IT评测·应用市场-qidao123.com技术社区
标题:
CUDA 编程学习 (5)——内存访问性能
[打印本页]
作者:
曂沅仴駦
时间:
2024-11-1 00:13
标题:
CUDA 编程学习 (5)——内存访问性能
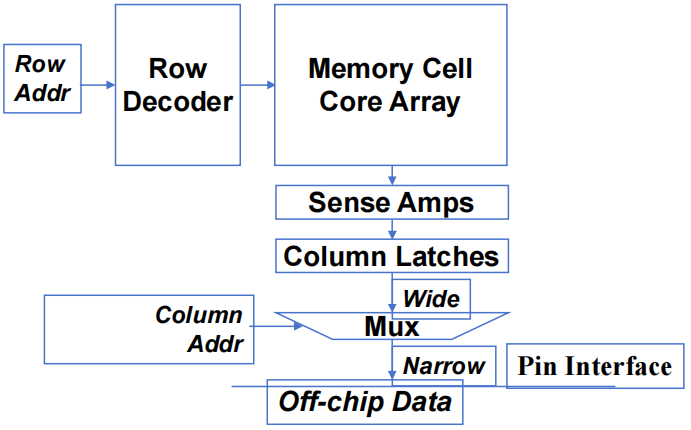
1. DRAM 带宽
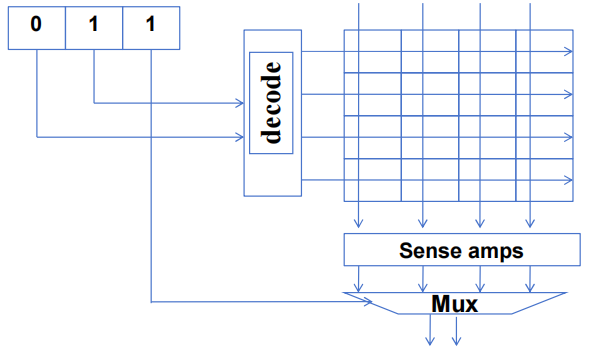
1.1 DRAM 核心阵列布局
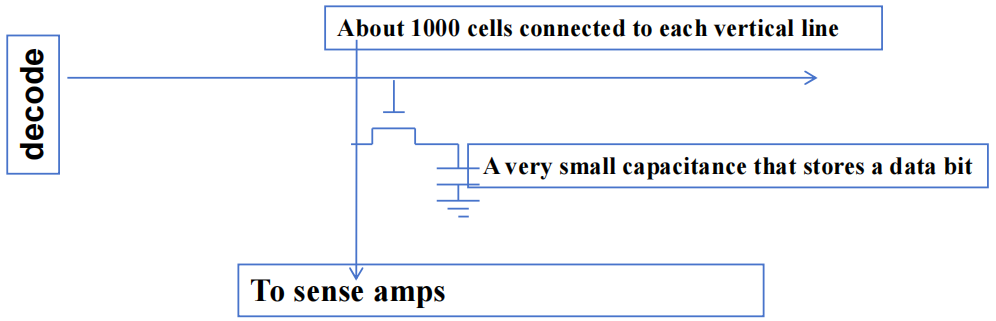
每个 DRAM 核心阵列约有 \(16M\) bits
每个 bits 存储在由一个晶体管组成的微小电容器中
超小型(8x2-bit)DRAM 内核阵列
1.2 DRAM 核心阵列速度慢
从核心阵列单元读取数据的过程非常缓慢
DDR
:Core speed = \(\frac{1}{2}\) interface speed
DDR2 / GDDR3
:Core speed = \(\frac{1}{4}\) interface speed
DDR3 / GDDR4
:Core speed = \(\frac{1}{8}\) interface speed
\(\cdots\) 之后可能会更糟
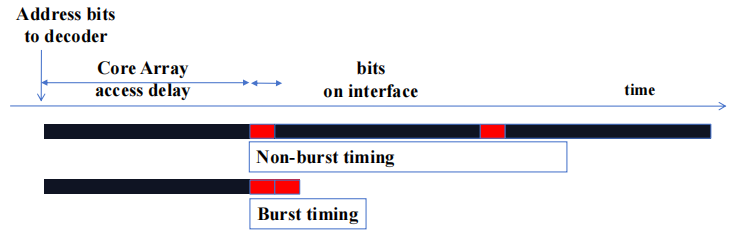
1.3 DRAM Bursting
对于 DDR{2,3} SDRAM 内核,时钟频率为接口速度的 \(\frac{1}{N}\):
将同一行的 DRAM bits 一次性加载(\(N × interface\ width\))到内部缓冲区,然后以接口速度分 N 步传输
DDR3 / GDDR4
:\(buffer\ width = 8X\ interface\ width\)
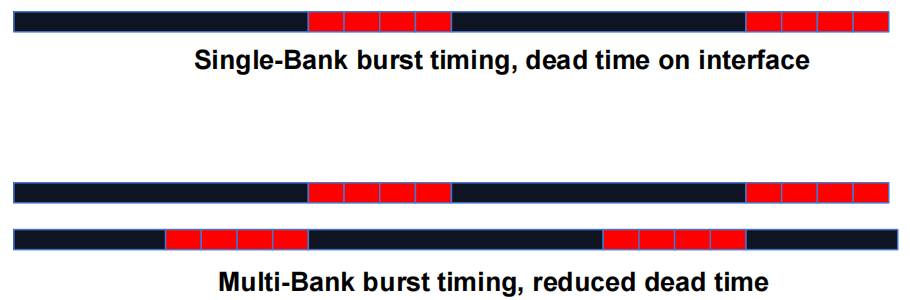
1.3.1 DRAM Bursting Timing 示例
今世 DRAM 系统设计为始终以 burst 模式访问。burst bytes 被传输到处理器,但在访问非连续位置时会被丢弃。
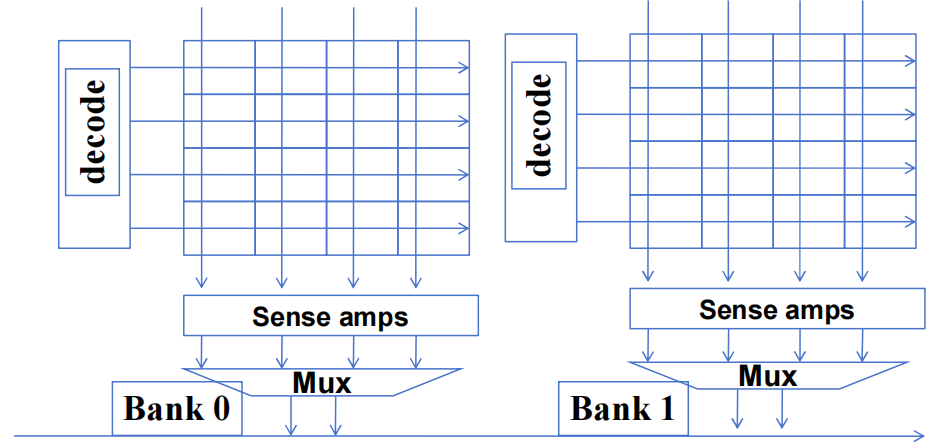
1.3.2 DRAM Bursting with Banking
多个 DRAM Banks 布局
DRAM Bursting with Banking
1.4 GPU 片外内存子系统
NVIDIA RTX6000 GPU
global memory 峰值带宽 = \(672GB/s\)
global memory (GDDR6) 接口 @7GHz
\(14\ Gbps\) 针脚速度
对于 GDDR6 32 位接口,我们只能维持约 \(56\ GB/s\) 的速度
我们需要更大的带宽(\(672\ GB/s\)), 因此需要 12 个 memory channels
2. CUDA 中的内存聚合
2.1 DRAM Burst —— 系统视图
每个所在空间被分别为 burst 段
每当访问一个位置时,同一 burst 段中的所有其他位置也会被传送到处理器中
根本示例如图:16-byte 所在空间,4-byte burst 段
实际上,我们至少有 4GB 的所在空间,burst 段大小为 128-byte 或更多
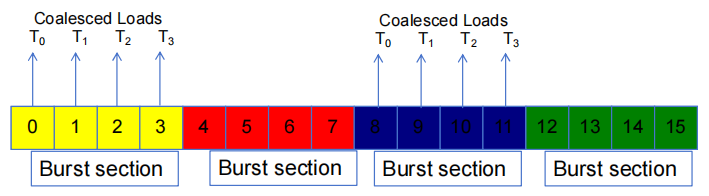
2.2 内存聚合
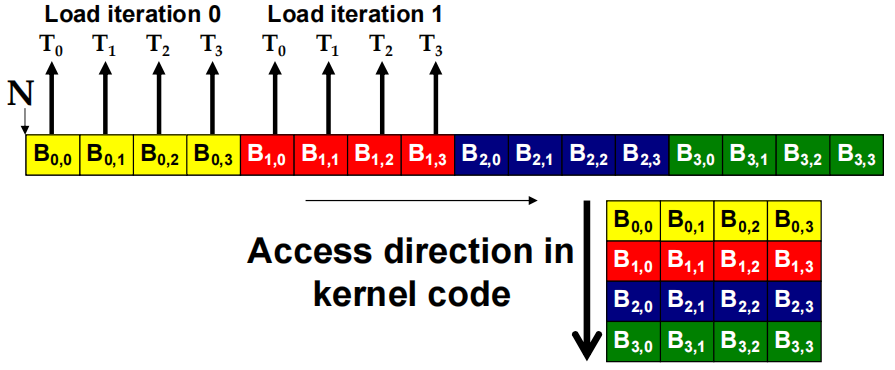
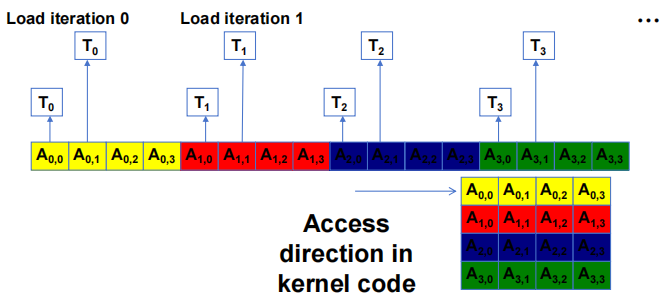
当一个 warp 中的所有 thread 都实验一个 load 指令时,如果所有被访问的位置都属于同一 burst 段,那么只会发出一个 DRAM 请求,而且访问是完全聚合的。
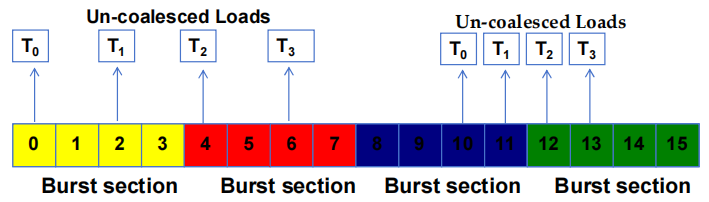
2.3 非聚合访问
当被访问的位置超过 burst 段边界时:
聚合失败
发出多个 DRAM 请求
访问未完全聚合
访问和传输的部分 bytes 未被 threads 使用
2.4 如何判定一个访问是否聚合
如果数组访问中的索引形式为
\[A[(expression\ with\ terms\ independent\ of\ threadIdx.x) + threadIdx.x]\]
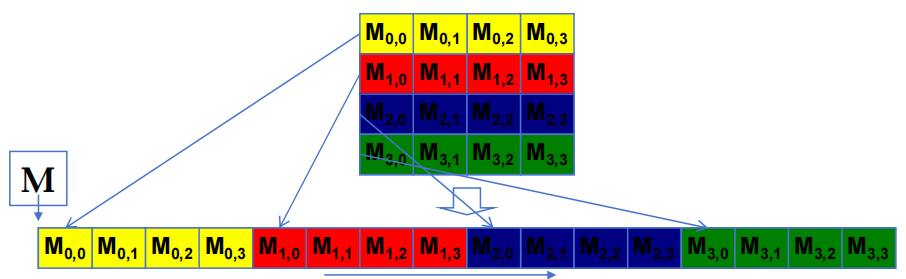
线性内存空间中的二维 C 阵列(按所在递增的线性化顺序)
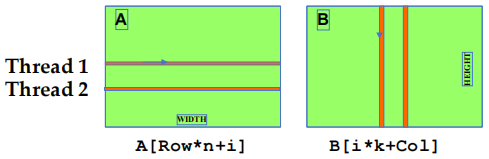
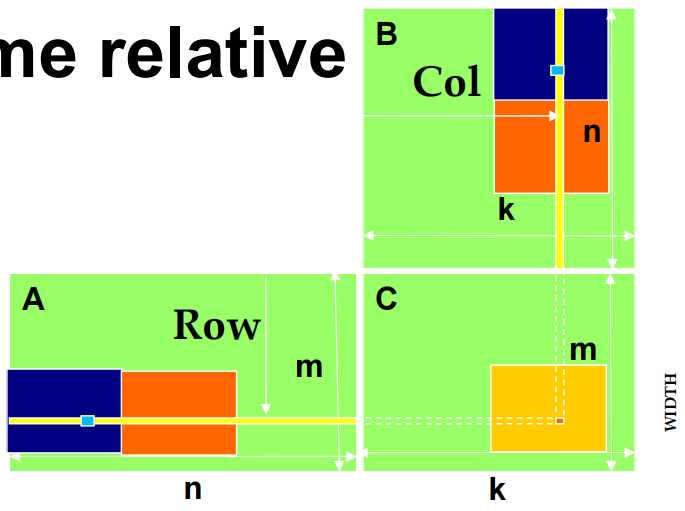
2.4.1 根本矩阵乘法的两种访问模式
i 是 kernel code 内积循环中的循环计数器,A 大小为 \(m\times n\),B 大小为 \(n\times k\)。
\[Col = blockIdx.x * blockDim.x + threadIdx.x\]
B 访问模式是聚合的
A 访问模式不是聚合的
2.4.2 加载输入 tiles
让每个 thread 在与其 C 元素相同的相对位置加载一个 A 元素和一个 B 元素。
int tx = threadIdx.x
int ty = threadIdx.y
访问 tile 0 2D 索引:
A[Row][tx]
B[ty][Col]
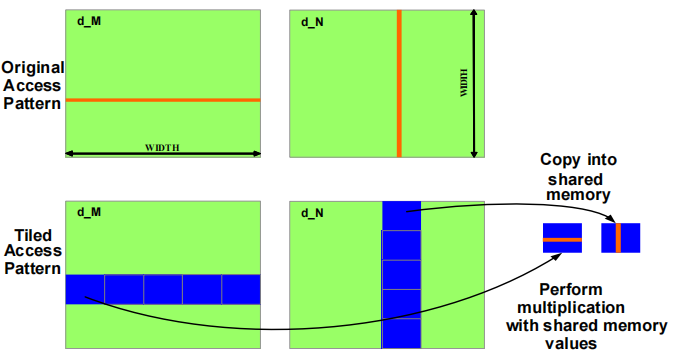
原始访问模式 (Original Access Pattern)
在左上角的 d_M 矩阵和右上角的 d_N 矩阵中,赤色线条代表传统的逐元素访问方式。在这种模式下:
每个线程直接从全局内存中获取所需的矩阵元素,并进行盘算。
这种访问方式可能导致频繁的全局内存访问,效率较低,因为每次访问都要从全局内存中读取数据。
分块访问模式 (Tiled Access Pattern)
在分块访问模式中:
d_M 和 d_N 矩阵被分成多个小块(蓝色区域),每个小块会被加载到共享内存中。
每个线程块只需要将其负责的矩阵 tile 拷贝到共享内存,然后对共享内存中的数据进行盘算。
通过将小块 tile 加载到共享内存中,线程可以更快地重复使用共享内存中的数据,从而减少了全局内存的访问频率,提高了整体性能。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4