qidao123.com技术社区-IT企服评测·应用市场
标题:
中科院提出GPT-4o及时语音交互的开源对手:Llama-Omni
[打印本页]
作者:
拉不拉稀肚拉稀
时间:
2024-10-7 06:08
标题:
中科院提出GPT-4o及时语音交互的开源对手:Llama-Omni
论文
:LLaMA-Omni: Seamless Speech Interaction with Large Language Models
地址
:https://arxiv.org/pdf/2409.06666
研究背景
研究问题
:这篇文章要办理的问题是如何基于开源的大型语言模型(LLMs)构建低延迟高质量的语音交互模型。传统的基于文本的交互方式限制了LLMs在非抱负文本输入输出场景中的应用,而及时语音交互可以显著提升用户体验。
研究难点
:该问题的研究难点包括:如何消除语音转录的步骤,直接重新语音指令生成文本和语音相应;如安在包管极低延迟的同时,生成高质量的内容和风格相应。
相关工作
:该问题的研究相关工作有:SpeechGPT和AudioPaLM等模型通过向LLMs的词汇表中添加语音标记并进行预练习来实现语音输入输出,但这些方法必要大量数据和盘算资源。别的一些模型则在LLMs前添加语音编码器并进行微调,这些模型主要关注语音理解而非生成。
研究方法
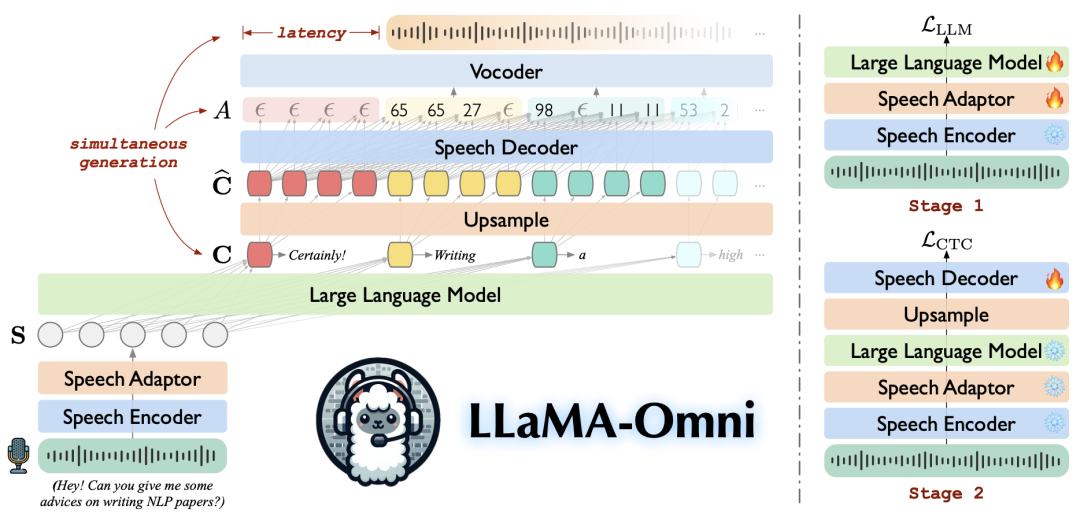
这篇论文提出了LLaMA-Omni模型,用于办理低延迟高质量语音交互的问题。详细来说:
语音编码器
:利用Whisper-large-v32的编码器作为语音编码器,提取语音指令的表现。公式如下: 其中,是长度为的语音表现序列。
语音适配器
:语音适配器将语音表现序列下采样,并通过两层感知器将其转换为适合LLM输入的表现。公式如下:
大型语言模型(LLM)
:利用Llama-3.1-8B-Instruct模型,将语音表现序列填充到对应的 位置,并直接基于语音指令生成文本相应。损失函数为:
语音解码器
:语音解码器利用非自回归的Transformer层,通过连接时序分类(CTC)推测对应的离散单元序列。公式如下: 其中,和是线性层的权重和偏置,是空白标记。
实行设计
数据集构建
:构建了一个名为InstructS2S-200K的数据集,包含200K条语音指令及其对应的语音相应。数据集通过重写现有文本指令数据并进行语音合成得到。
模型设置
:利用Whisper-large-v3的编码器和Llama-3.1-8B-Instruct模型,语音适配器进行5倍下采样,语音解码器包含2层Transformer层。
练习过程
:接纳两阶段练习计谋。第一阶段练习语音适配器和LLM,第二阶段练习语音解码器。整个练习过程在4个GPU上耗时约65小时。
结果与分析
ChatGPT评分
:在S2TIF和S2SIF任务上,LLaMA-Omni在内容和风格评分上均优于之前的模型。S2TIF任务的风格评分为3.81,S2SIF任务的风格评分为3.12。
语音-文本对齐
:LLaMA-Omni在ASR-WER和ASR-CER评分上均最低,分别为7.59和41.40,表明生成的语音和文本相应的对齐度较高。
语音质量
:利用UTMOS评分评估生成的语音质量,结果表现随着单位块巨细的增加,语音的天然度提高。
相应延迟
:当设置为10时,系统的相应延迟低至226ms,显著低于GPT-4o的平均音频延迟320ms。
解码时间
:LLaMA-Omni在S2TIF和S2SIF任务上的平均解码时间分别为1.49秒和1.92秒,显著低于其他模型。
总体结论
本文提出的LLaMA-Omni模型实现了低延迟高质量的语音交互,能够在极低的延迟下生成高质量的文本和语音相应。实行结果表明,LLaMA-Omni在多个评价指标上均优于现有的语音语言模型,并且练习成本低,便于基于最新的LLMs进行快速开辟。未来工作将进一步增强生成语音相应的表达能力和及时交互能力。
本文由AI辅助人工完成。
备注:
昵称-学校/公司-方向/
会议(eg.ACL)
,进入技能/投稿群
id:DLNLPer,记得备注呦
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4