NLU组件也是一个可细分pipeline结构,过程是Tokenize->Featurize->NER Extract->Intent Classify。
例如,下面句子:
"I am looking for a Mexican restaurant in the center of town"
返回结构化数据:
{ "intent": "search_restaurant","entities": { "cuisine" : "Mexican", "location" : "center" }}
Rasa_NLU_Chi 作为 Rasa_NLU 的一个 fork 版本,加入了jieba 作为中文的 tokenizer,实现了中文支持。
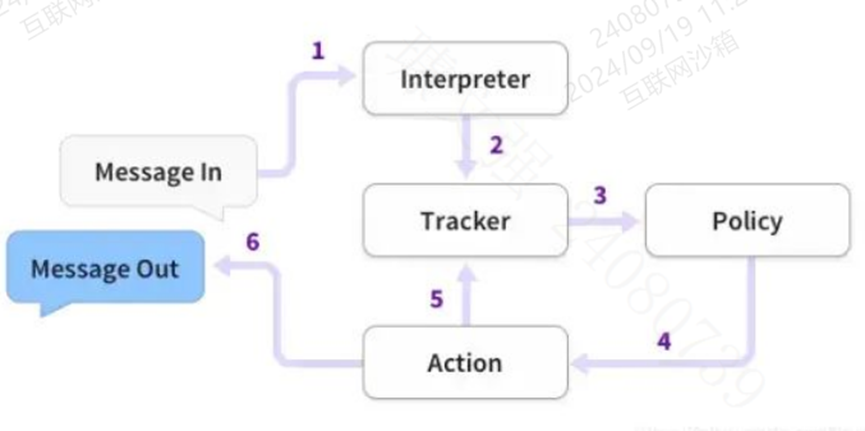
Rasa Core是一个对话管理平台,用于举行对话和决定下一步做什么。Rasa core是Rasa框架提供的对话管理模块,它雷同于谈天机器人的大脑,重要的使命是维护更新对话状态和动作选择,然后对用户的输入作出响应。所谓对话状态是一种机器能够处理的对谈天数据的表征,对话状态中包含所有大概会影响下一步决定的信息,如自然语言理解模块的输出、用户的特性等;所谓动作选择,是指基于当前的对话状态,选择接下来符合的动作,例如向用户追问需增补的信息、实行用户要求的动作等。
RASA在处理对话时,团体流程是pipeline结构,自然语言理解(NLU)、对话状态追踪(DST)以及对话策略学习(DPL)一系列流程处理下来,再判断实行下一个动作。利用Rasa构建的助手响应消息的根本步骤:
7、摆设对话式 AI 助手
要将你的对话式 AI 助手摆设到生产环境,你可以利用 Rasa 的 REST API。首先,在endpoints.yml文件中配置端点:
action_endpoint:
url: "http://localhost:5055/webhook"
model:
url: "http://localhost:5005/model"
token: "your-token"
tracker_store:
type: "sql"
dialect: "sqlite"
db: "rasa.db"
复制代码
然后,利用以下命令启动 Rasa 服务器:
rasa run
复制代码
现在你的对话式 AI 助手已经摆设到生产环境,可以通过 REST API 与外部服务进行交互。 作者简介: 读研期间发表6篇SCI数据发掘相关论文,现在某研究院从事数据算法相关科研工作,联合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列根本知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小同伴可以关注底部公众号添加作者微信。