复制代码
假如同时集群下存在多种配额设置参数,以优先级高的配额设置为准。
举一个例子解释限流优先级:假如指定一个 user,userA 设定他的 producer_byte_rate 为 10M/s,同时该集群上还为所有 user 的都设置了默认 producer_byte_rate 为 50M/s,以及为默认值下还设置了 client-id 粒度的配额;此时假如那 user 认证的生成程序向集群生产,生产速率的配额,应该以 user 指定为准,即为 10M/s。(第 3 级优先于第 5 级)
限流算法:
我们假设当前实际速率是 O,T 是预设的 user 限流速率值(可以根据实际环境设置),而 W 表示某一段时间范围,我们盼望在 W 时间内 O 可以或许下降到 T 以下(假如 O 本来就比 T 小,则什么都不用做),那么 broker 端就必要延缓等候一段时间后再相应请求。假如假设这段时间是 X,那么以下等式建立:
O * W = (W + X) * T
由此得出 X = (O - T) / T * W。这就是 Kafka 用于盘算限流等候时间的公式。当然在具体实现时,Kafka 提供了两个参数来共同盘算 W:W = quota.window.num * quota.window.size.seconds。前者表示取样的时间窗口个数,后者表示时间窗口大小。
超额处理:
消息队列自己的功能是削峰填谷,在有突发流量的时候,流量很容易凌驾配额。此时,机器层面一样平常是有本领处理流量的,假如直接拒绝流量,就会导致消息投递失败,客户端请求非常。所以,在限流后,Kafka 的处理方式是延时回包,通过加大单次请求的耗时,整体上降低集群的吞吐。因为正常状态下,客户端和服务端的毗连数是稳定的,假如提升单次处理请求的耗时,集群整体流量就会相应下降。增长的耗时时长就是使用上述的限流算法盘算的。
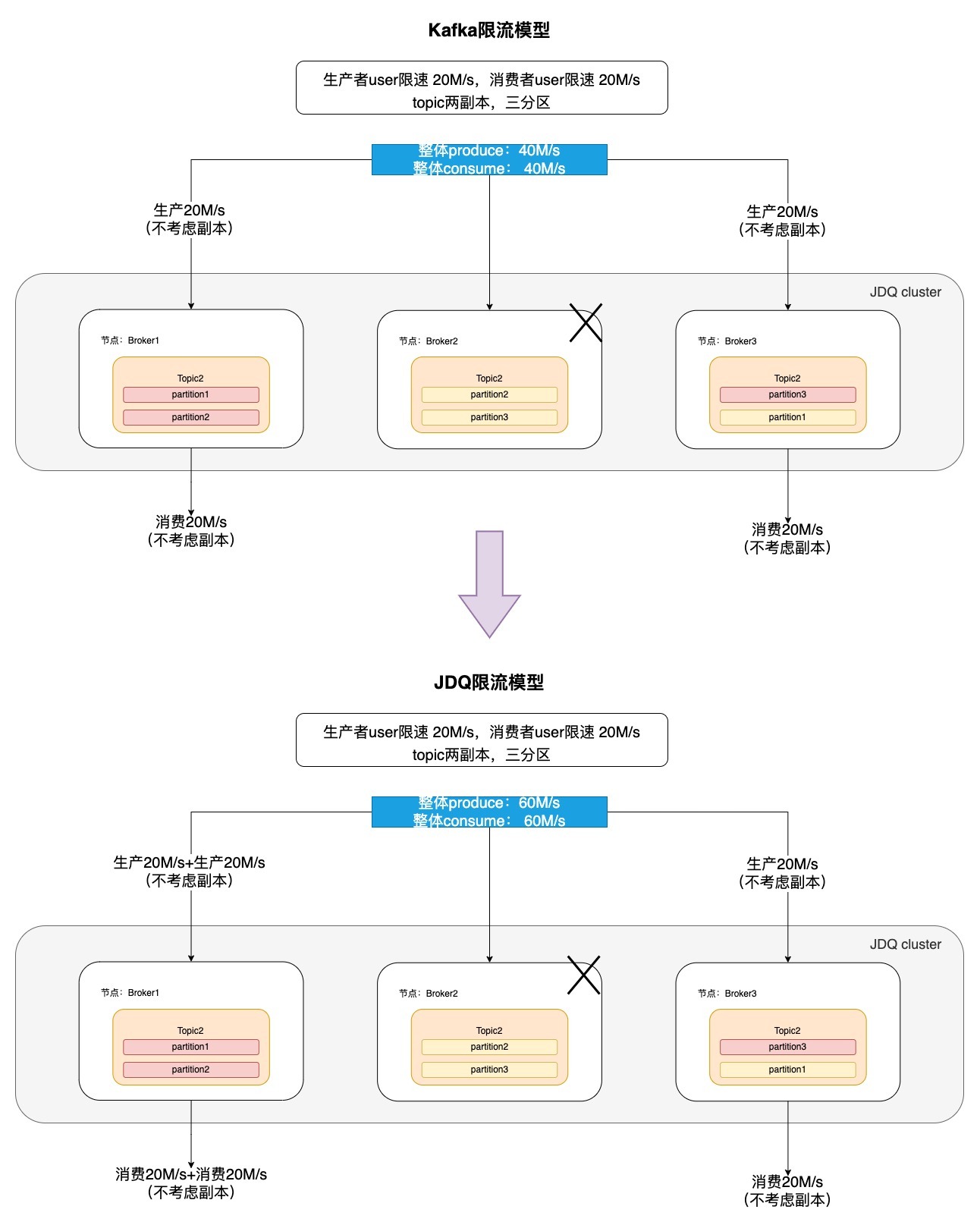
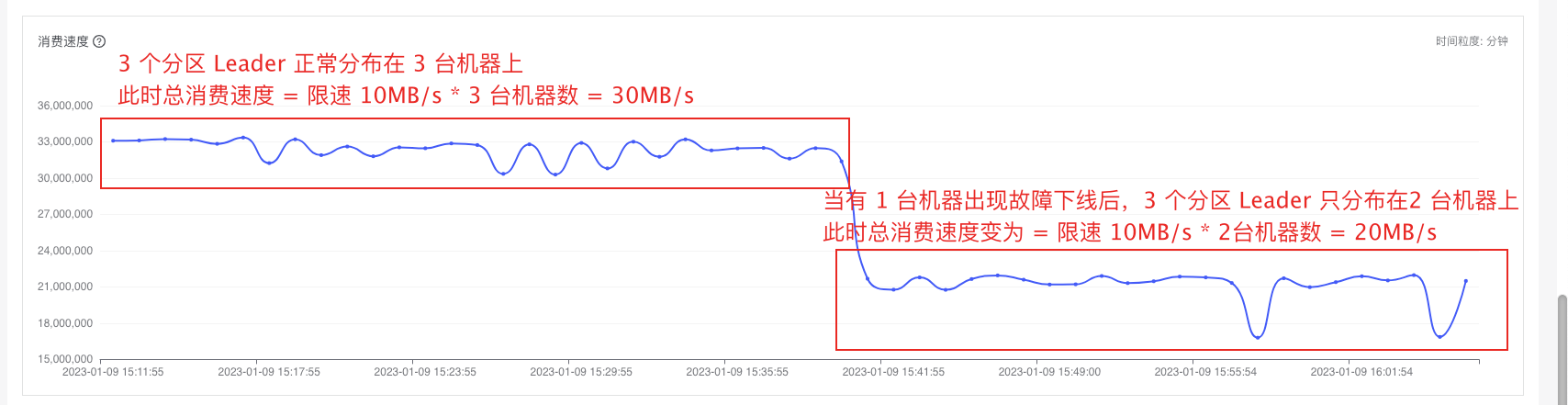
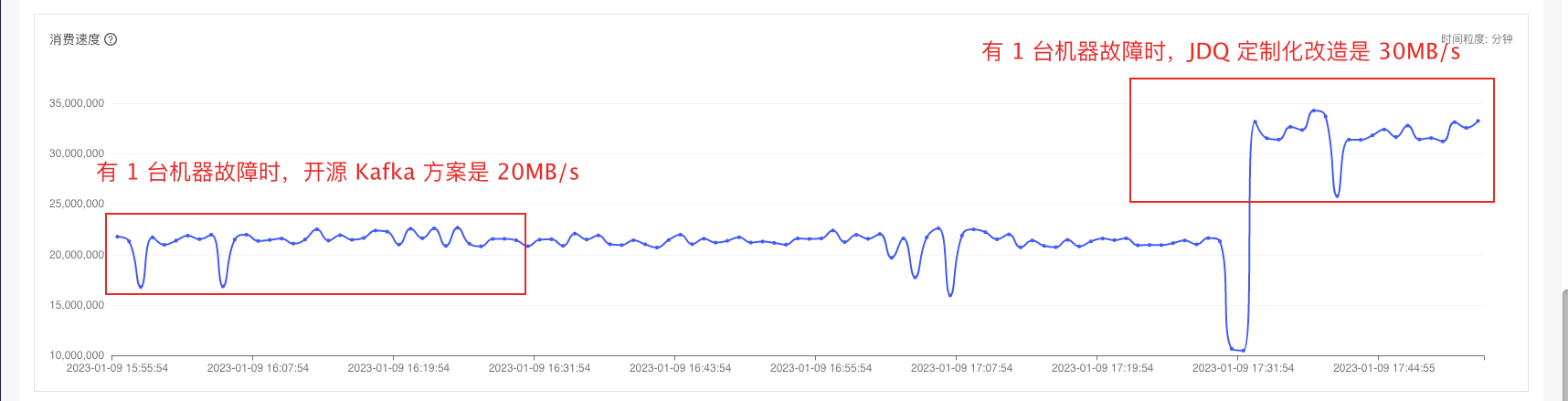
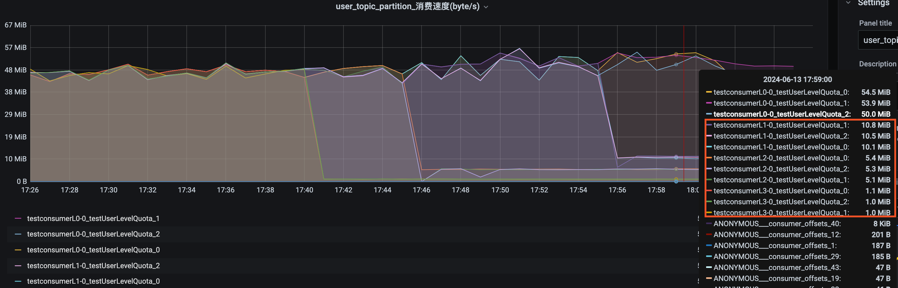
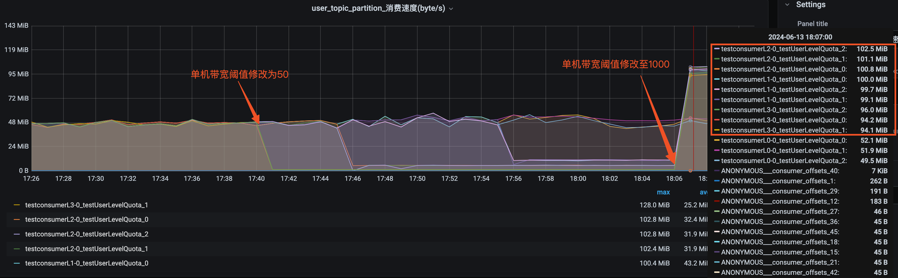
2.3 Kafka 限流举例