标题: ES + Redis + MySQL,这个高可用架构设计太顶了! [打印本页] 作者: 天空闲话 时间: 2022-9-16 17:23 标题: ES + Redis + MySQL,这个高可用架构设计太顶了! 文章来源:【公众号:同程艺龙技术中心】 背景
会员系统是一种基础系统,跟公司所有业务线的下单主流程密切相关。如果会员系统出故障,会导致用户无法下单,影响范围是全公司所有业务线。所以,会员系统必须保证高性能、高可用,提供稳定、高效的基础服务。
随着同程和艺龙两家公司的合并,越来越多的系统需要打通同程 APP、艺龙 APP、同程微信小程序、艺龙微信小程序等多平台会员体系。
例如微信小程序的交叉营销,用户买了一张火车票,此时想给他发酒店红包,这就需要查询该用户的统一会员关系。
因为火车票用的是同程会员体系,酒店用的是艺龙会员体系,只有查到对应的艺龙会员卡号后,才能将红包挂载到该会员账号。
除了上述讲的交叉营销,还有许多场景需要查询统一会员关系,例如订单中心、会员等级、里程、红包、常旅、实名,以及各类营销活动等等。
所以,会员系统的请求量越来越大,并发量越来越高,今年清明小长假的秒并发 tps 甚至超过 2 万多。
在如此大流量的冲击下,会员系统是如何做到高性能和高可用的呢?这就是本文着重要讲述的内容。 ES 高可用方案 | ES 双中心主备集群架构
同程和艺龙两家公司融合后,全平台所有体系的会员总量是十多亿。在这么大的数据体量下,业务线的查询维度也比较复杂。
有的业务线基于手机号,有的基于微信 unionid,也有的基于艺龙卡号等查询会员信息。
这么大的数据量,又有这么多的查询维度,基于此,我们选择 ES 用来存储统一会员关系。ES 集群在整个会员系统架构中非常重要,那么如何保证 ES 的高可用呢?
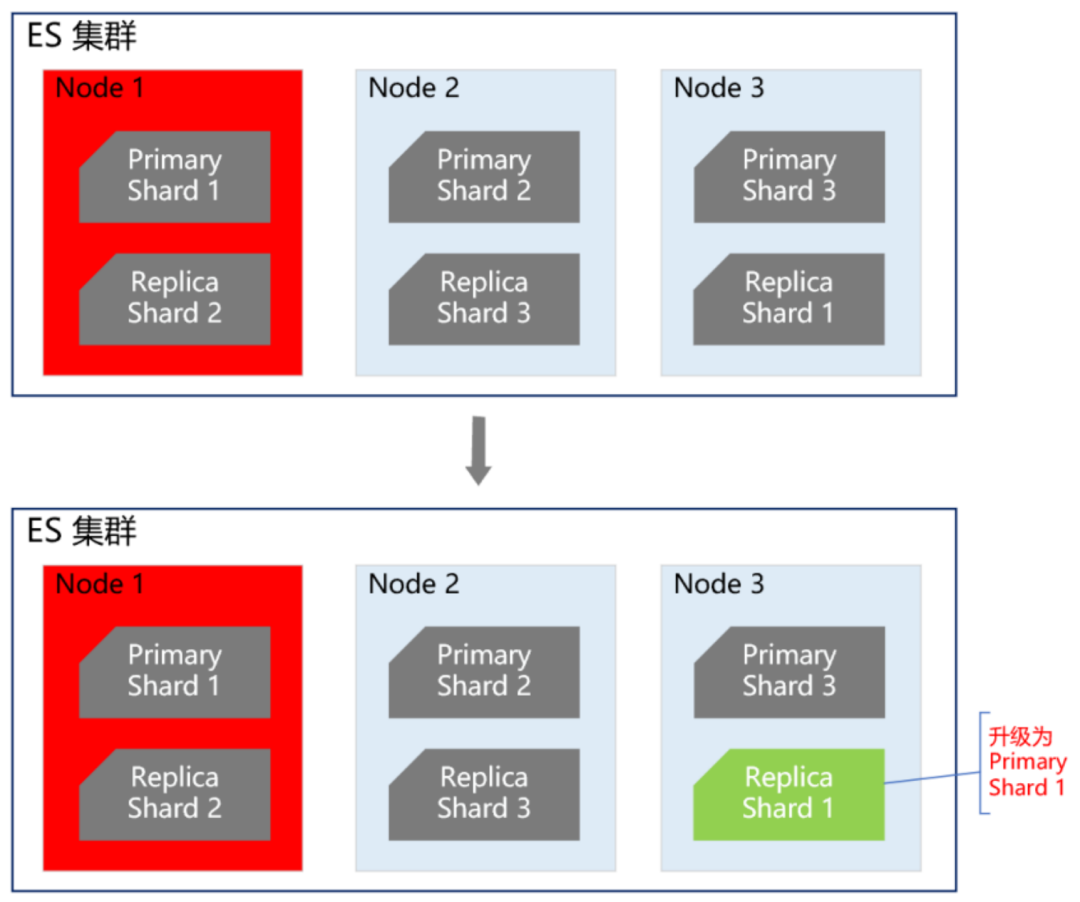
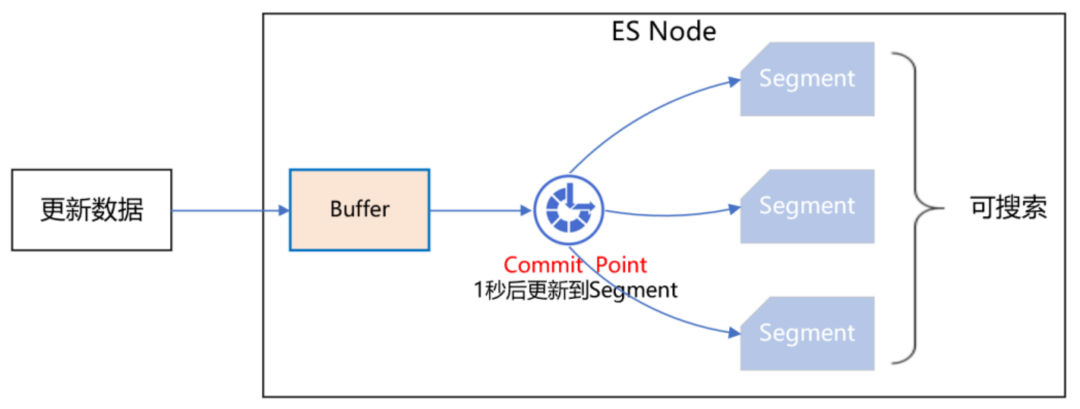
首先我们知道,ES 集群本身就是保证高可用的,如下图所示:
当 ES 集群有一个节点宕机了,会将其他节点对应的 Replica Shard 升级为 Primary Shard,继续提供服务。
但即使是这样,还远远不够。例如 ES 集群都部署在机房 A,现在机房 A 突然断电了,怎么办?
例如服务器硬件故障,ES 集群大部分机器宕机了,怎么办?或者突然有个非常热门的抢购秒杀活动,带来了一波非常大的流量,直接把 ES 集群打死了,怎么办?面对这些情况,让运维兄弟冲到机房去解决?
这个非常不现实,因为会员系统直接影响全公司所有业务线的下单主流程,故障恢复的时间必须非常短,如果需要运维兄弟人工介入,那这个时间就太长了,是绝对不能容忍的。
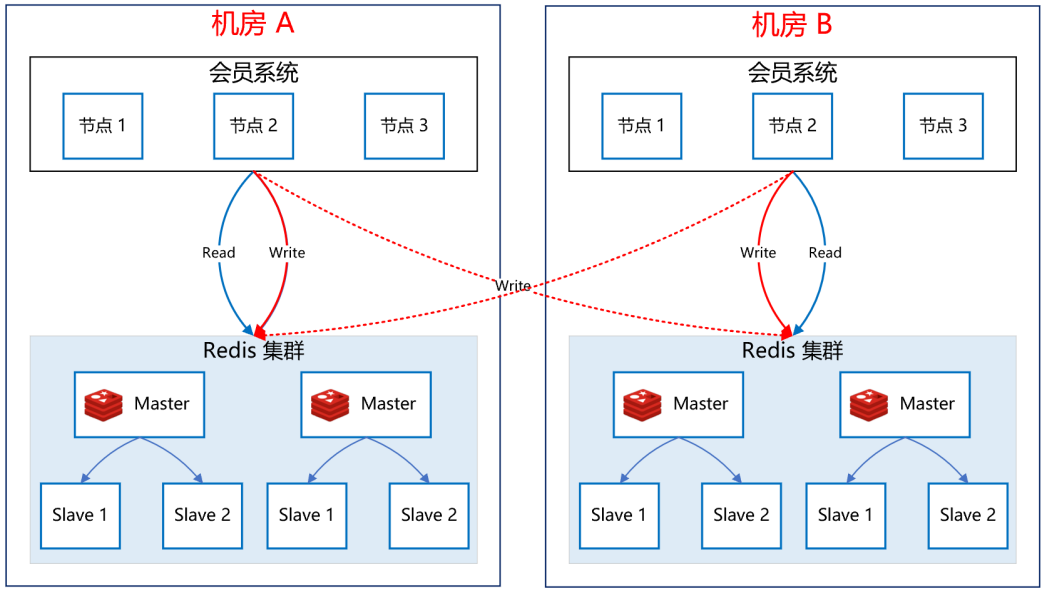
那 ES 的高可用如何做呢?我们的方案是 ES 双中心主备集群架构。
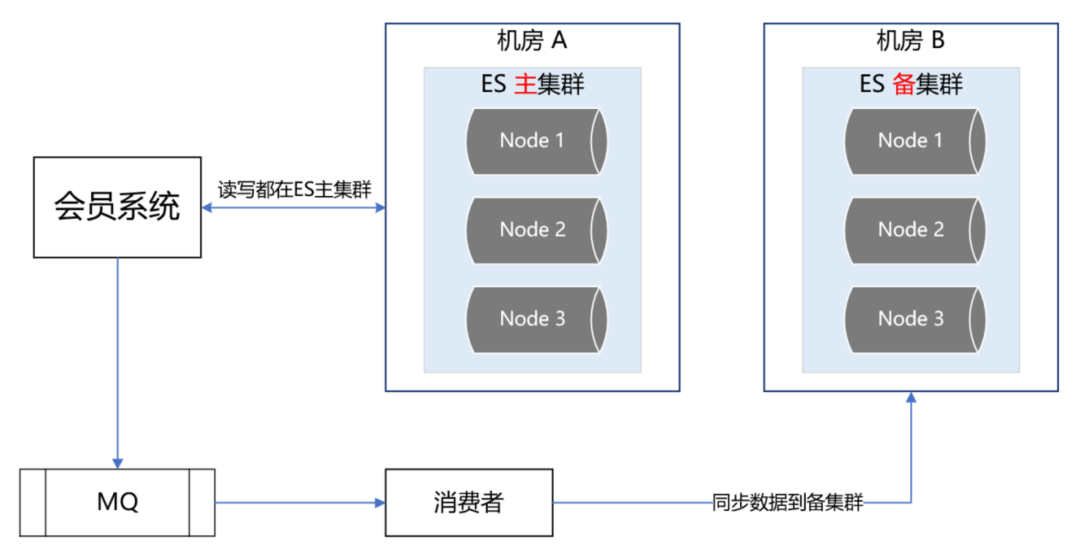
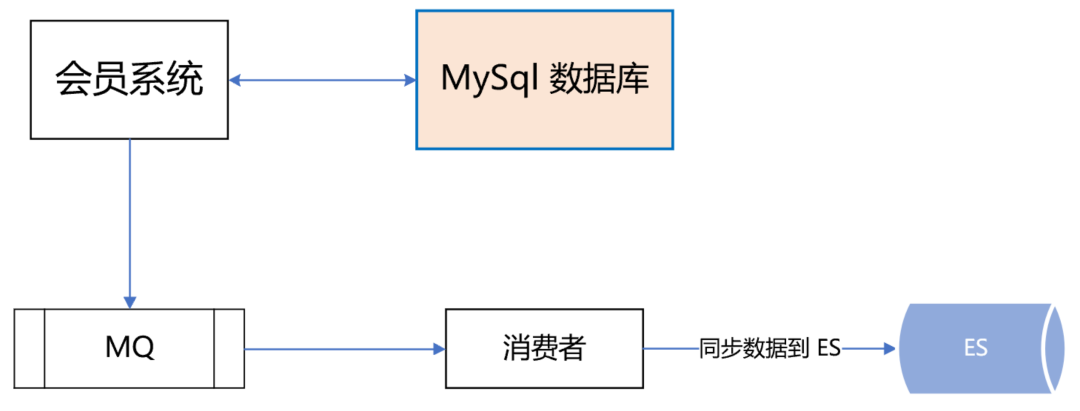
我们有两个机房,分别是机房 A 和机房 B。我们把 ES 主集群部署在机房 A,把 ES 备集群部署在机房 B。会员系统的读写都在 ES 主集群,通过 MQ 将数据同步到 ES 备集群。
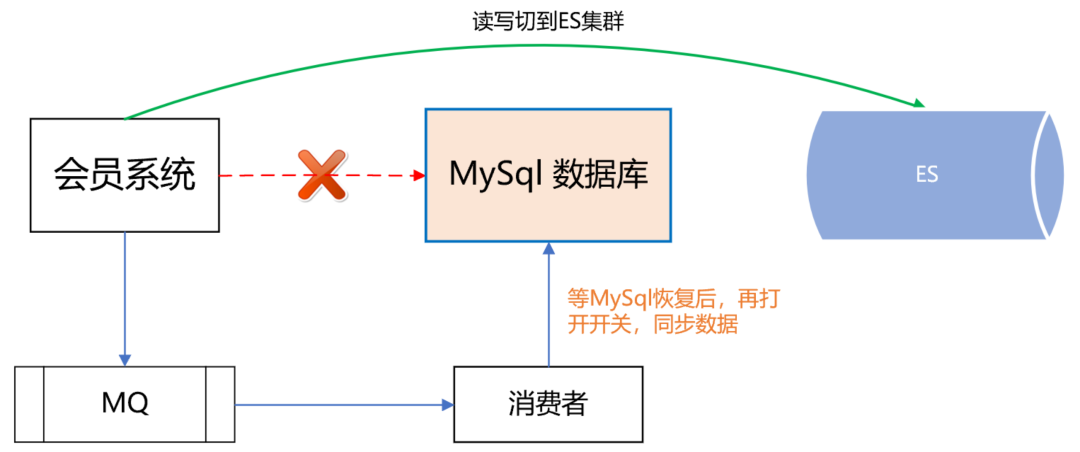
此时,如果 ES 主集群崩了,通过统一配置,将会员系统的读写切到机房 B 的 ES 备集群上,这样即使 ES 主集群挂了,也能在很短的时间内实现故障转移,确保会员系统的稳定运行。
最后,等 ES 主集群故障恢复后,打开开关,将故障期间的数据同步到 ES 主集群,等数据同步一致后,再将会员系统的读写切到 ES 主集群。 | ES 流量隔离三集群架构
双中心 ES 主备集群做到这一步,感觉应该没啥大问题了,但去年的一次恐怖流量冲击让我们改变了想法。
那是一个节假日,某个业务上线了一个营销活动,在用户的一次请求中,循环 10 多次调用了会员系统,导致会员系统的 tps 暴涨,差点把 ES 集群打爆。
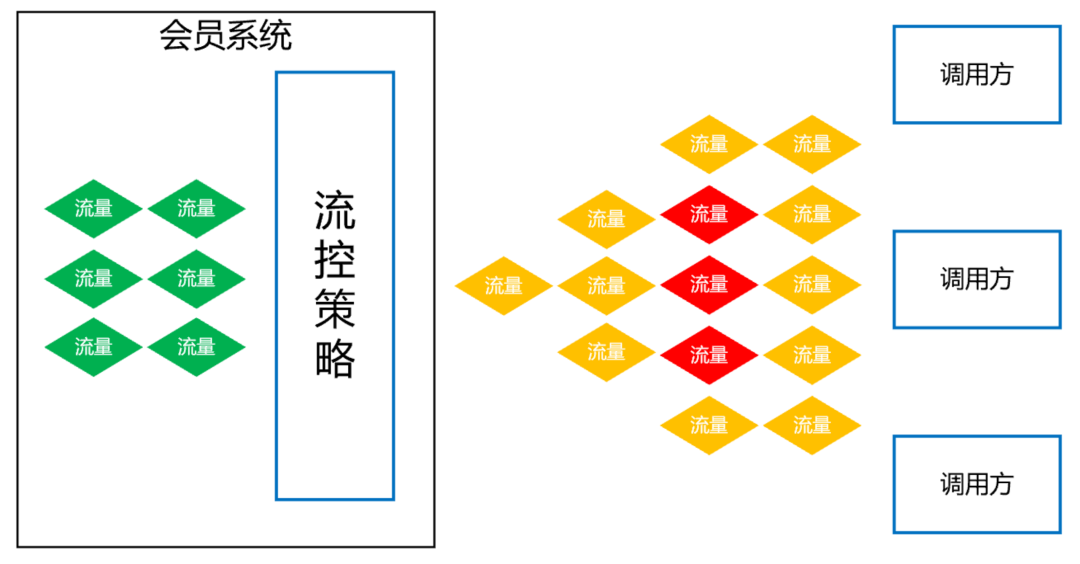
这件事让我们后怕不已,它让我们意识到,一定要对调用方进行优先级分类,实施更精细的隔离、熔断、降级、限流策略。
首先,我们梳理了所有调用方,分出两大类请求类型:
第一类是跟用户的下单主流程密切相关的请求,这类请求非常重要,应该高优先级保障。
第二类是营销活动相关的,这类请求有个特点,他们的请求量很大,tps 很高,但不影响下单主流程。
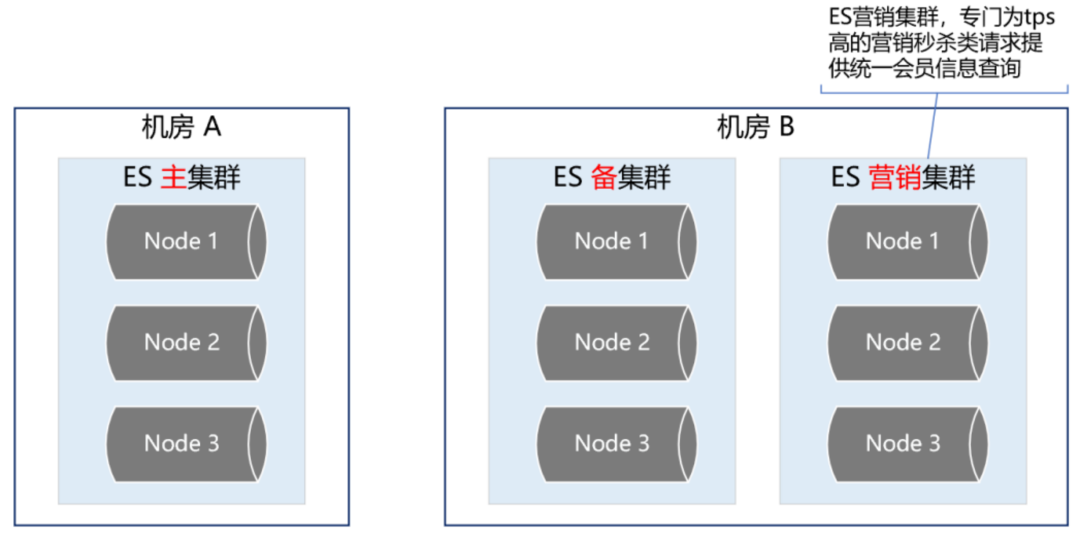
基于此,我们又构建了一个 ES 集群,专门用来应对高 tps 的营销秒杀类请求,这样就跟 ES 主集群隔离开来,不会因为某个营销活动的流量冲击而影响用户的下单主流程。
如下图所示: | ES 集群深度优化提升
讲完了 ES 的双中心主备集群高可用架构,接下来我们深入讲解一下 ES 主集群的优化工作。
有一段时间,我们特别痛苦,就是每到饭点,ES 集群就开始报警,搞得每次吃饭都心慌慌的,生怕 ES 集群一个扛不住,就全公司炸锅了。
那为什么一到饭点就报警呢?因为流量比较大, 导致 ES 线程数飙高,cpu 直往上窜,查询耗时增加,并传导给所有调用方,导致更大范围的延时。那么如何解决这个问题呢?
通过深入 ES 集群,我们发现了以下几个问题:
ES 负载不合理,热点问题严重。ES 主集群一共有几十个节点,有的节点上部署的 shard 数偏多,有的节点部署的 shard 数很少,导致某些服务器的负载很高,每到流量高峰期,就经常预警。
ES 线程池的大小设置得太高,导致 cpu 飙高。我们知道,设置 ES 的 threadpool,一般将线程数设置为服务器的 cpu 核数,即使 ES 的查询压力很大,需要增加线程数,那最好也不要超过“cpu core * 3 / 2 + 1”。如果设置的线程数过多,会导致 cpu 在多个线程上下文之间频繁来回切换,浪费大量 cpu 资源。