INNER JOIN 关键字在表中存在至少一个匹配时返回行。
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
或:
SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column_name=table2.column_name; 参数阐明:
columns:要显示的列名。
table1:表1的名称。
table2:表2的名称。
column_name:表中用于连接的列名。
LEFT JOIN 关键字
LEFT JOIN 关键字从左表(table1)返回全部的行,纵然右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
或:
SELECT column_name(s)
FROM table1
LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name; 注释:在某些数据库中,LEFT JOIN 称为 LEFT OUTER JOIN。
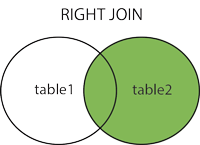
RIGHT JOIN 关键字
RIGHT JOIN 关键字从右表(table2)返回全部的行,纵然左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;
或:
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name; 注释:在某些数据库中,RIGHT JOIN 称为 RIGHT OUTER JOIN。
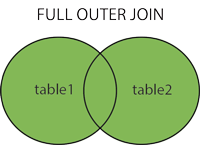
FULL OUTER JOIN 关键字
FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)此中一个表中存在匹配,则返回行.
FULL OUTER JOIN 关键字团结了 LEFT JOIN 和 RIGHT JOIN 的结果。
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
UNION 操纵符
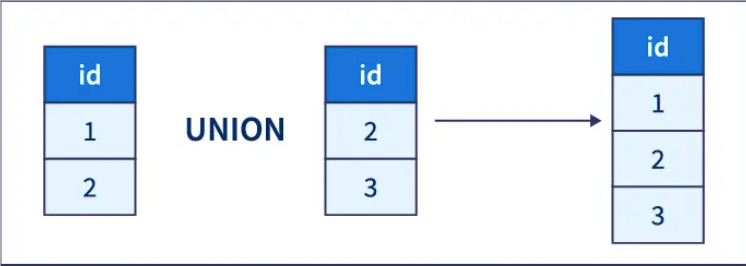
SQL UNION 操纵符合并两个或多个 SELECT 语句的结果。
UNION 操纵符用于合并两个或多个 SELECT 语句的结果集。它可以从多个表中选择数据,并将结果集组合成一个结果集。利用 UNION 时,每个 SELECT 语句必须具有相同数量的列,且对应列的数据类型必须相似。
UNION 语法
SELECT column1, column2, ...
FROM table1
UNION
SELECT column1, column2, ...
FROM table2;
复制代码
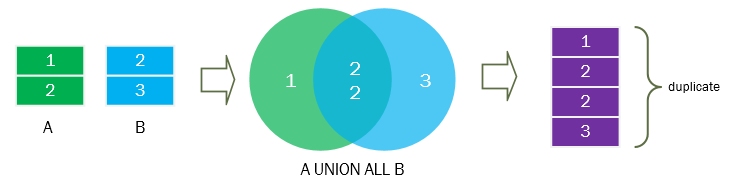
UNION 操纵符默认会去除重复的记录,如果需要保留全部重复记录,可以利用 UNION ALL 操纵符。
UNION ALL 语法
SELECT column1, column2, ...
FROM table1
UNION ALL
SELECT column1, column2, ...
FROM table2;
注释:UNION 结果会合的列名总是即是 UNION 中第一个 SELECT 语句中的列名
SELECT INTO 语句
SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中。 注意:
MySQL 数据库不支持 SELECT ... INTO 语句,但支持 INSERT INTO ... SELECT 。
固然你可以利用以下语句来拷贝表结构及数据:
CREATE TABLE 新表
AS
SELECT * FROM 旧表
复制代码
表结构:
SELECT INTO 会创建一个新表,并且新表的结构将基于选择的列和数据类型。
如果新表已经存在,SELECT INTO 语句将失败。在这种情况下,可以利用 INSERT INTO ... SELECT 语句。
数据库支持:
SELECT INTO 语句在 SQL Server 中非常常用,但在 MySQL 和 PostgreSQL 中通常利用 CREATE TABLE ... AS SELECT 语句。
INSERT INTO SELECT 语句
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响。
CREATE TABLE 语句
PRIMARY KEY - NOT NULL 和 UNIQUE 的团结。确保某列(或两个列多个列的团结)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。
DEFAULT - 规定没有给列赋值时的默认值。
INDEX - 用于快速访问数据库表中的数据。
1. NOT NULL
确保列不能有 NULL 值。
NOT NULL 束缚逼迫字段始终包罗值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录
例子
CREATE TABLE Students (
StudentID INT NOT NULL,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50),
Age INT
);
2. UNIQUE
实例
CREATE TABLE Employees (
EmployeeID INT NOT NULL UNIQUE,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50),
Email VARCHAR(100) UNIQUE
);
3. PRIMARY KEY
唯一标识表中的每一行记录。PRIMARY KEY 束缚是 NOT NULL 和 UNIQUE 的团结。 实例
CREATE TABLE Orders (
OrderID INT NOT NULL PRIMARY KEY,
OrderNumber INT NOT NULL,
OrderDate DATE NOT NULL
);
4. FOREIGN KEY
确保一个表中的值匹配另一个表中的值,从而建立两表之间的关系。 实例
CREATE TABLE Orders (
OrderID INT NOT NULL PRIMARY KEY,
OrderNumber INT NOT NULL,
CustomerID INT,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
5. CHECK
确保列中的值满足特定的条件。
实例
CREATE TABLE Products (
ProductID INT NOT NULL PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Price DECIMAL(10, 2) CHECK (Price >= 0)
);
6. DEFAULT
为列设置默认值。
实例
CREATE TABLE Customers (
CustomerID INT NOT NULL PRIMARY KEY,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50),
JoinDate DATE DEFAULT GETDATE()
);
7. INDEX
用于快速访问数据库表中的数据。
CREATE INDEX idx_lastname ON Employees (LastName);
复制代码
例子
CREATE TABLE Students (
StudentID INT NOT NULL PRIMARY KEY,
LastName VARCHAR(50) NOT NULL,
FirstName VARCHAR(50) NOT NULL,
Age INT CHECK (Age >= 18),
Email VARCHAR(100) UNIQUE,
EnrollmentDate DATE DEFAULT GETDATE()
);
通过这些束缚,数据库管理体系可以或许确保数据的同等性、完整性和准确性。
PRIMARY KEY 束缚
DEFAULT 束缚用于向列中插入默认值。
如果没有规定其他的值,那么会将默认值添加到全部的新记录。
CREATE INDEX 语法
在表上创建一个简单的索引。允许利用重复的值:
CREATE INDEX index_name
ON table_name (column_name)
CREATE UNIQUE INDEX
在表上创建一个唯一的索引。不允许利用重复的值:唯一的索引意味着两个行不能拥有相同的索引值。Creates a unique index on a table. Duplicate values are not allowed:
CREATE UNIQUE INDEX index_name
ON table_name (column_name) 注释:用于创建索引的语法在差别的数据库中不一样。因此,检查您的数据库中创建索引的语法。
DROP INDEX 语句
索引是一种优化数据库查询性能的结构,但有时间可能需要删除某个索引,比方当索引不再需要或需要替换为新的索引时。
DROP INDEX 语句用于删除表中的索引。
DROP INDEX [IF EXISTS] index_name
ON TABLE_NAME; 参数阐明:
DROP INDEX:表示要删除索引的操纵。
IF EXISTS:是一个可选的子句,用于检查索引是否存在。如果存在,就执行删除操纵;如果不存在,不会报错。
index_name:要删除的索引的名称。
ON table_name:指定包罗要删除索引的表的名称。
DROP TABLE 语句
DROP TABLE 语句用于删除表。
删除表将同时删除表的结构以及存储在此中的全部数据。因此,在执行DROP TABLE语句之前,请确保您真的渴望永世删除表及其全部数据,因为此操纵是不可逆的。
DROP TABLE [IF EXISTS] TABLE_NAME; 参数阐明:
DROP TABLE:表示删除表的操纵。
IF EXISTS:是一个可选的子句,用于检查表是否存在。如果存在,执行删除操纵;如果不存在,不会报错。
table_name:要删除的表的名称。
DATABASE 语句
DROP DATABASE 语句用于删除数据库,包罗此中的全部表、视图、存储过程等数据库对象。
DROP DATABASE 是一个非常强大和危险的操纵,因为它会永世删除整个数据库及其全部相干数据,因此在执行之前务须要慎重考虑并确保你真的渴望执行此操纵。
DROP DATABASE [IF EXISTS] database_name;
TRUNCATE TABLE 语句
TRUNCATE TABLE语句用于快速删除表中的全部数据,但保留表的结构(列、束缚等)
ALTER TABLE 语句
ALTER TABLE 语句用于在已有的表中添加、删除或修改列。
如需在表中添加列,请利用下面的语法:
ALTER TABLE table_name
ADD column_name datatype
如需删除表中的列,请利用下面的语法(请注意,某些数据库体系不允许这种在数据库表中删除列的方式):
ALTER TABLE table_name
DROP COLUMN column_name
AUTO INCREMENT 字段