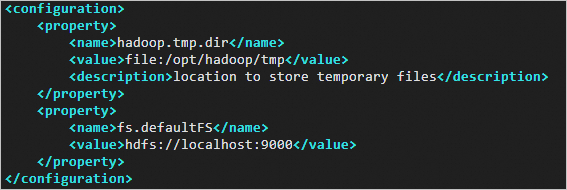
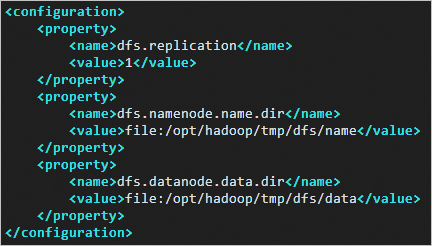
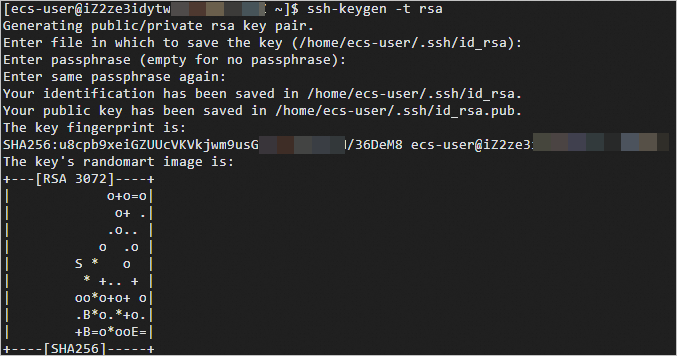
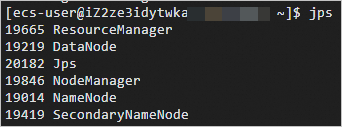
详细操作,请拜见通过密码或密钥认证登录Linux实例。
- wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
- tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
本示例中将JDK安装包重定名为java8,您可以根据需要利用其他名称。
- sudo mv java-se-8u41-ri/ /usr/java8
如果您将JDK安装包重定名为其他名称,需将以下下令中的java8更换为实际的名称。
- sudo sh -c "echo 'export JAVA_HOME=/usr/java8' >> /etc/profile"
- sudo sh -c 'echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile'
- source /etc/profile
- java -version