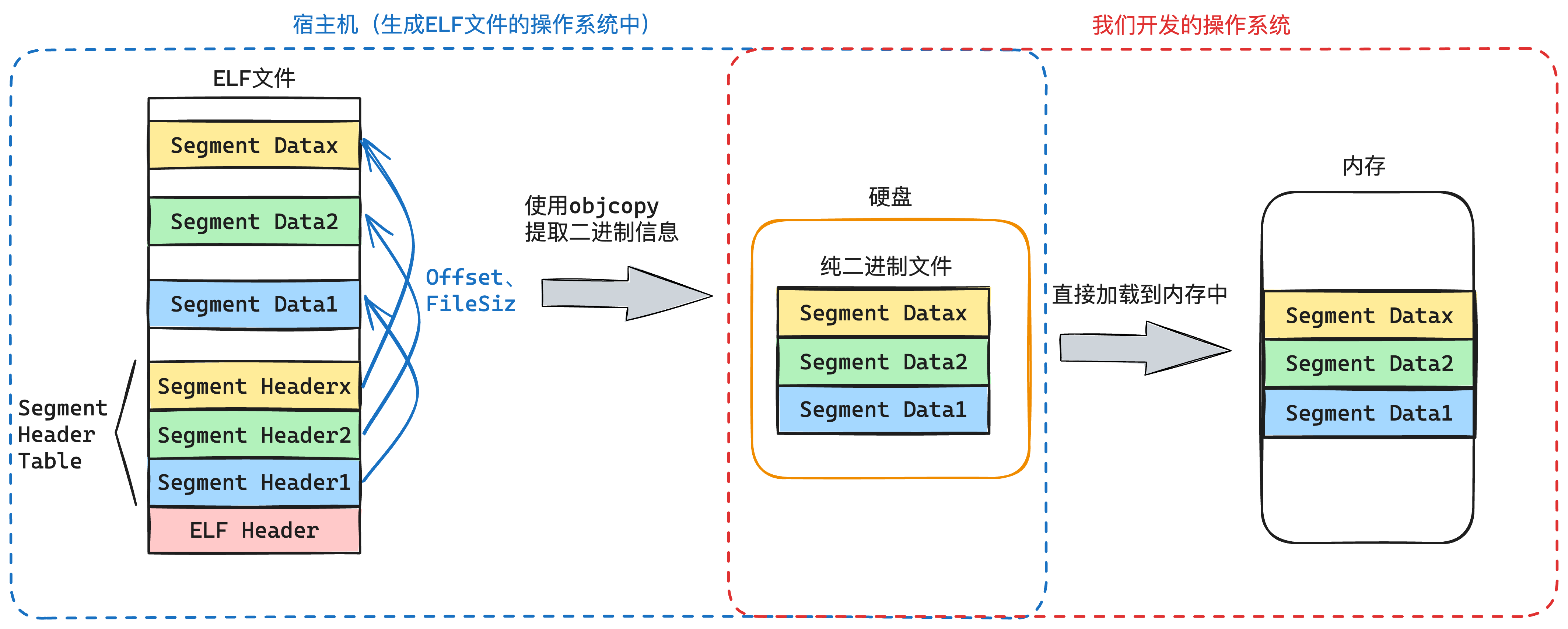
| loader2 | 这里已经是给加载内核做准备了,焦点作用就是「打开分页」以及「加载内核」,具体作用如下:
|
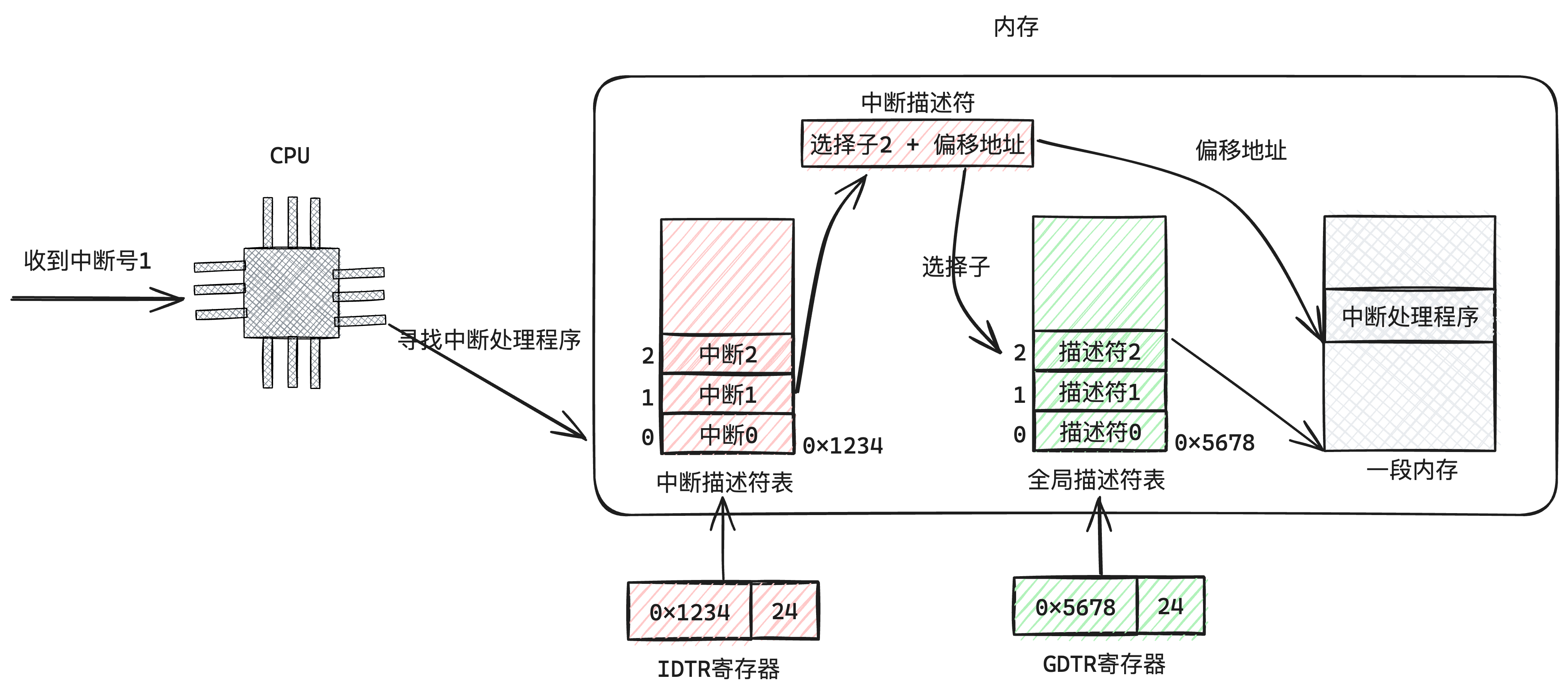
| 停止处理程序 | 停止范例 | 执行的操作 |
| general protection | CPU异常 关于异常可以看这里:Exceptions - OSDev Wiki | 通用掩护异常。通常是低特权级下访问高级资源 |
| double fault | 一般是在停止处理程序里发生异常。以是异常“double”了 | |
| page fault | 一般是访问一个页表没有映射的内存,以是找不到页 | |
| invalid code | 指令非法。遇到过,一般是编译有点问题。 | |
| 时钟停止 | 硬件停止 | 定时触发,停止的频率可以设置 |
| 键盘停止 | 键盘按下,生成扫描码 | |
| 主ATA通道停止 | 硬盘信号停止 | |
| 次ATA通道停止 | 硬盘信号停止 | |
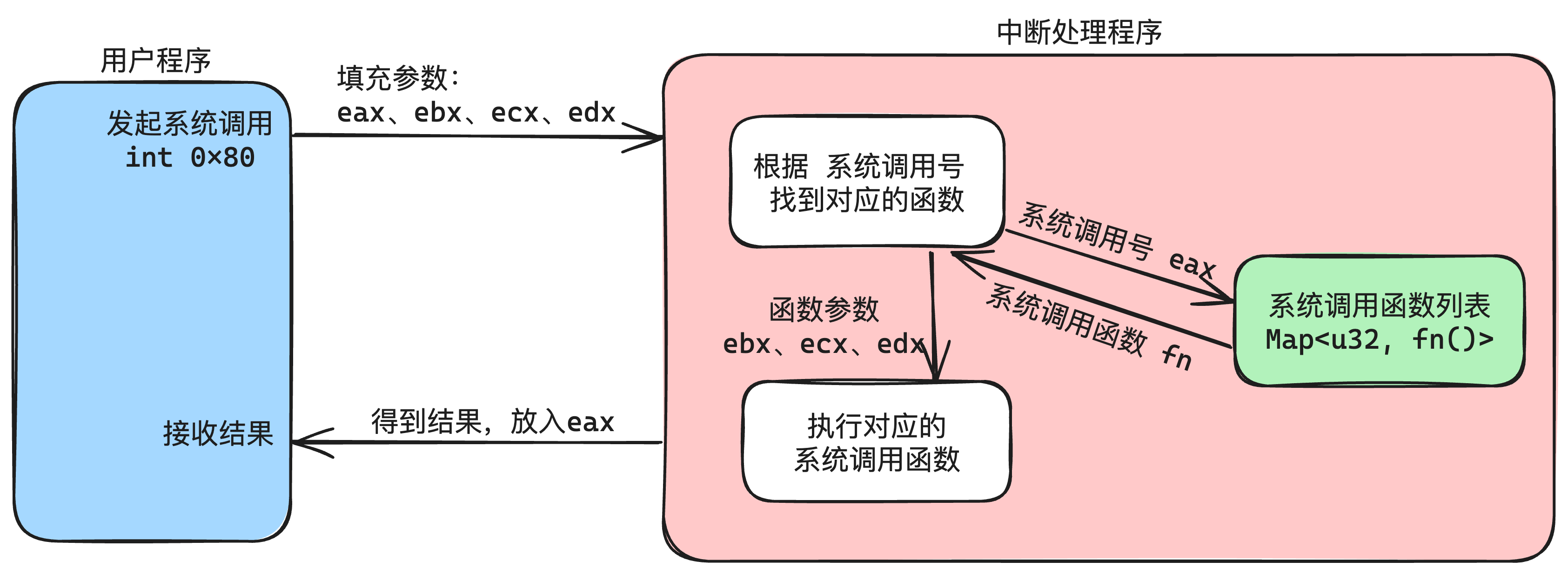
| 系统调用停止0x80 | 软件停止 | 代码指令中使用int指令发起停止 |
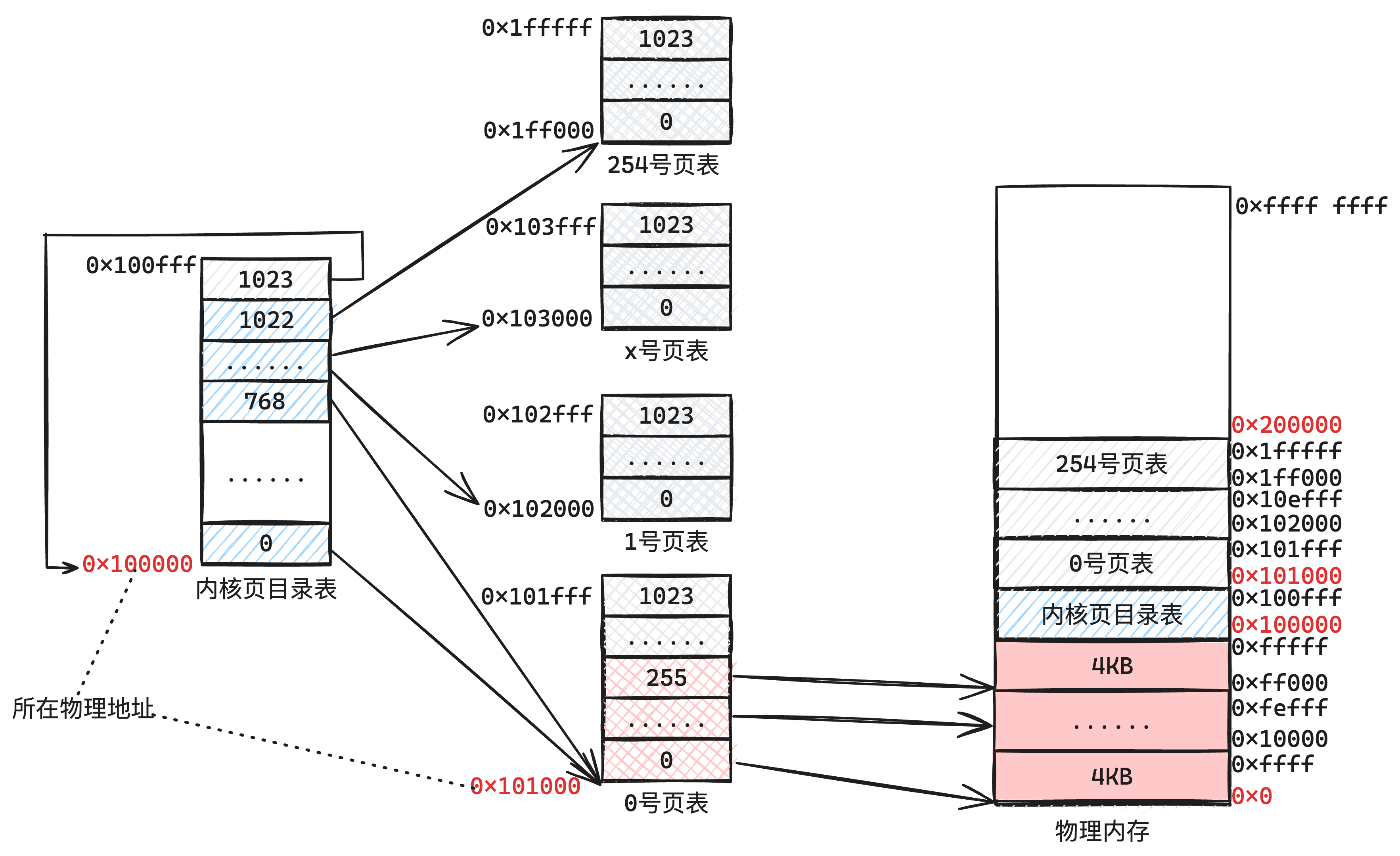
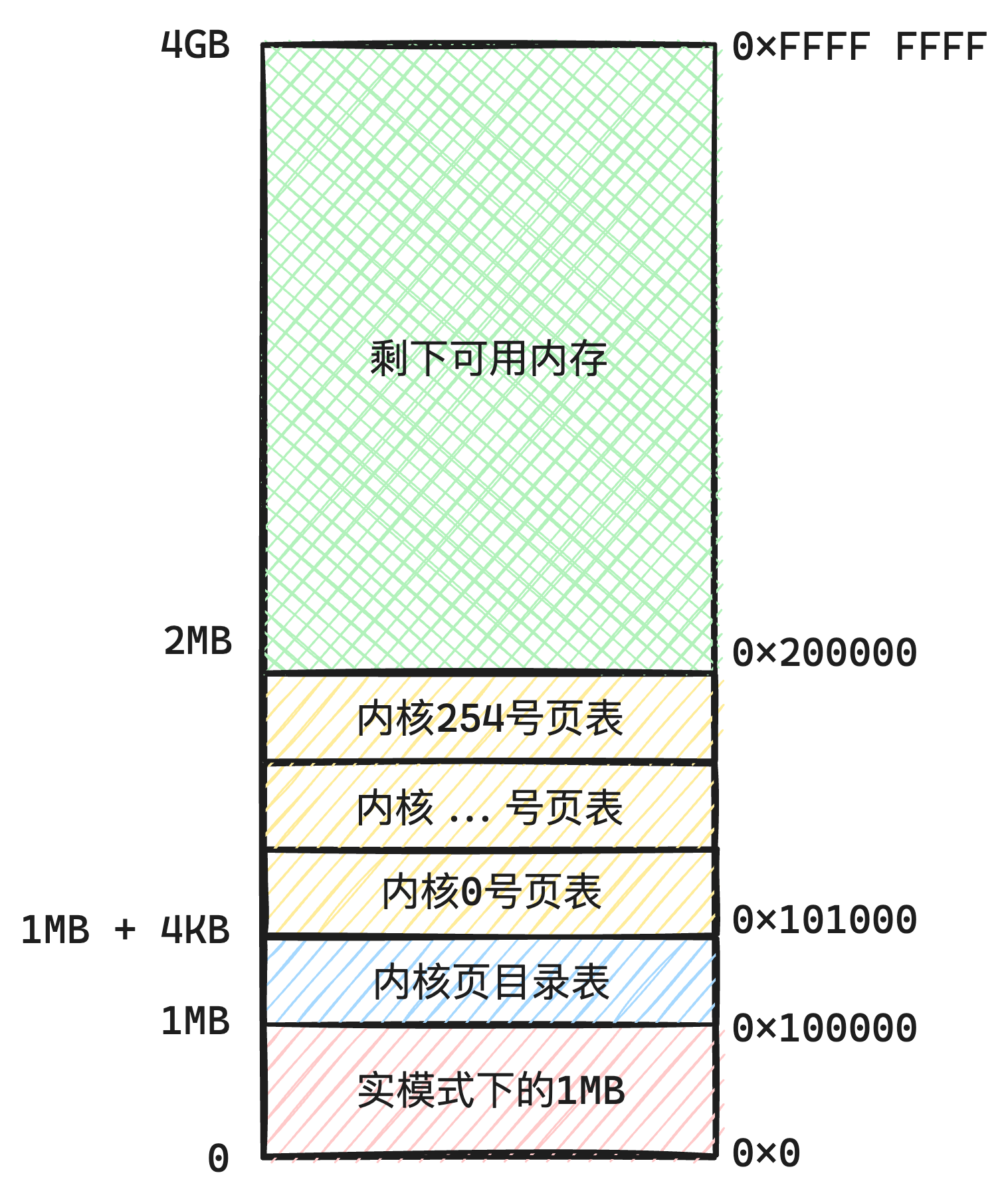
| 操作内存范例 | 阐明 |
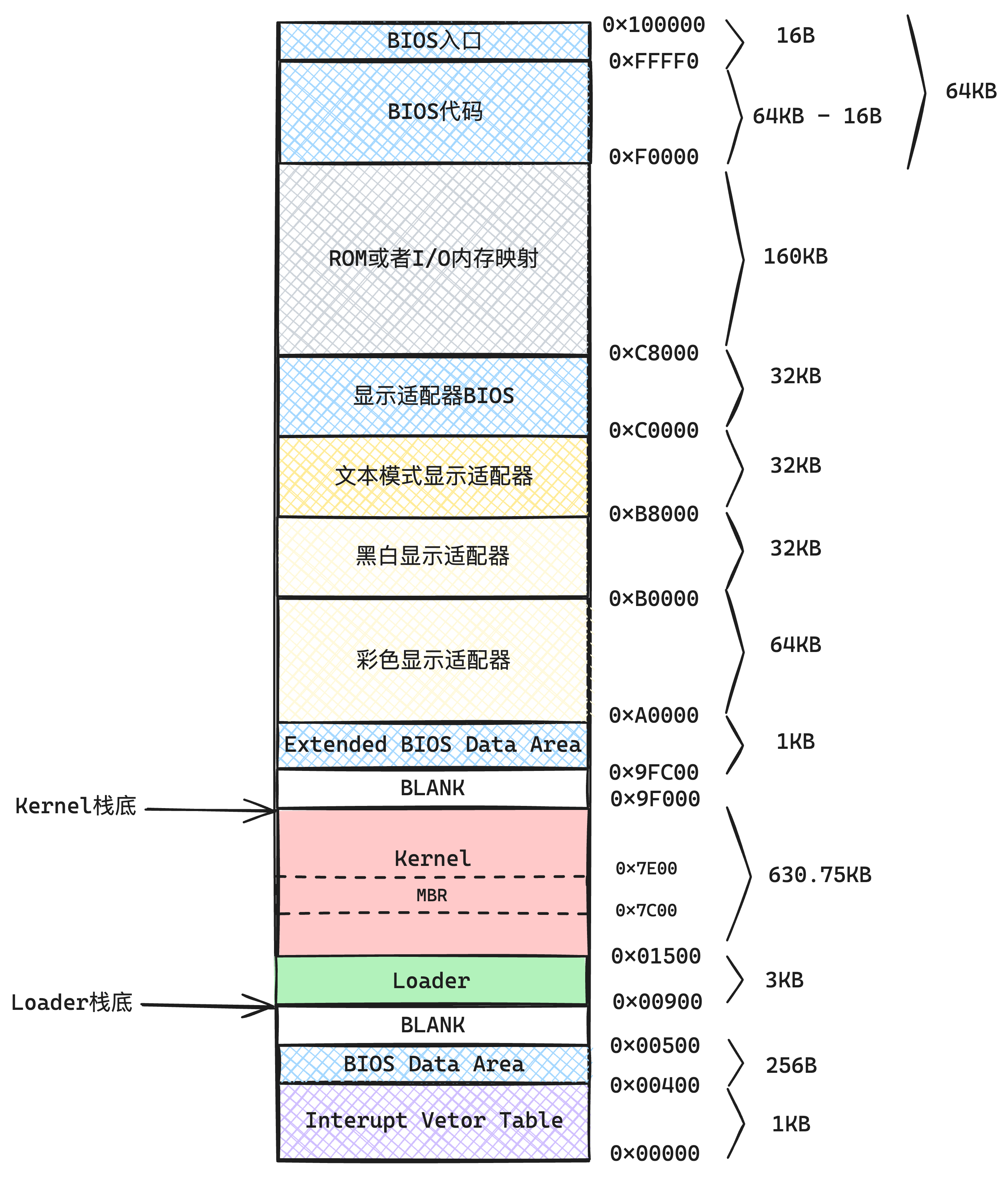
| 非管控的内存 | 首先内核代码本身加载到内存了,需要一个内存空间存放,这一块空间包罗了:
|
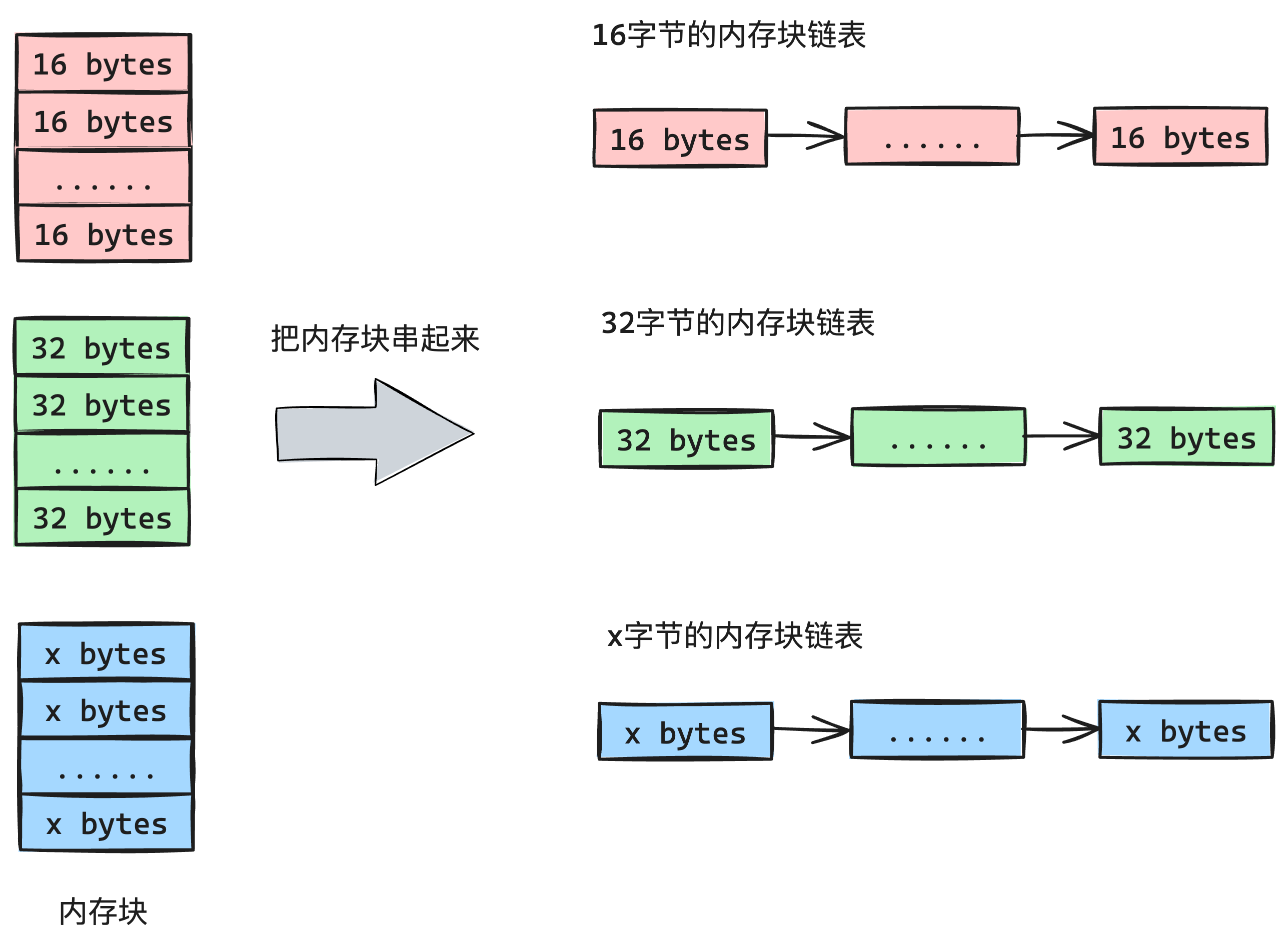
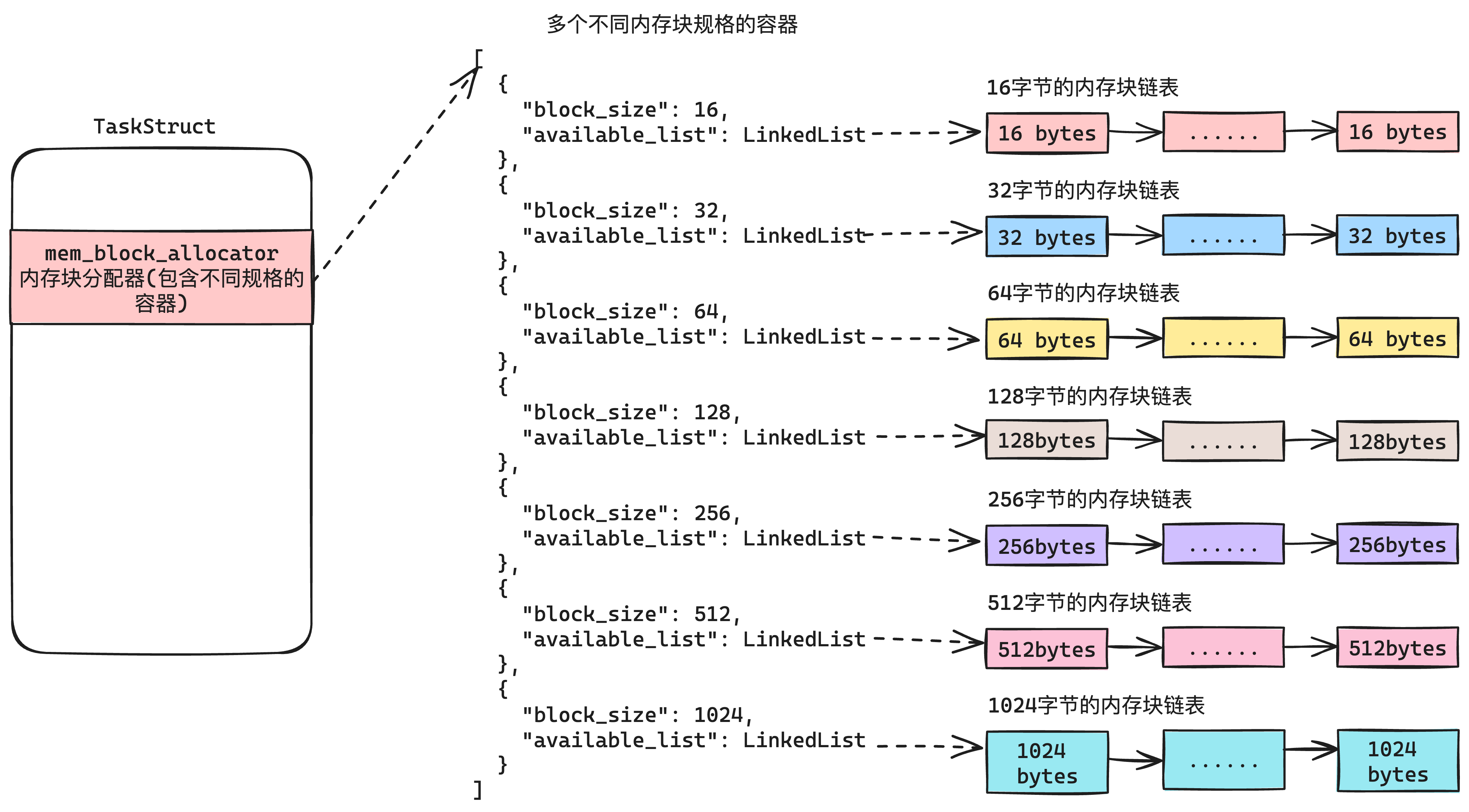
| 内存管理的内存 | 剩下的就是被内存管理模块管控的内存,提供口子同一在这里申请和释放内存 |
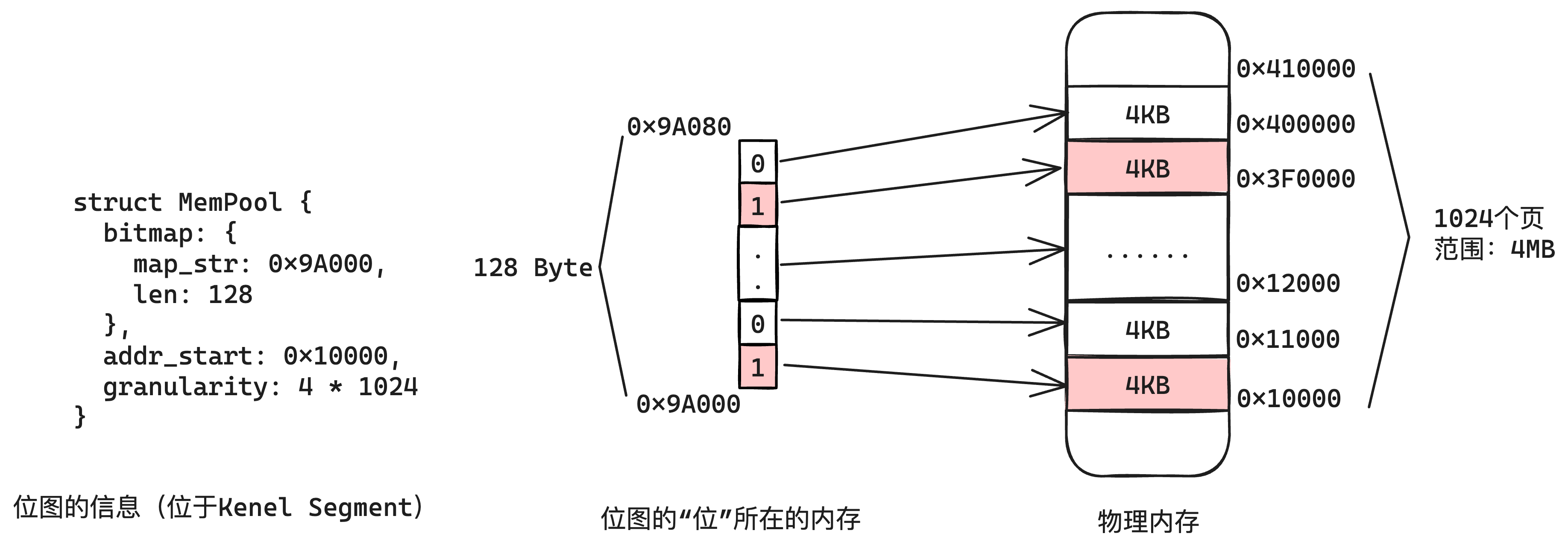
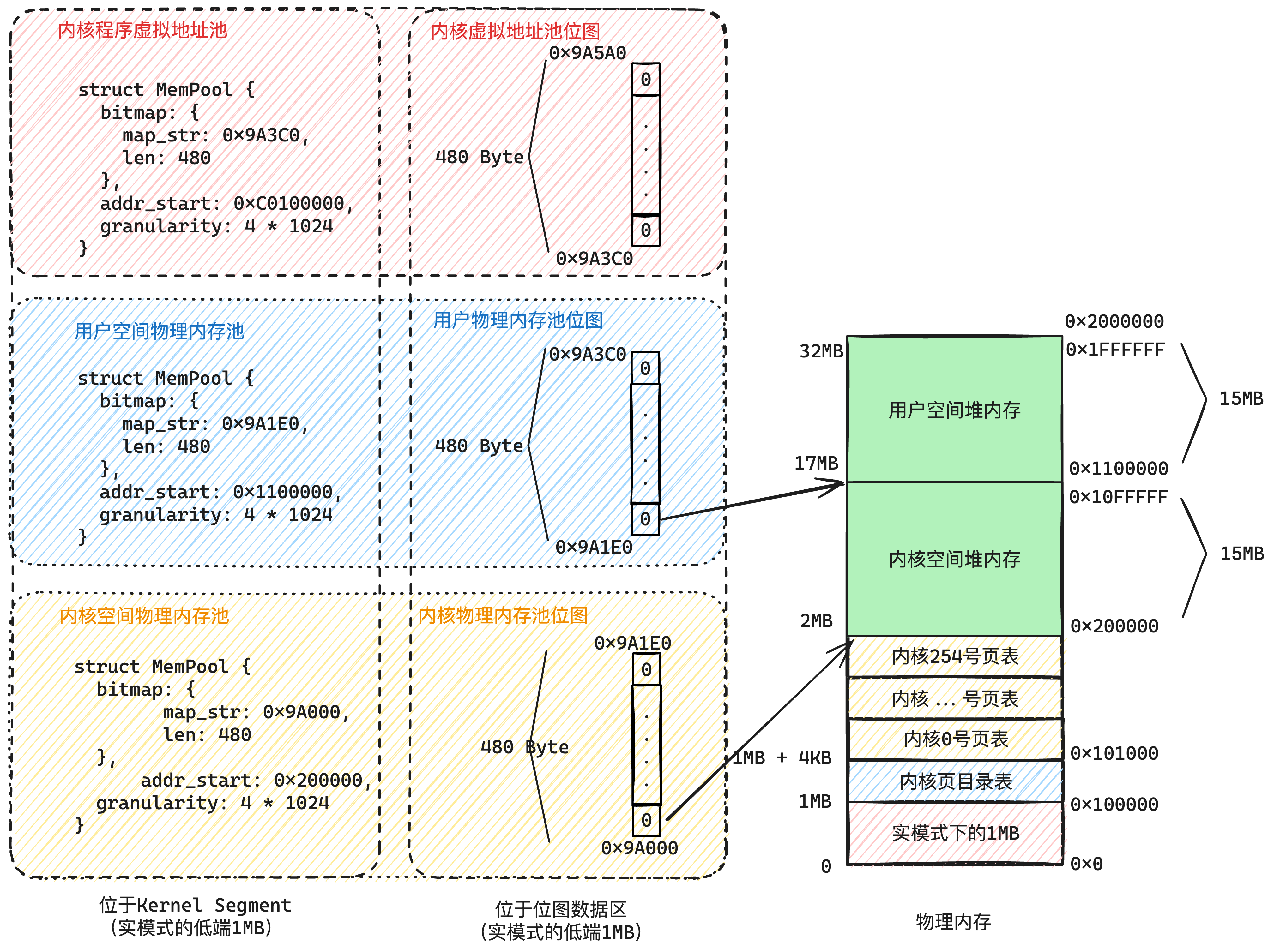
| 内存池名称 | 范例 | 代表的地址范围 | 位图地址 |
| 内核物理内存池 | 物理内存池 | [0x200000, 0x11000000) 总15MB 物理内存 | [0x9A000, 0x9A1E0) 总480 bytes |
| 用户物理内存池 | [0x11000000, 0x2000000] 总15MB 物理内存 | [0x9A1E0, 0x9A3C0) 总480 bytes | |
| 内核虚拟地址池 | 虚拟地址池 | [0xC000 0000, 0xC0F0 0000) 总15MB,逻辑上虚拟的 | [0x9A3C0, 0x9A5A0) 总480 bytes |
| 用户虚拟地址池 (每个用户进程都有1个) | [0x8048000, 0xC000 0000) 约总2.88GB,逻辑上虚拟的 | 动态申请的地址 总92KB(23页) |

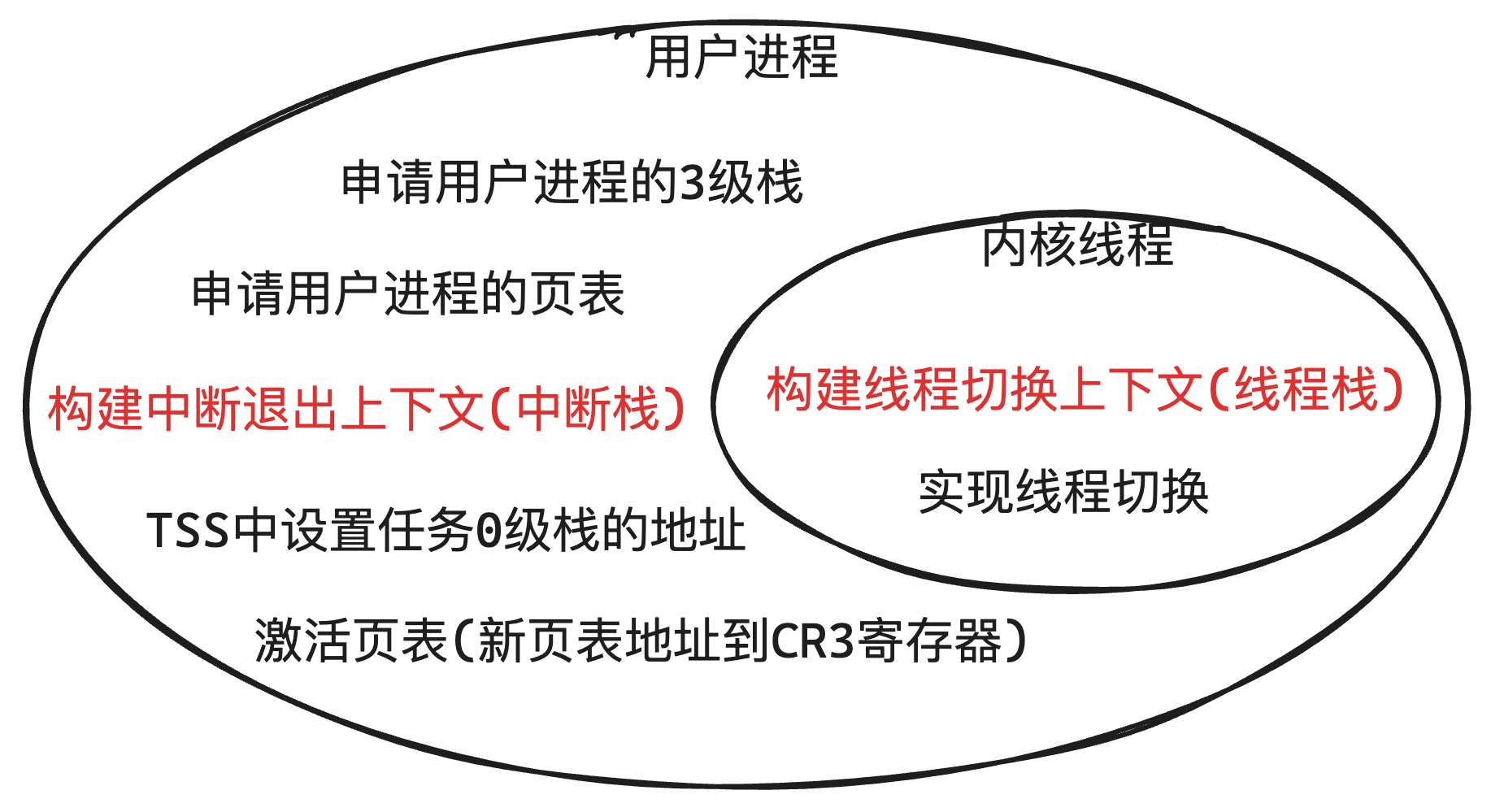
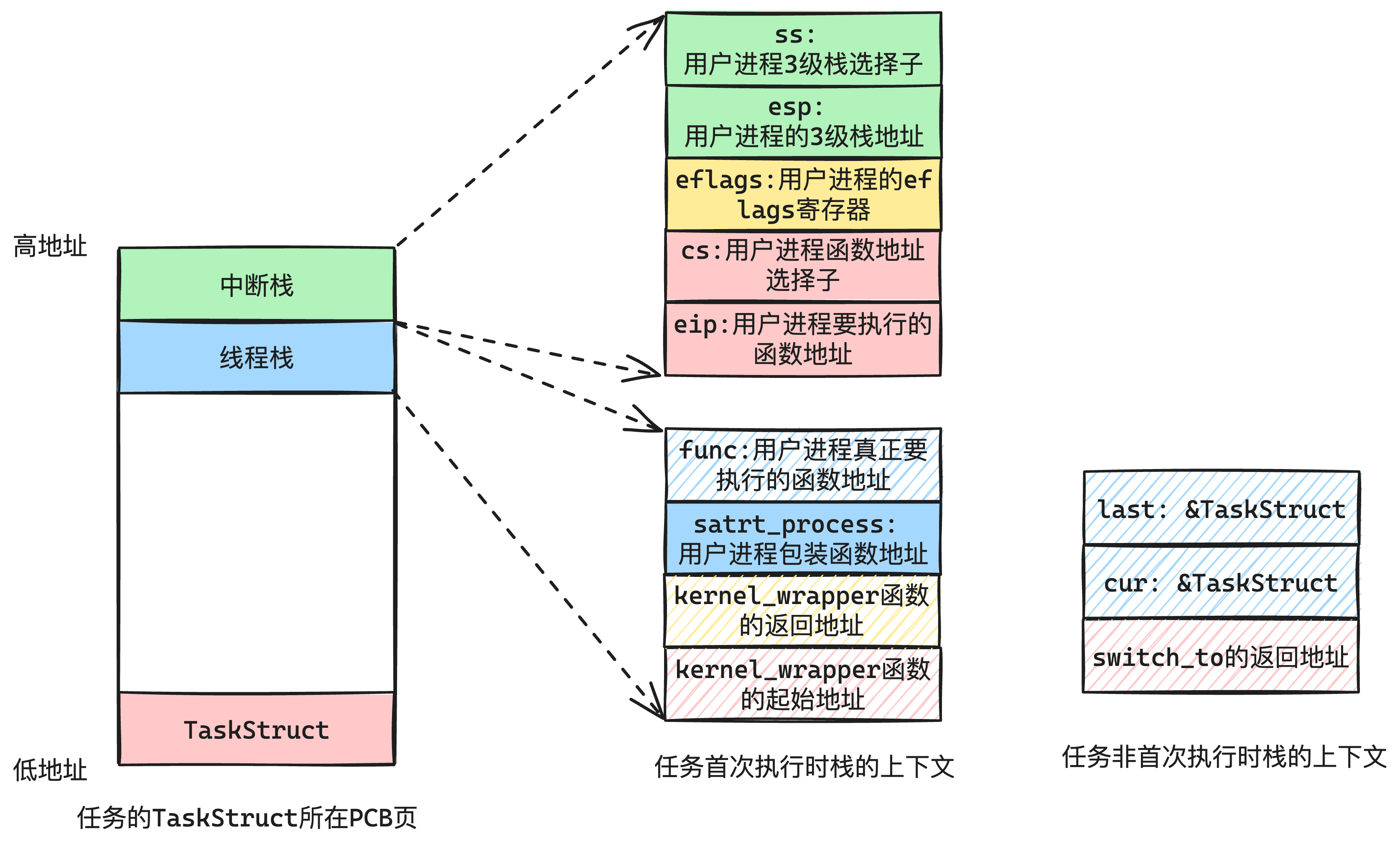
| 内核线程 | 用户进程 | |
| 运行时所处的特权级 | 0级 | 3级(停止处理程序时是0级) |
| 使命PCB | 申请1页(内核空间) | 申请1页(内核空间) |
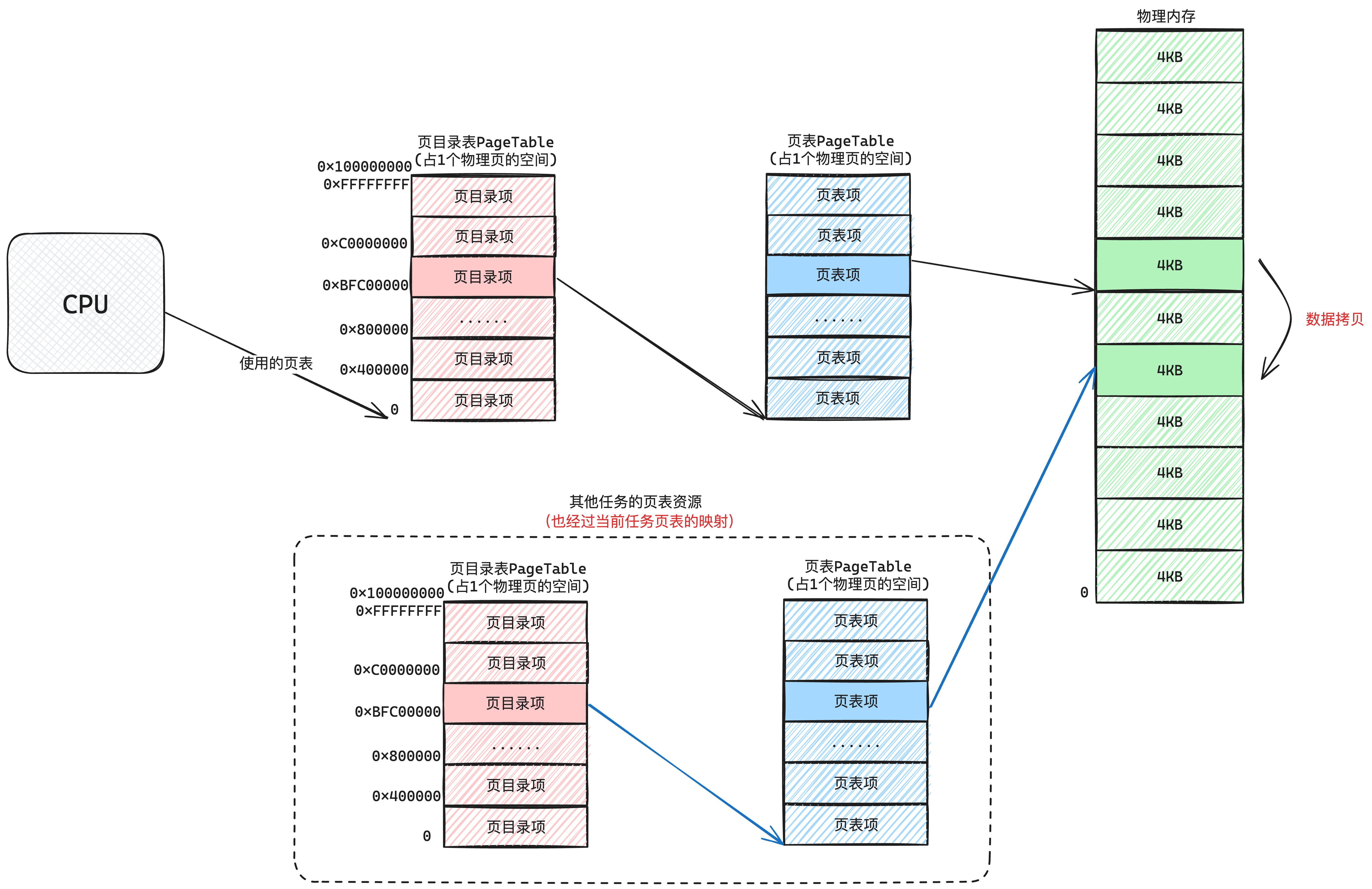
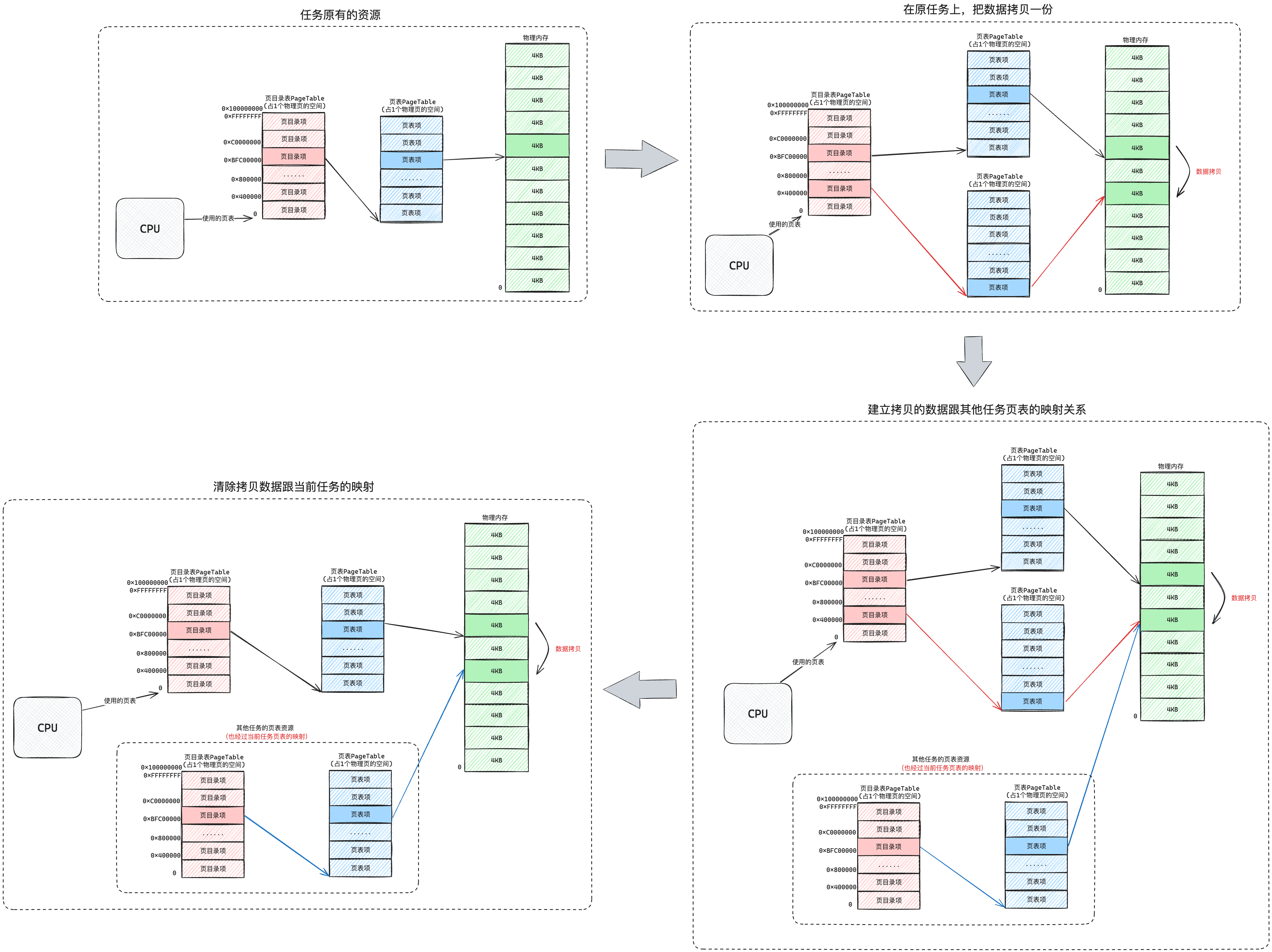
| 虚拟地址池 | 全部内核线程共用一个虚拟地址池 总可用虚拟地址的范围是: [0xC001 0000, 0xFFFF FFFF] | 每个进程有各自的虚拟地址池 每个地址池的地址范围是:[0x804 8000, 0xC000 0000) |
| 页表 | 全部内核线程共用一个页目次表 | 每个用户进程有各自的页目次表 |
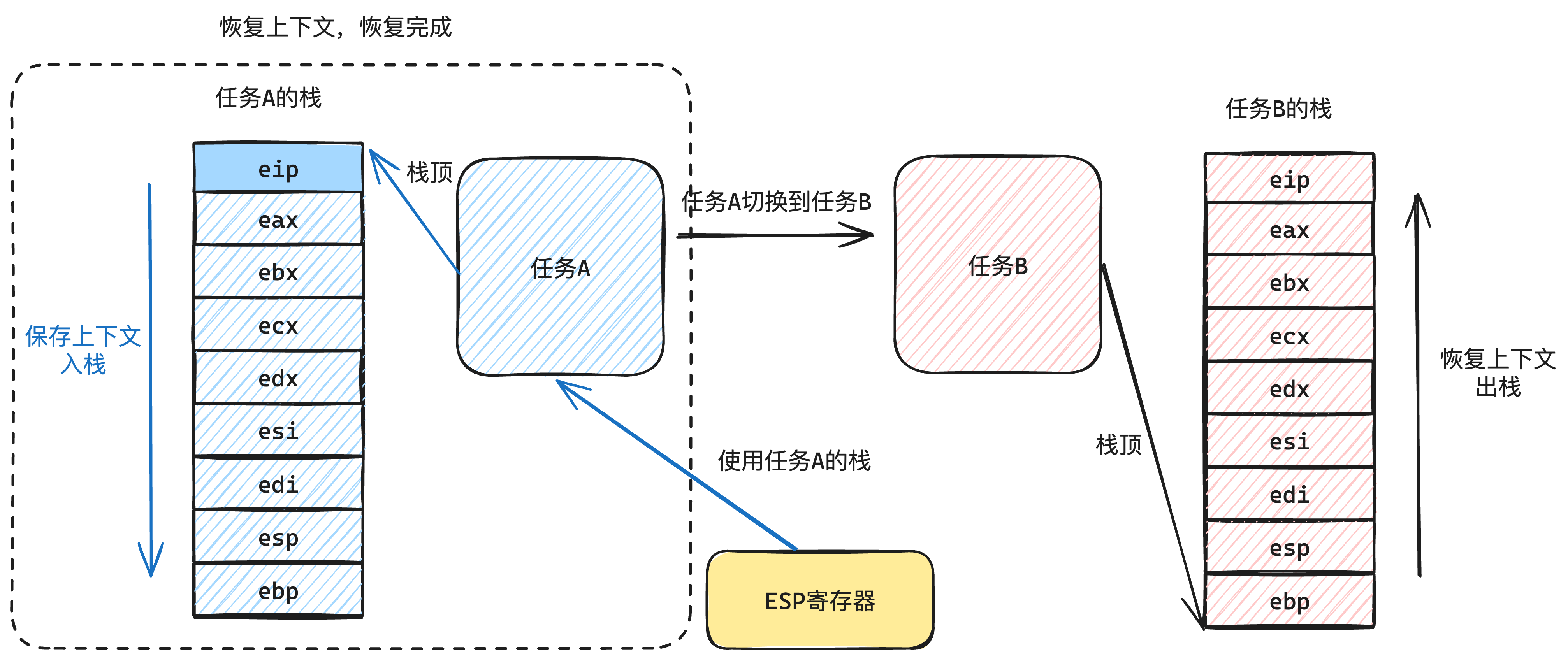
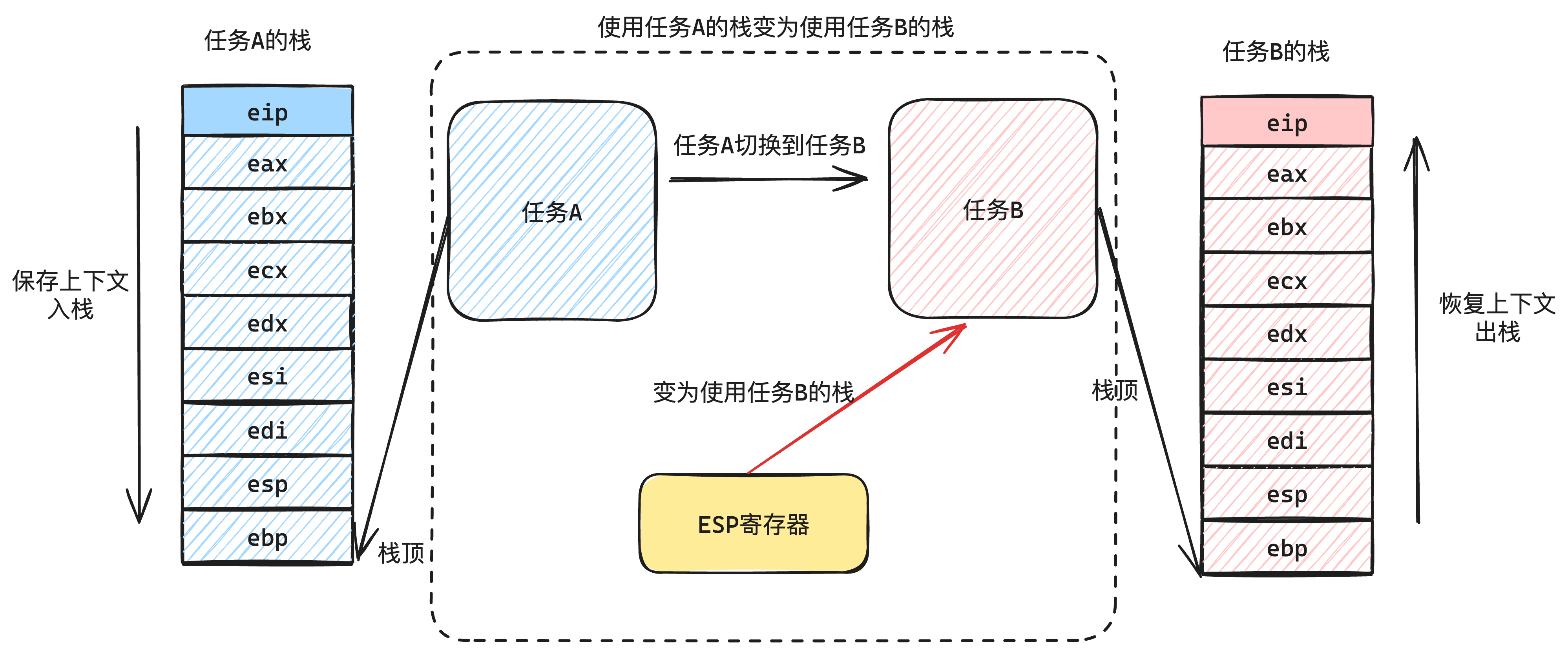
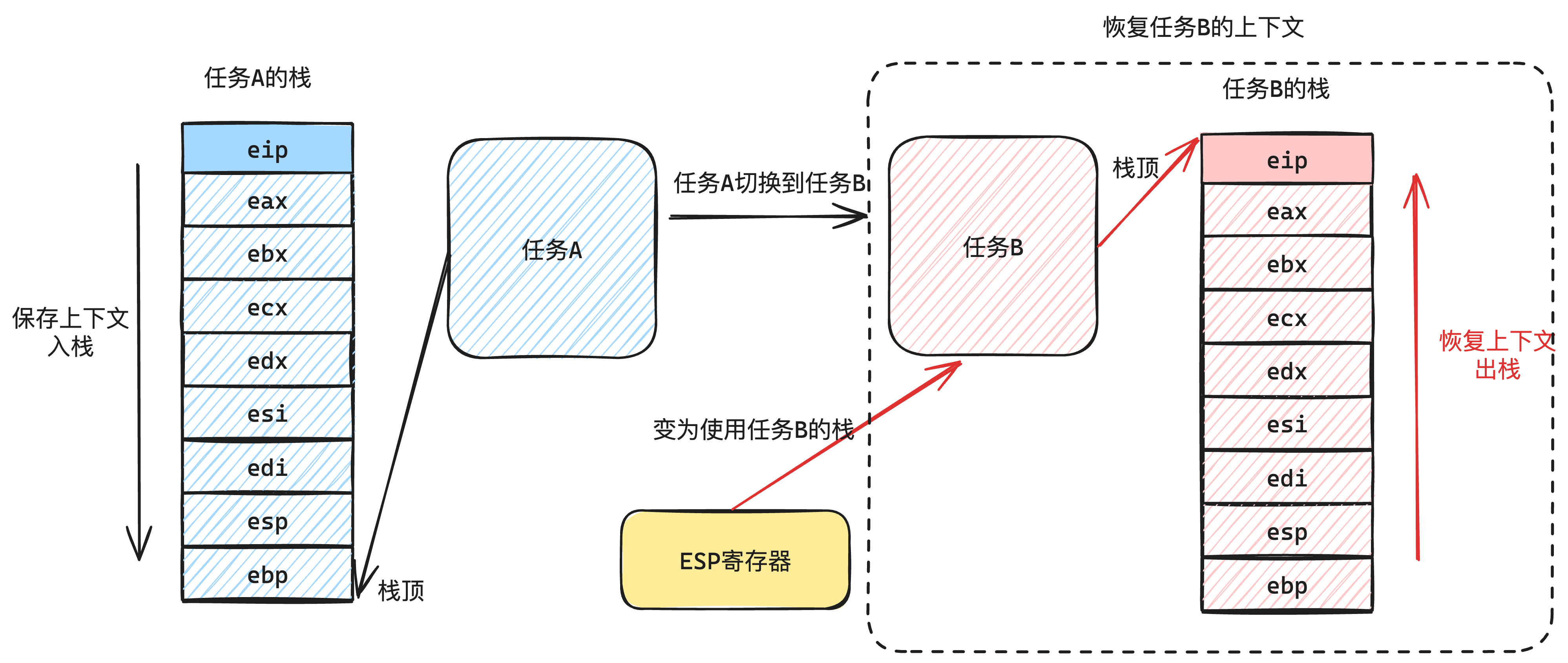
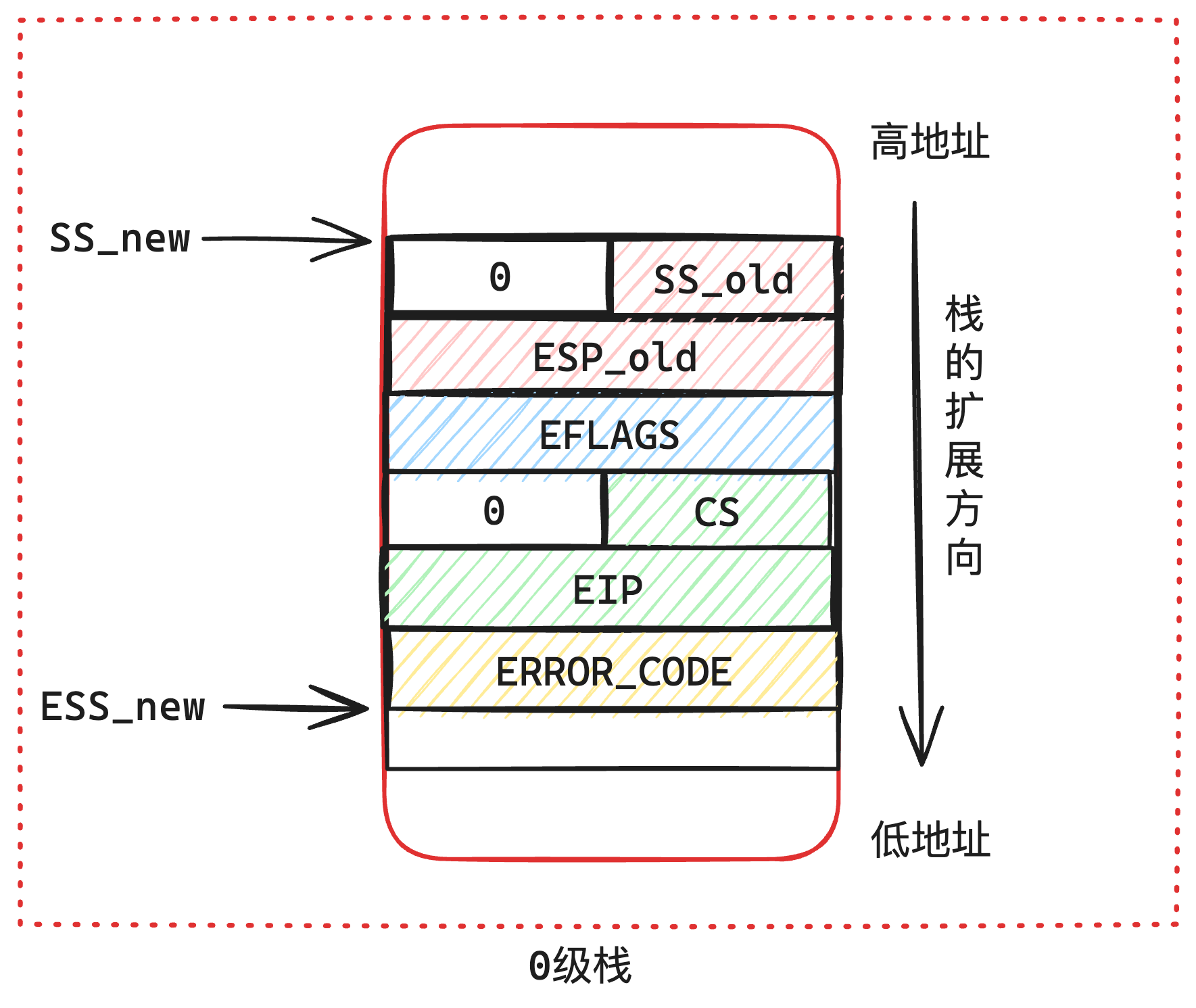
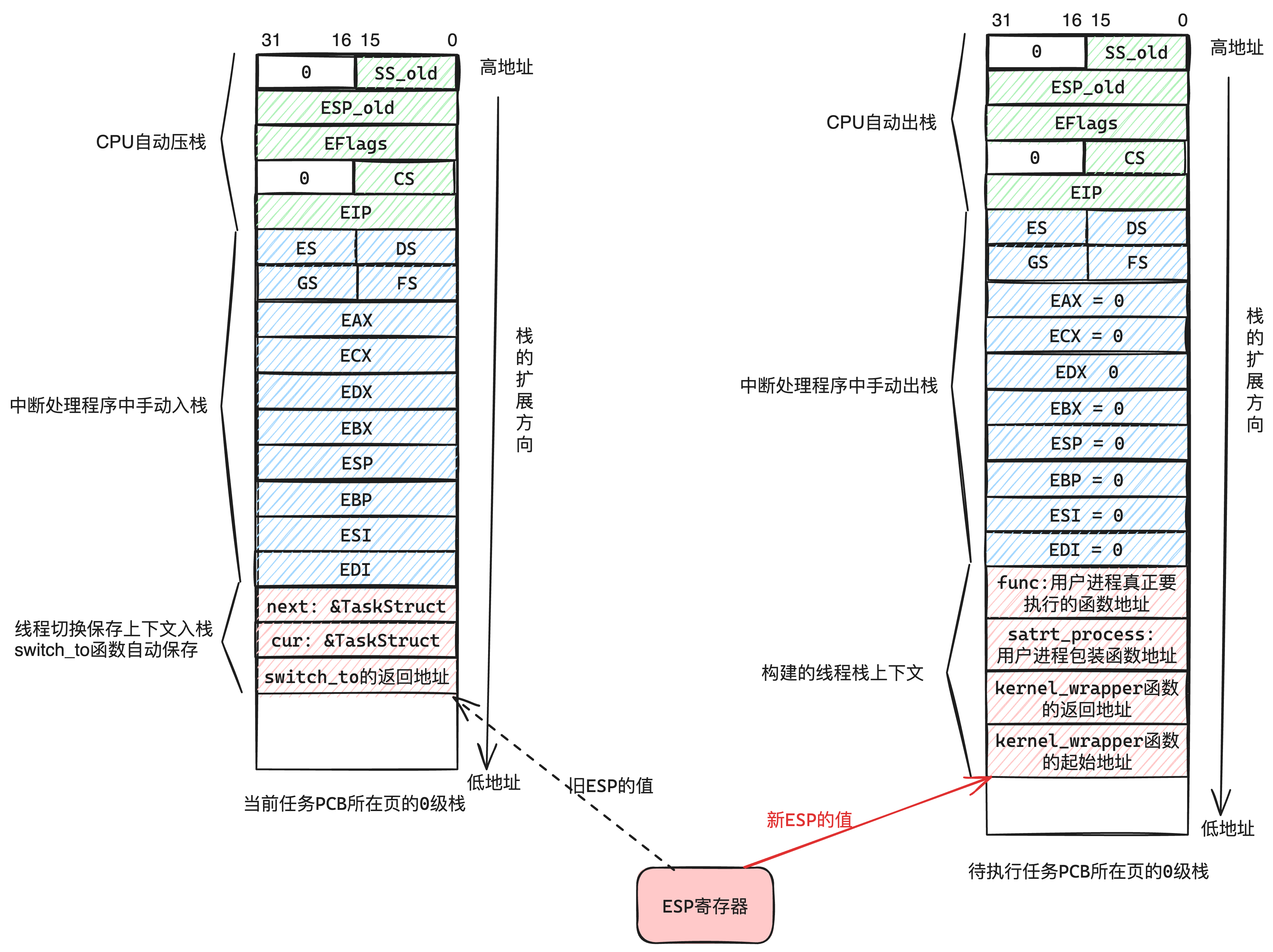
| 栈空间分布 | 只有0级栈(跟PCB共用1页) |
|
| 栈空间的使用 | 停止和非停止都使用1个栈,被执行时需要把0级栈地址放到TSS | 非停止执行时使用3级栈 停止发生时使用0级栈 |
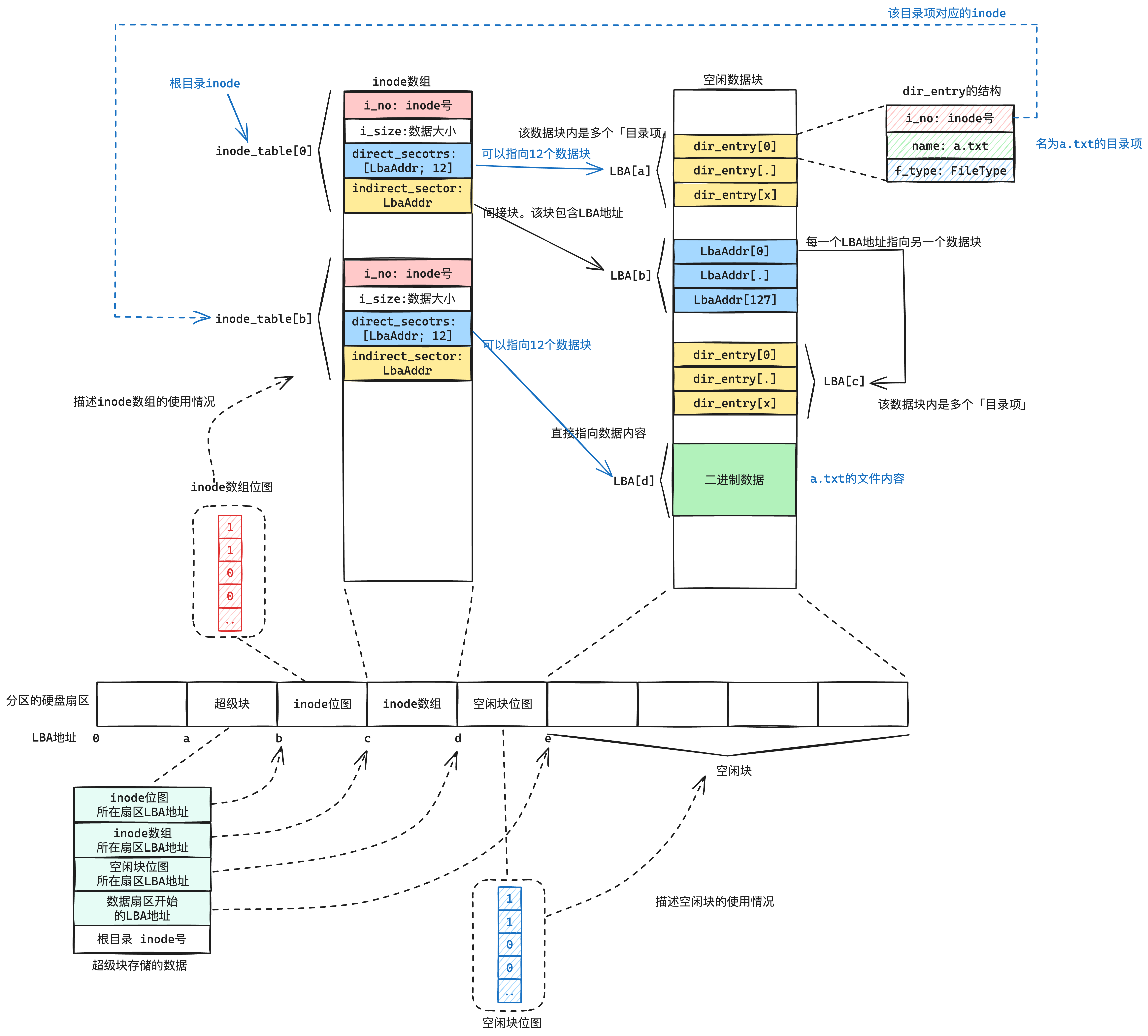


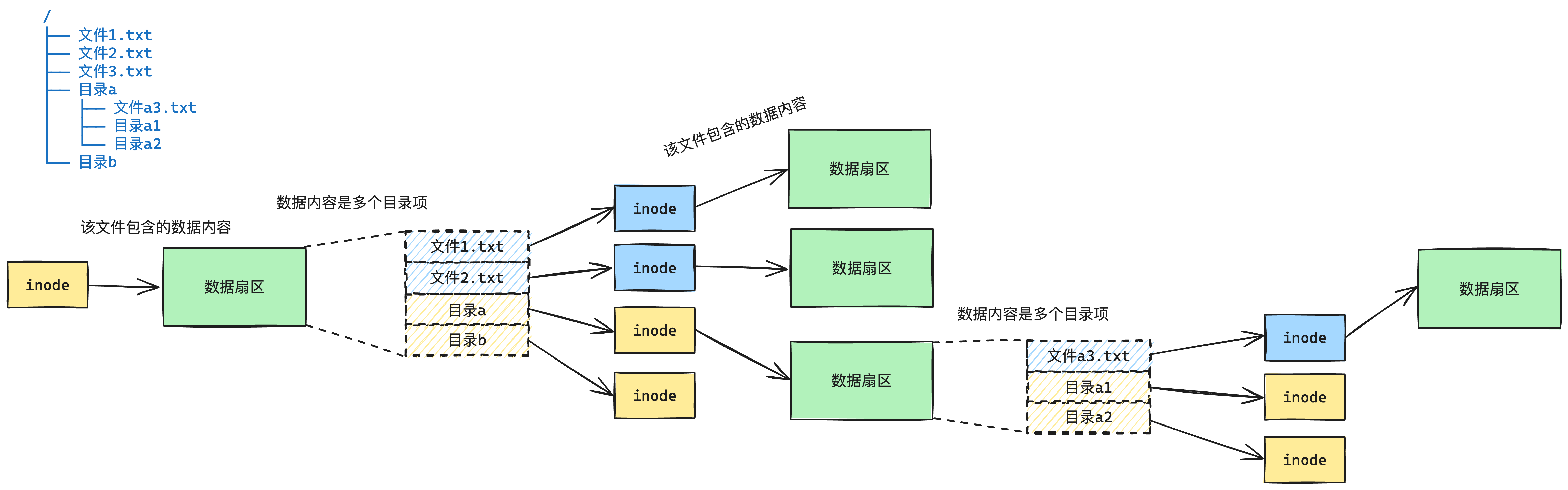
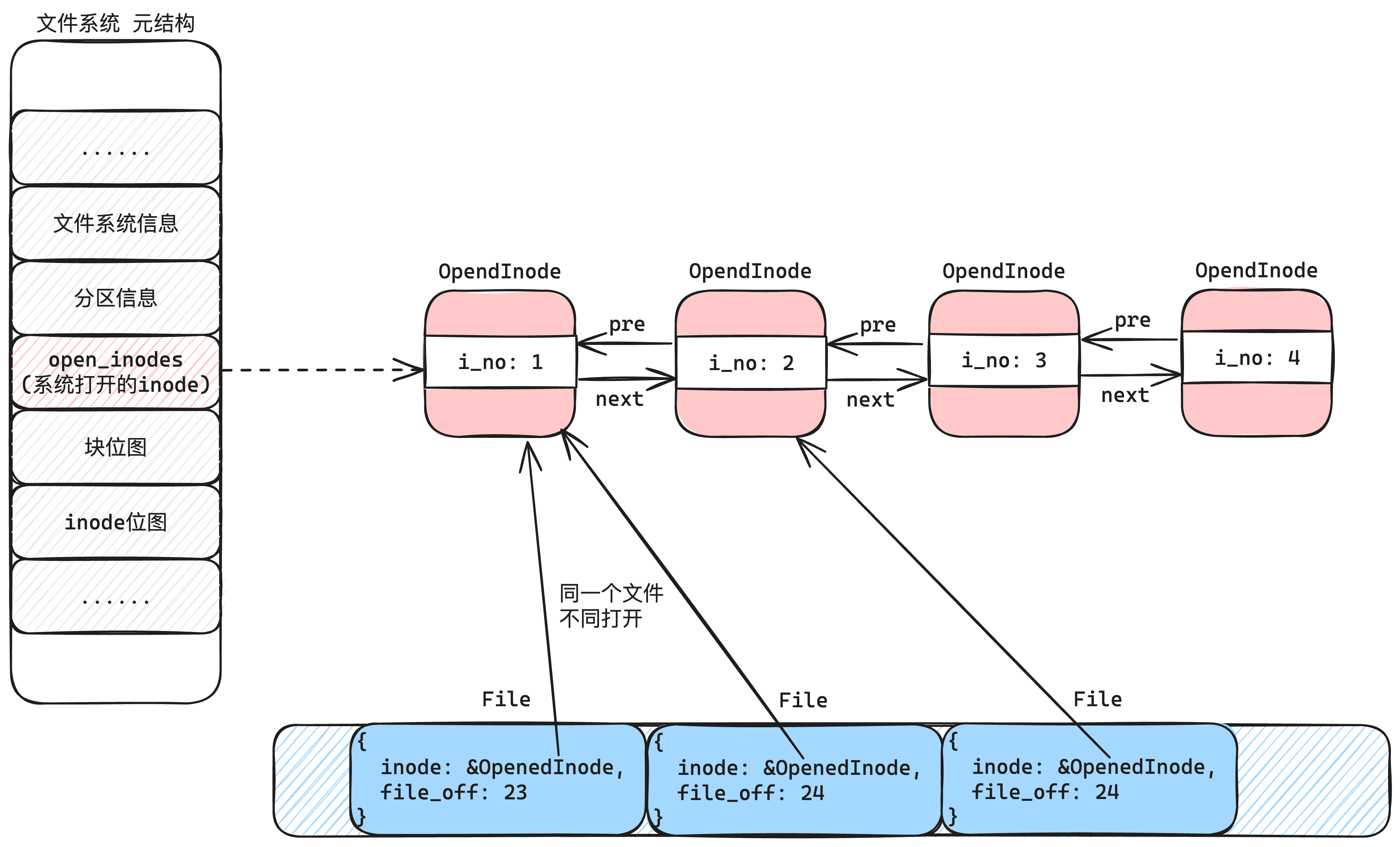
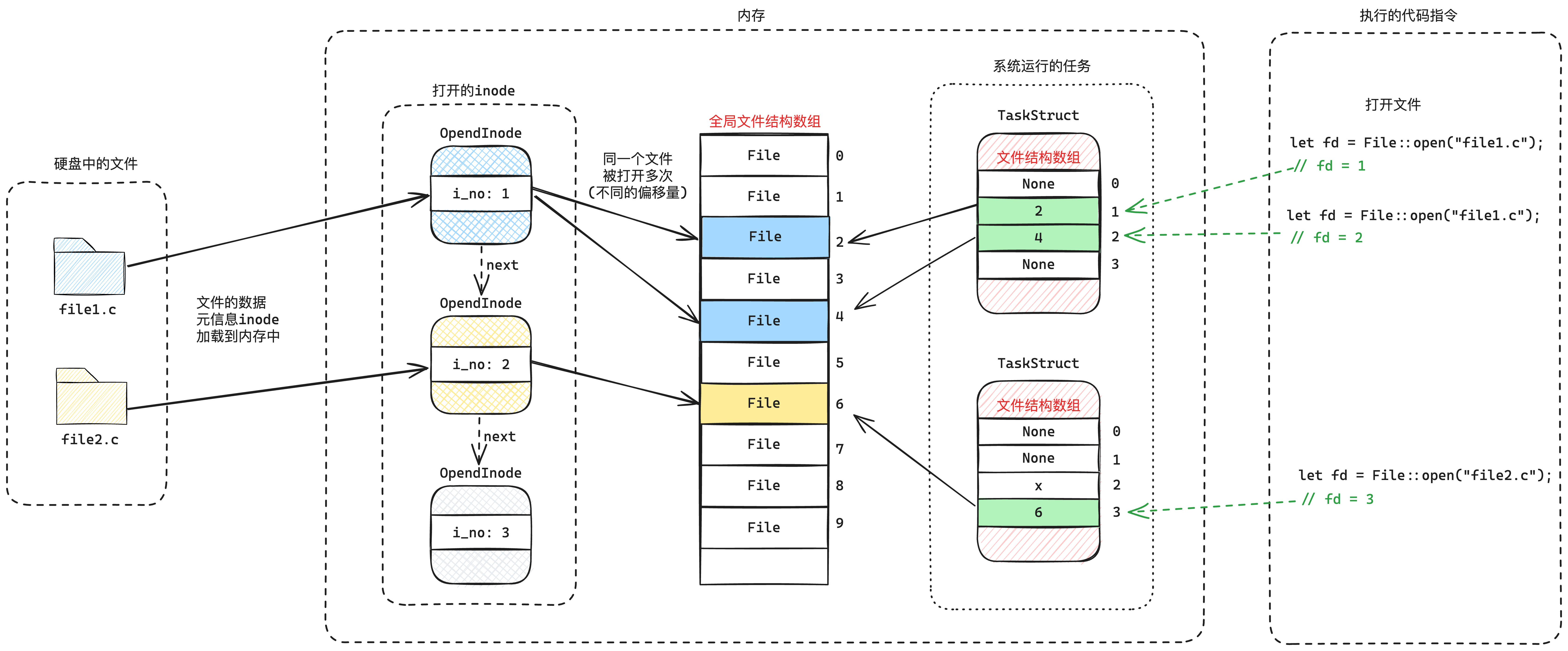

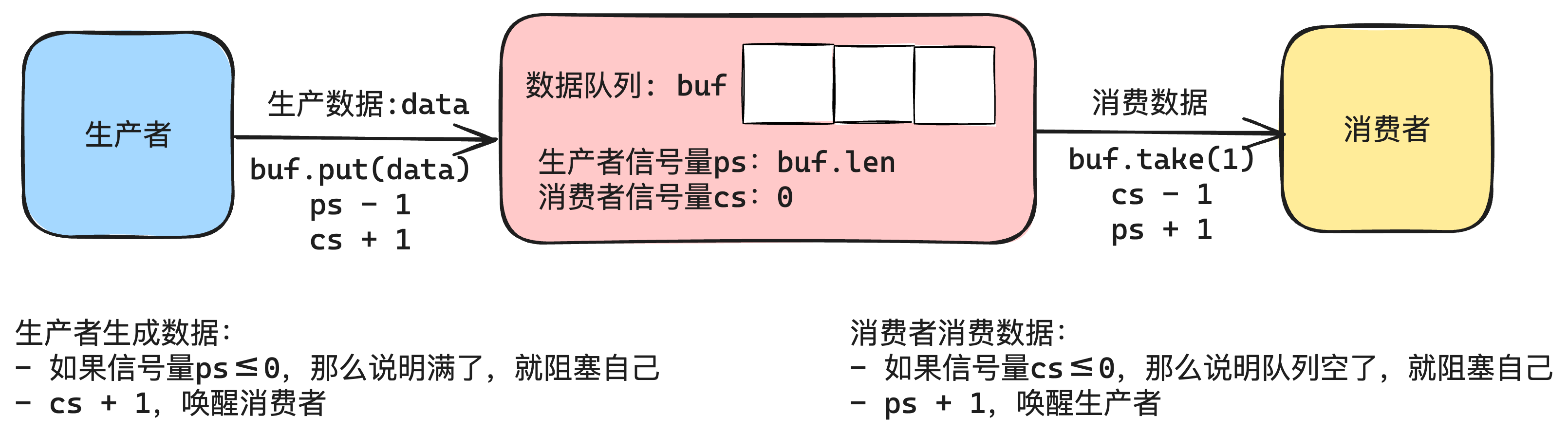
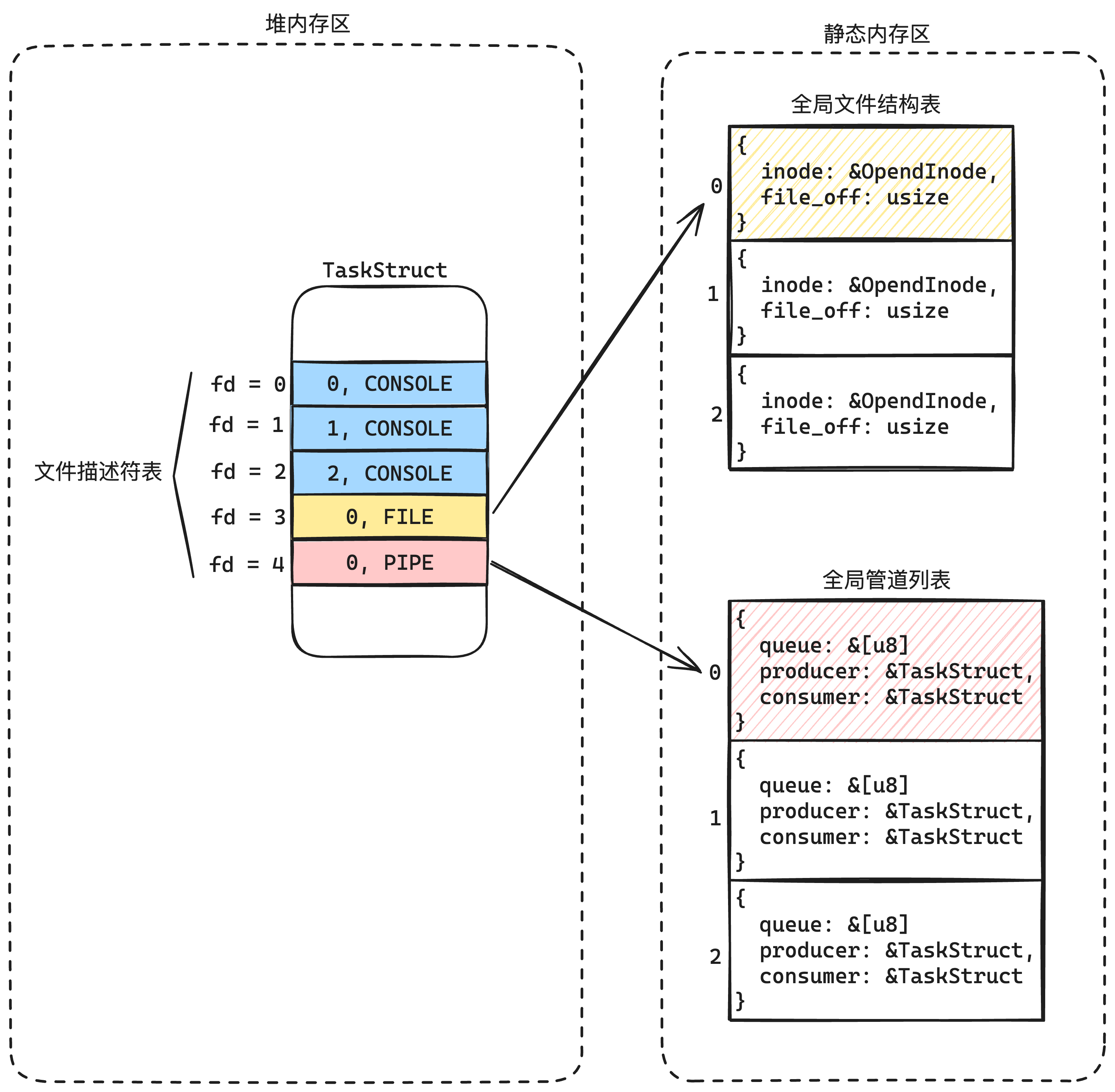
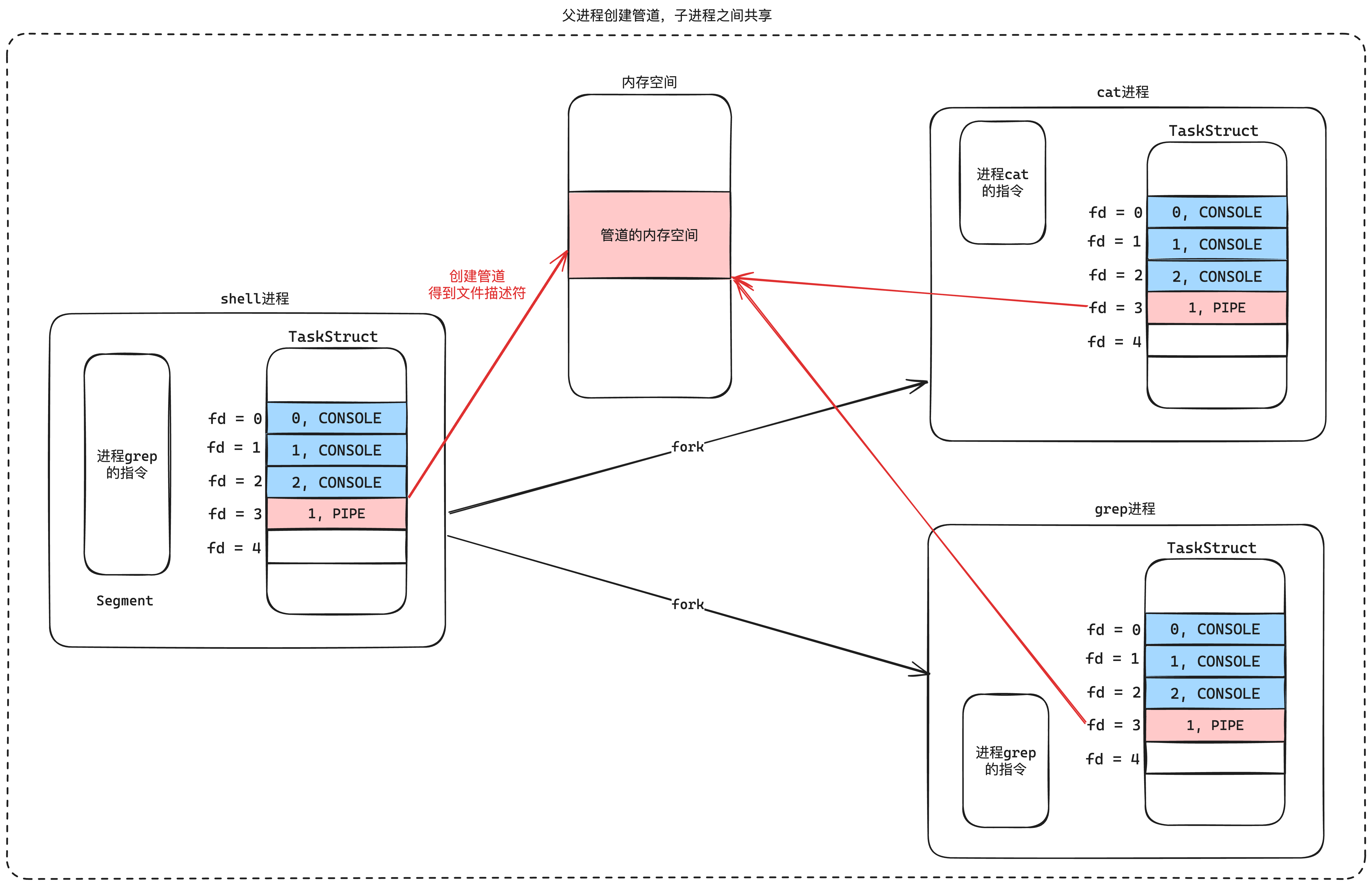


| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.5 |