- pip install scrapy
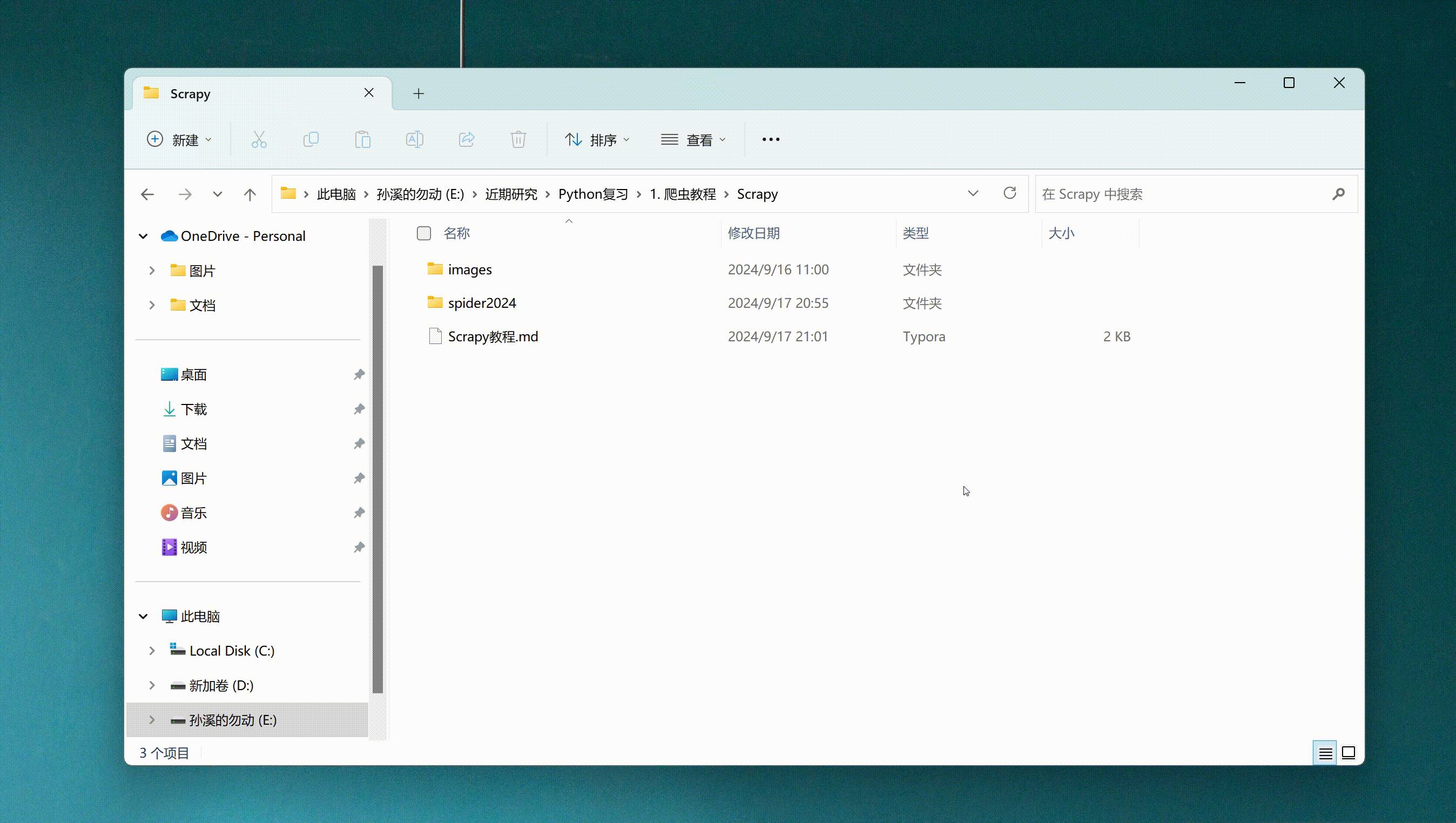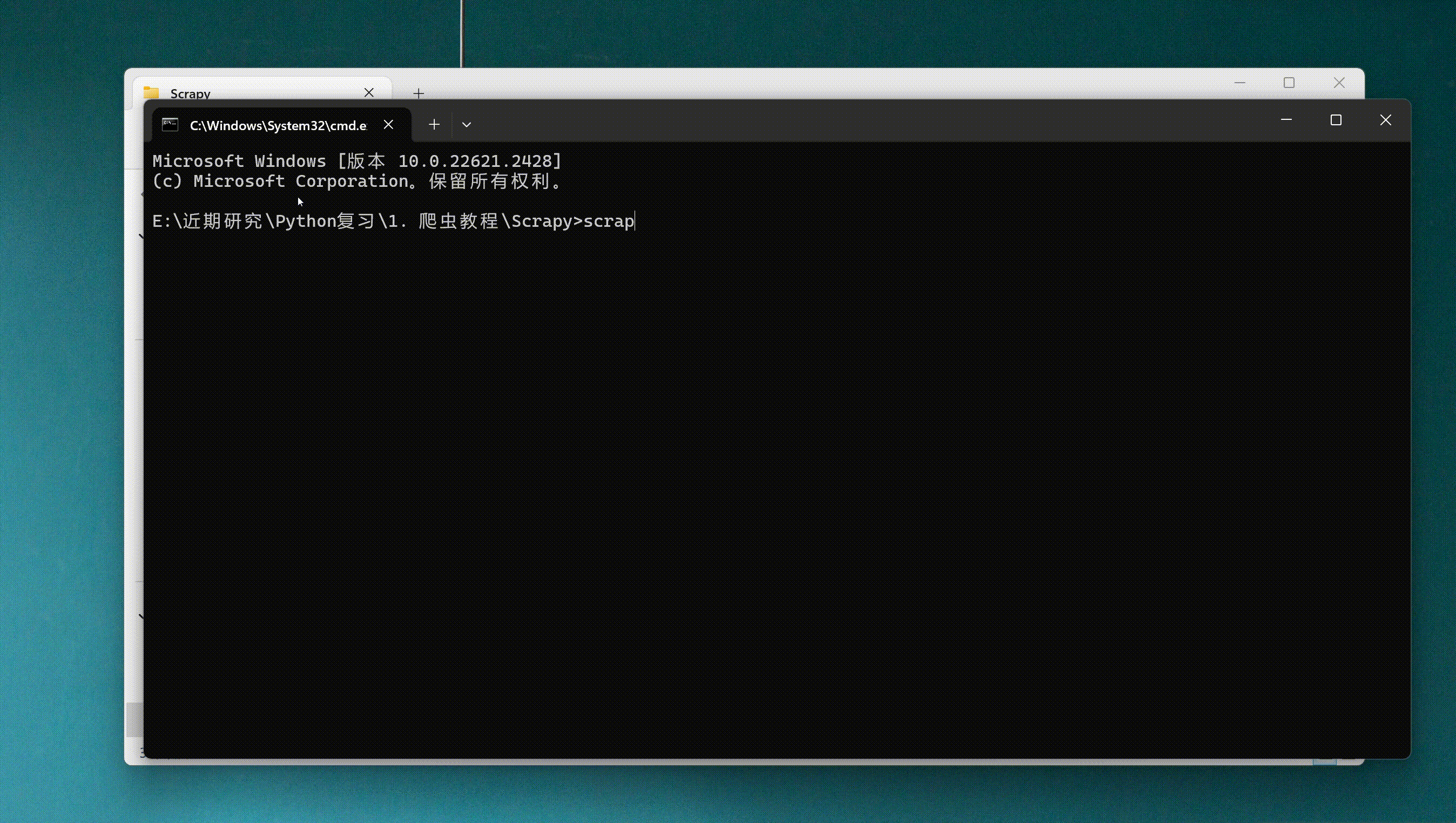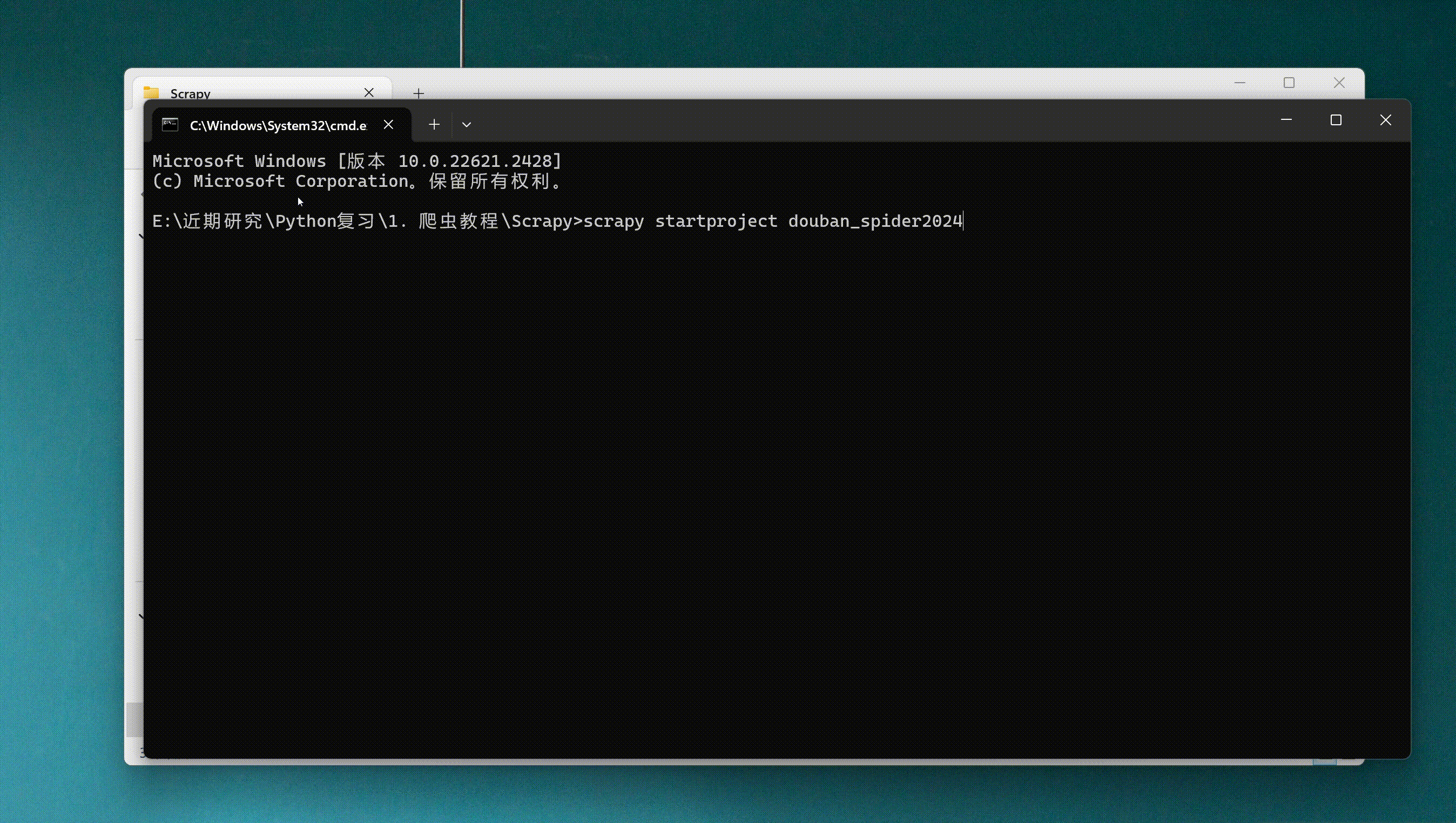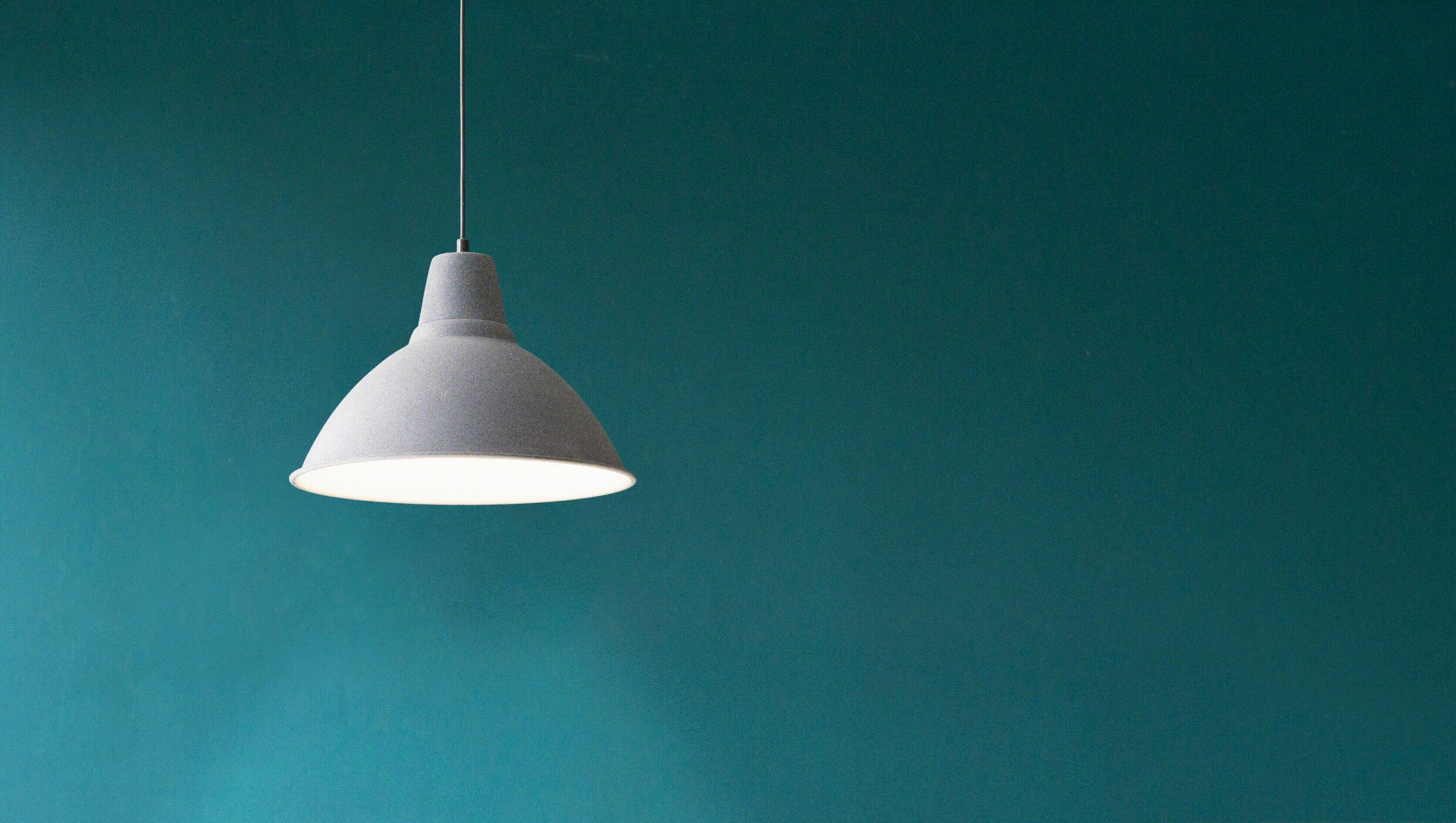
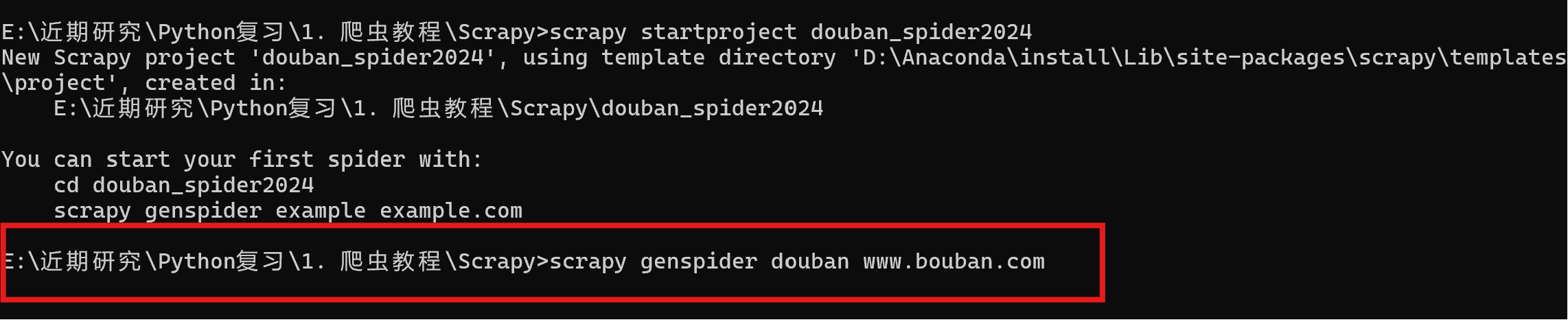
通过cmd进入命令窗口,执行命令scrapy startproject xxxx (xxxx为scrapy项目名),创建scrapy项目。
- scrapy startproject douban_spider2024
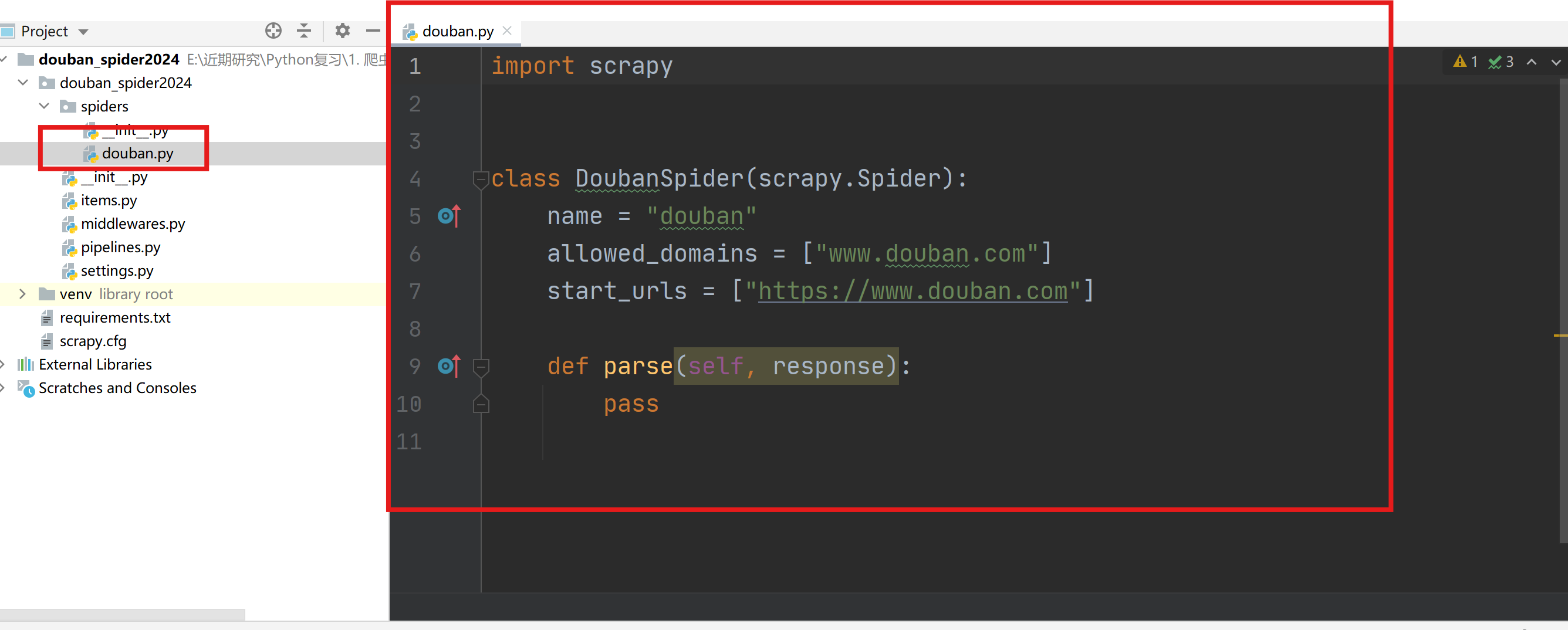
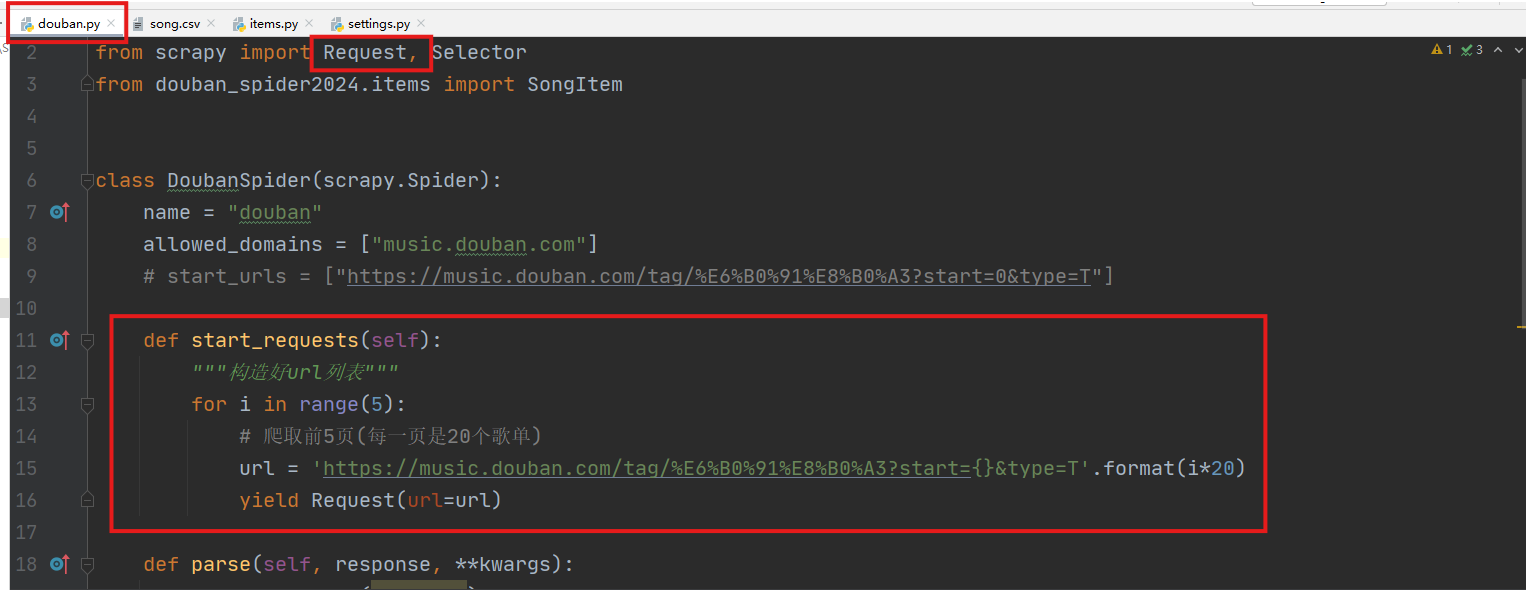
执行scrapy genspider xxx(爬虫名称) xxx(网址)创建爬虫项目。
- scrapy genspider douban www.bouban.com

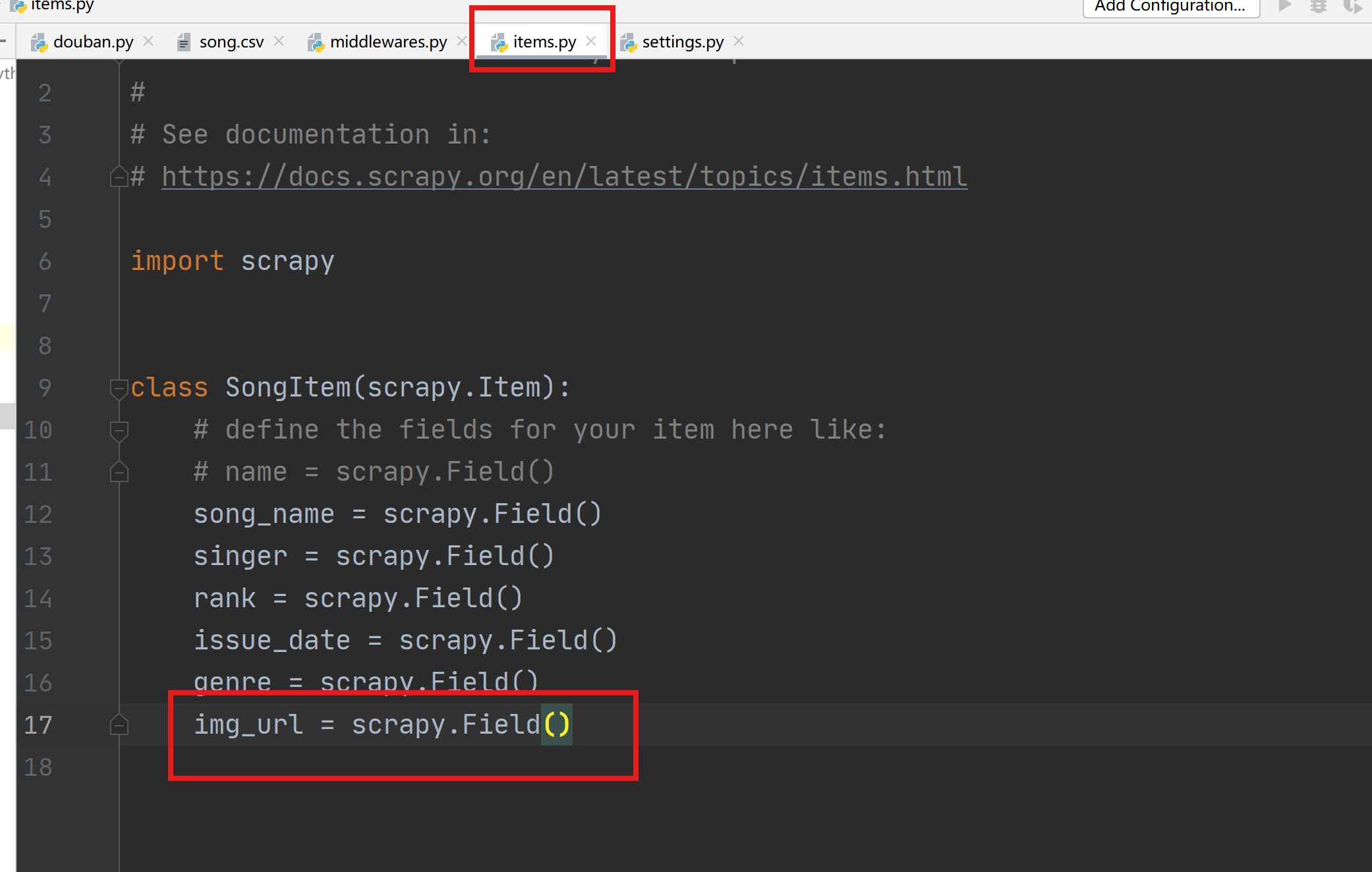
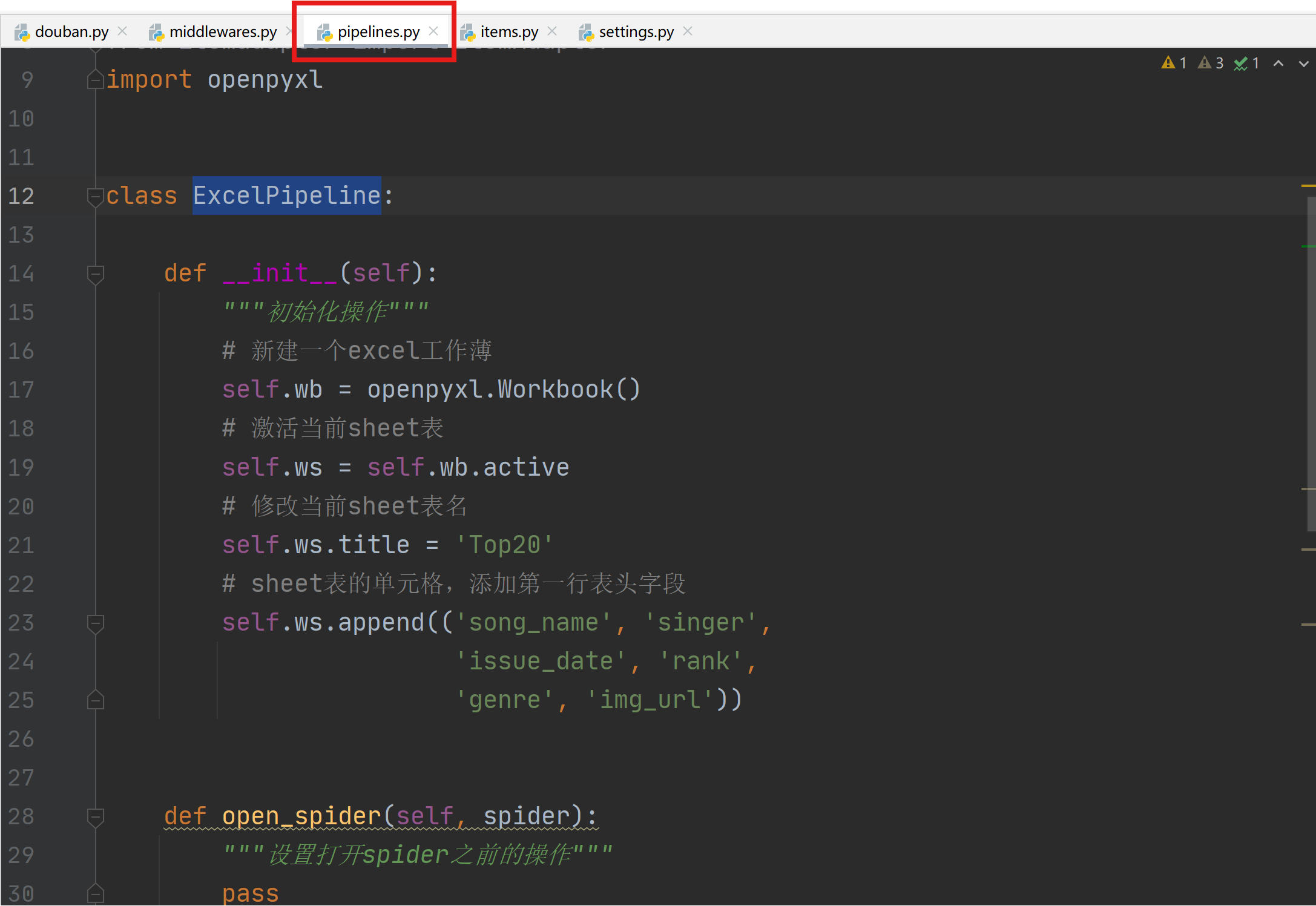
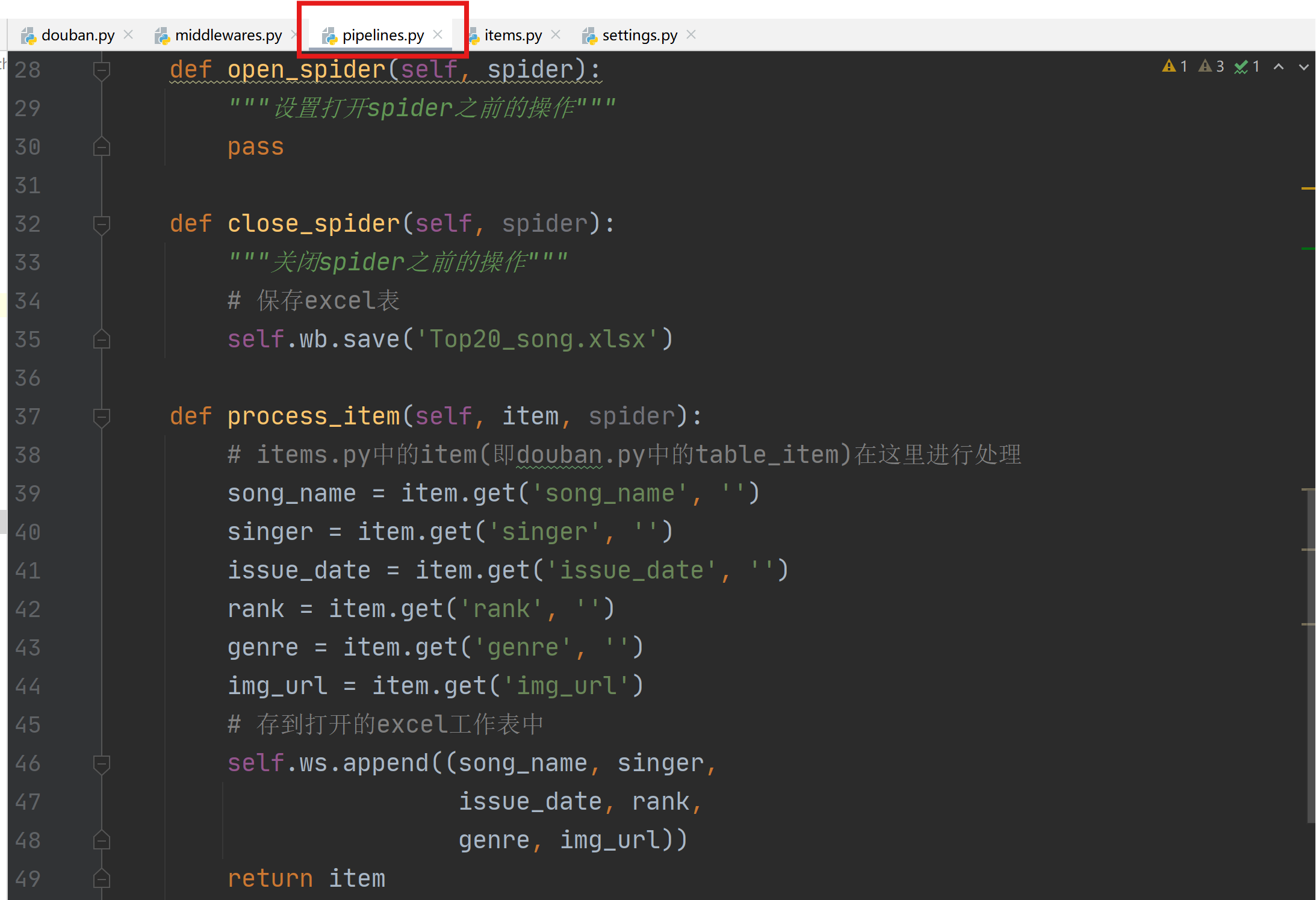
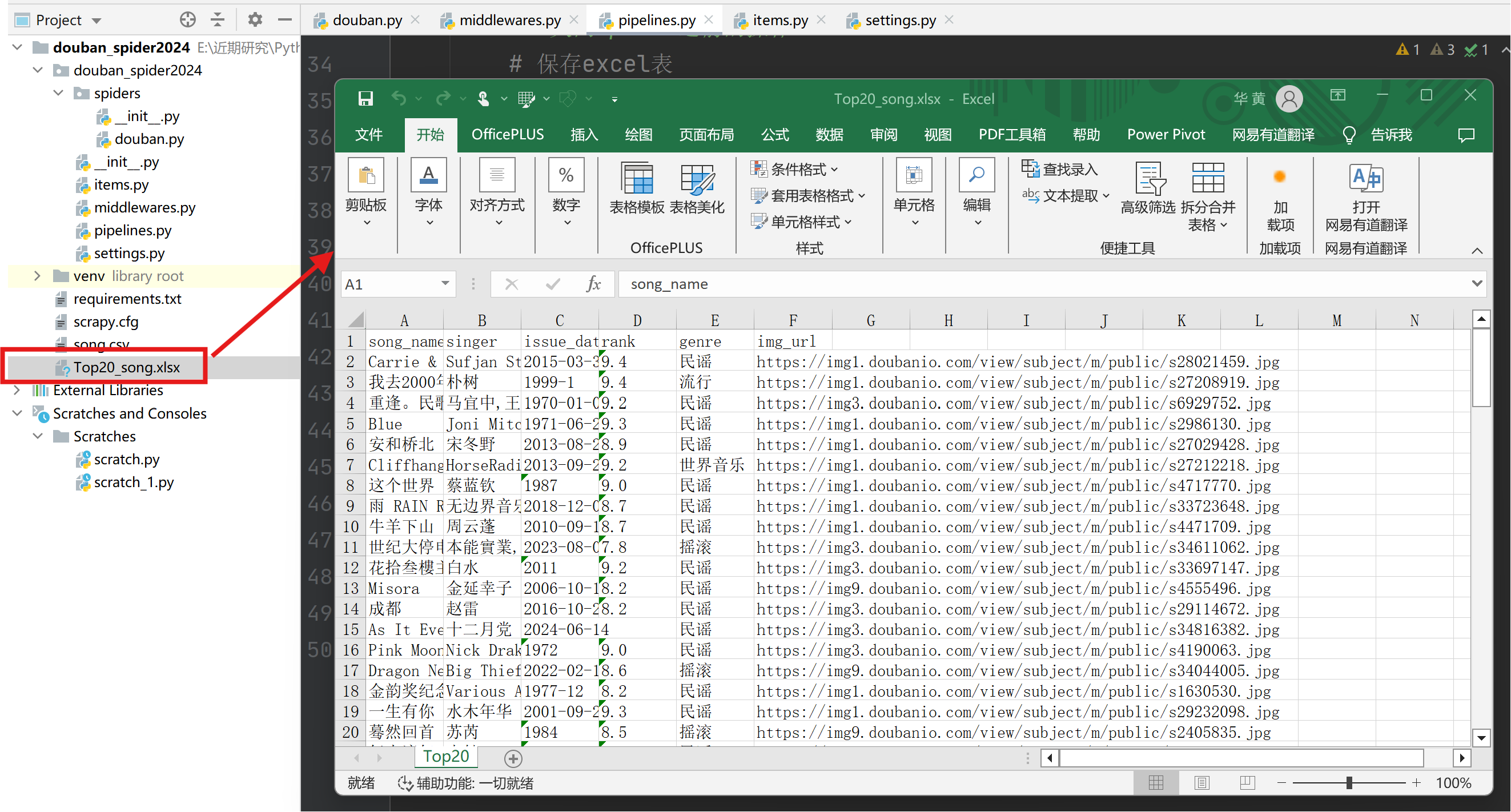
| 欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |