ToB企服应用市场:ToB评测及商务社交产业平台
标题:
Hive 整合 Spark 全教程 (Hive on Spark)
[打印本页]
作者:
石小疯
时间:
2024-10-18 07:36
标题:
Hive 整合 Spark 全教程 (Hive on Spark)
[luanhao@Bigdata00
hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
复制代码
(2)打开/etc/profile文件
[luanhao@Bigdata00
hadoop-3.1.3]$ sudo vim /etc/profile
在profile文件末尾添加JDK路径:(shitf+g)
#HADOOP\_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP\_HOME/bin
export PATH=$PATH:$HADOOP\_HOME/sbin
复制代码
(3)刷新并查看是否设置成功
[luanhao@Bigdata00
module]$ source /etc/profile
[luanhao@Bigdata00
module]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
复制代码
设置集群
1)焦点设置文件
设置core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Bigdata00
:9820</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为luanhao -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>luanhao</value>
</property>
<!-- 配置该luanhao(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.luanhao.hosts</name>
<value>*</value>
</property>
<!-- 配置该luanhao(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.luanhao.groups</name>
<value>*</value>
</property>
<!-- 配置该luanhao(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.luanhao.groups</name>
<value>*</value>
</property>
</configuration>
复制代码
2)HDFS设置文件
设置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>Bigdata00
:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Bigdata00
:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
复制代码
3)YARN设置文件
设置yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Bigdata00
</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
复制代码
4)MapReduce设置文件
设置mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
复制代码
5)设置workers
Bigdata00
复制代码
6)设置hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212
复制代码
设置历史服务器
为了查看程序的历史运行环境,须要设置一下历史服务器。具体设置步骤如下:
设置mapred-site.xml
<!-- 历史服务器端地点 --><property> <name>mapreduce.jobhistory.address</name> <value>Bigdata00
:10020</value></property><!-- 历史服务器web端地点 --><property> <name>mapreduce.jobhistory.webapp.address</name> <value>Bigdata00
:19888</value></property>
复制代码
设置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS体系上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
留意:开启日志聚集功能,须要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
设置yarn-site.xml
<!-- 开启日志聚集功能 --><property> <name>yarn.log-aggregation-enable</name> <value>true</value></property><!-- 设置日志聚集服务器地点 --><property> <name>yarn.log.server.url</name> <value>http://Bigdata00
:19888/jobhistory/logs</value></property><!-- 设置日志保存时间为7天 --><property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value></property>
复制代码
启动集群
(1)如果集群是第一次启动,须要在Bigdata00
节点格式化NameNode(留意格式化之前,一定要先制止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[luanhao@Bigdata00
hadoop-3.1.3]$ bin/hdfs namenode -format
复制代码
(2)启动HDFS
[luanhao@Bigdata00
hadoop-3.1.3]$ sbin/start-dfs.sh
复制代码
(3)在设置了ResourceManager的节点启动YARN
[luanhao@Bigdata00
hadoop-3.1.3]$ sbin/start-yarn.sh
复制代码
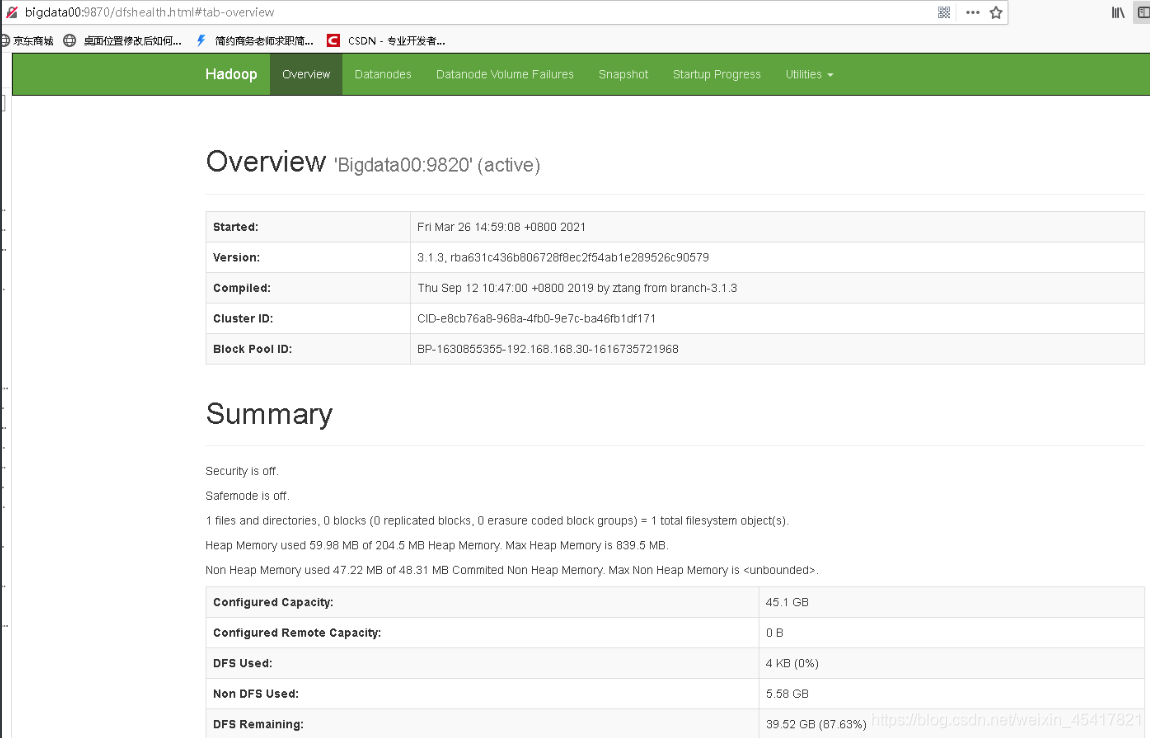
(4)Web端查看HDFS的Web页面:http://bigdata00:9870
(5)Web端查看SecondaryNameNode :http://bigdata00:9868/status.html (单机模式下面什么都没有)
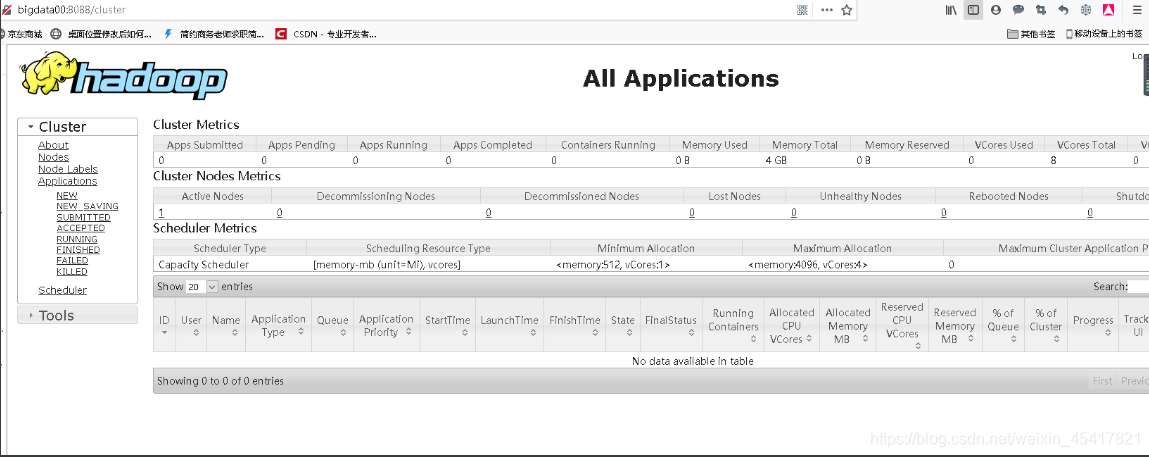
(6)Web端查看ResourceManager :http://bigdata00:8088/cluster
LZO压缩设置
1)将编译好后的 hadoop-lzo-0.4.20.jar 放入 hadoop-3.1.3/share/hadoop/common/
[luanhao@Bigdata00
common]$ pwd/opt/module/hadoop-3.1.3/share/hadoop/common[luanhao@Bigdata00
common]$ lshadoop-lzo-0.4.20.jar
复制代码
2)core-site.xml 增长设置支持 LZO 压缩
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>
复制代码
Hadoop 3.x 端标语 总结
Hadoop 3.x后,应用的端口有所调解,如下:
分类应用Haddop 2.xHaddop 3.xNNPortsNamenode80209820NNPortsNN HTTP UI500709870NNPortsNN HTTPS UI504709871SNN portsSNN HTTP500919869SNN portsSNN HTTP UI500909868DN portsDN IPC500209867DN portsDN500109866DN portsDN HTTP UI500759864DN portsNamenode504759865YARN portsYARN UI80888088
MySQL预备
1)卸载自带的 Mysql-libs(如果之前安装过 mysql,要全都卸载掉)
[luanhao@Bigdata00
software]$ rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
复制代码
2)安装
mysql
依靠
[luanhao@Bigdata00
software]$ sudo rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm[luanhao@Bigdata00
software]$ sudo rpm -ivh 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm[luanhao@Bigdata00
software]$ sudo rpm -ivh 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
复制代码
3)安装
mysql-client
[luanhao@Bigdata00
software]$ sudo rpm -ivh 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
复制代码
4)安装
mysql-server
[luanhao@Bigdata00
software]$ sudo rpm -ivh 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
复制代码
5)启动
mysql
[luanhao@Bigdata00
software]$ sudo systemctl start mysqld
复制代码
6)查看
mysql
密码
[luanhao@Bigdata00
software]$ sudo cat /var/log/mysqld.log | grep password
复制代码
设置只要是 root 用户+密码,在任何主机上都能登录 MySQL 数据库。
7)用刚刚查到的密码进入
mysql
(如果报错,给密码加单引号)
[luanhao@Bigdata00
software]$ mysql -uroot -p 'password'
复制代码
8)设置复杂密码(由于
mysql
密码计谋,此密码必须足够复杂
)
mysql> set password=password("Qs23=zs32");
复制代码
9)更改
mysql
密码计谋
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
复制代码
10)设置简单好记的密码
mysql> set password=password("000000");
复制代码
11)进入
msyql
库
mysql> use mysql
复制代码
12
)查询
user
表
mysql> select user, host from user;
复制代码
13)修改
user
表,把
Host
表内容修改为
%
mysql> update user set host="%" where user="root";
复制代码
14)刷新
mysql> flush privileges;
复制代码
15)退出
mysql> quit;
复制代码
Hive 预备
1
)把
apache-hive-3.1.2-bin.tar.gz
上传到
linux
的
/opt/software
目录下
2
)解压
apache-hive-3.1.2-bin.tar.gz
到
/opt/module目录下面
[luanhao@Bigdata00
software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
复制代码
3
)修改
apache-hive-3.1.2-bin.tar.gz
的名称为
hive
[luanhao@Bigdata00
software]$ mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
复制代码
4
)修改/etc/profile,添加环境变量
[luanhao@Bigdata00
software]$ sudo vim /etc/profile添加内容#HIVE\_HOMEexport HIVE_HOME=/opt/module/hiveexport PATH=$PATH:$HIVE\_HOME/bin
复制代码
重启 Xshell 对话框或者 source 一下 /etc/profile 文件,使环境变量生效
[luanhao@Bigdata00
software]$ source /etc/profile
复制代码
5)办理日志
Jar
包辩论,进入
/opt/module/hive/lib 目录(有辩论再做)
[luanhao@Bigdata00
lib]$ mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
复制代码
Hive
元数据设置到
MySQL
拷贝驱动
将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
[luanhao@Bigdata00
lib]$ cp /opt/software/mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/
复制代码
设置
Metastore
到
MySQL
在$HIVE_HOME/conf 目录下新建 hive-site.xml 文件
[luanhao@Bigdata00
conf]$ vim hive-site.xml
复制代码
添加如下内容
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://Bigdata00
:3306/metastore?useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>000000</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>Bigdata00
</value> </property> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property></configuration>
复制代码
启动
Hive
初始化元数据库
1
)登岸
MySQL
[luanhao@Bigdata00
conf]$ mysql -uroot -p000000
复制代码
2
)新建
Hive
元数据库
mysql> create database metastore;mysql> quit;
复制代码
3
)初始化
Hive
元数据库
[luanhao@Bigdata00
conf]$ schematool -initSchema -dbType mysql -verbose
复制代码
启动
hive
客户端
1
)启动
Hive
客户端
[luanhao@Bigdata00
hive]$ bin/hive
复制代码
2
)查看一下数据库
hive (default)> show databases;
OK
database_name
default
复制代码
Spark 预备
(1)Spark 官网下载 jar 包地点:
http://spark.apache.org/downloads.html
(2)上传并解压解压 spark-3.0.0-bin-hadoop3.2.tgz
[luanhao@Bigdata00
software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/ [luanhao@Bigdata00
software]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
复制代码
(3)设置 SPARK_HOME 环境变量
[luanhao@Bigdata00
software]$ sudo vim /etc/profile添加如下内容# SPARK\_HOMEexport SPARK_HOME=/opt/module/sparkexport PATH=$PATH:$SPARK\_HOME/bin
复制代码
source 使其生效
[luanhao@Bigdata00
software]$ source /etc/profile
复制代码
(4)在
hive
中创建
spark
设置文件
[luanhao@Bigdata00
software]$ vim /opt/module/hive/conf/spark-defaults.conf添加如下内容(在执行使命时,会根据如下参数执行)spark.master yarnspark.eventLog.enabled truespark.eventLog.dir hdfs://Bigdata00
:8020/spark-historyspark.executor.memory 1g spark.driver.memory 1g
复制代码
在 HDFS 创建如下路径,用于存储历史日志
[luanhao@Bigdata00
software]$ hadoop fs -mkdir /spark-history
复制代码
(5)向
HDFS
上传
Spark
纯净版
jar
包
说明 1:由于 Spark3.0.0 非纯净版默认支持的是 hive2.3.7 版本,直接利用会和安装的Hive3.1.2 出现兼容性问题。以是接纳 Spark 纯净版 jar 包,不包罗 hadoop 和 hive 相关依靠,避免辩论。
说明 2:Hive 使命最终由 Spark 来执行,Spark 使命资源分配由 Yarn 来调理,该使命有大概被分配到集群的任何一个节点。以是须要将 Spark 的依靠上传到 HDFS 集群路径,如许集群中任何一个节点都能获取到。
(6)上传并解压 spark-3.0.0-bin-without-hadoop.tgz
[luanhao@Bigdata00
software]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
复制代码
(7)上传 Spark 纯净版 jar 包到 HDFS
[luanhao@Bigdata00
software]$ hadoop fs -mkdir /spark-jars[luanhao@Bigdata00
software]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
复制代码
Hive on Spark 设置
修改
hive-site.xml
文件
[luanhao@Bigdata00
~]$ vim /opt/module/hive/conf/hive-site.xml添加如下内容<!--Spark 依靠位置(留意:端标语 8020 必须和 namenode 的端标语同等)--><property> <name>spark.yarn.jars</name> <value>hdfs://Bigdata00
:8020/spark-jars/*</value></property> <!--Hive 执行引擎--><property> <name>hive.execution.engine</name> <value>spark</value></property><!--Hive 和 Spark 连接超时时间--><property> <name>hive.spark.client.connect.timeout</name> <value>10000ms</value></property>
复制代码
hadoop 3.1.3 默认 NameNode 端口是 9820
重新在hadoop 下的 core-site.xml 将 9820 修改成 8020 就可以了
core-site.xml
<!-- 指定NameNode的地址 -->
<property>
复制代码
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4