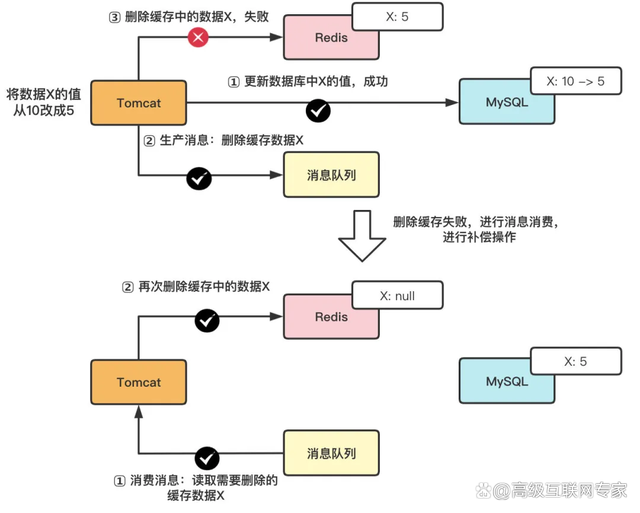
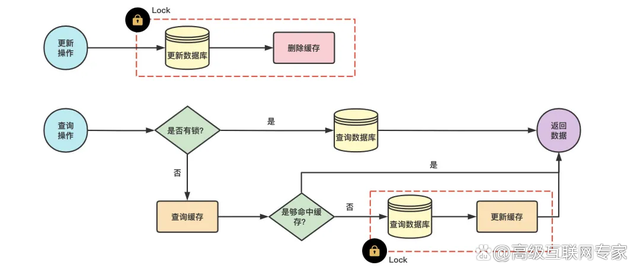
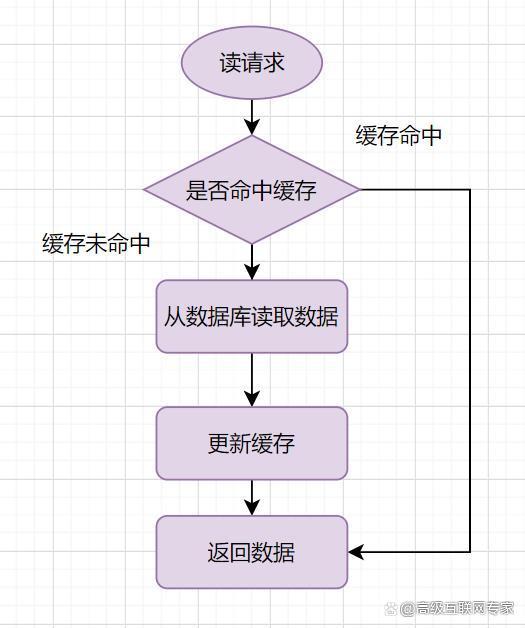
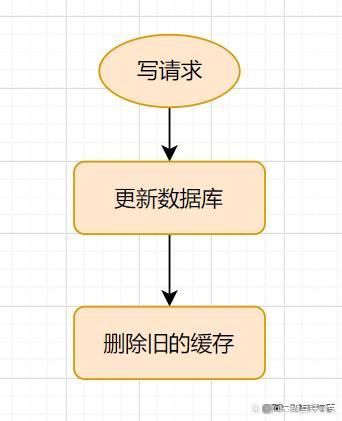
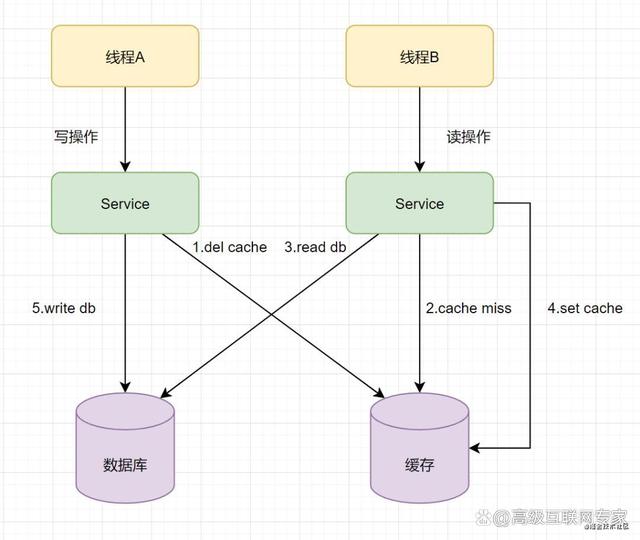
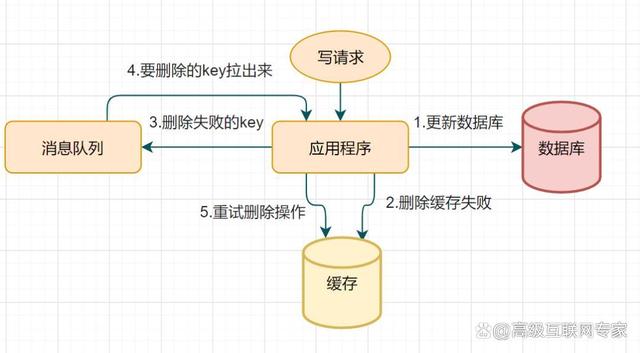
(1)加锁:
SETNX key value:当且仅当key不存在时,set一个key为value的字符串,返回1;若key存在,则什么都不做,返回0。
(2)设置锁的超时:
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动开释,避免死锁。
(3)开释锁:
del key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个下令。除此之外,我们还可以使用set key value NX EX max-lock-time 实现加锁,而且使用 EVAL 下令执行lua脚本实现解锁。
EX seconds : 将键的过期时间设置为 seconds 秒。 执行 SET key value EX seconds 的效果等同于执行 SETEX key seconds value 。
PX milliseconds : 将键的过期时间设置为 milliseconds 毫秒。 执行 SET key value PX milliseconds 的效果等同于执行 PSETEX key milliseconds value 。
NX : 只在键不存在时, 才对键举行设置操作。 执行 SET key value NX 的效果等同于执行 SETNX key value 。
XX : 只在键已经存在时, 才对键举行设置操作。
4.3.2、实现思路