IT评测·应用市场-qidao123.com技术社区
标题:
AI与OCR:数字档案馆图像扫描与文字识别技术实现与项目案例
[打印本页]
作者:
张春
时间:
2024-11-12 23:25
标题:
AI与OCR:数字档案馆图像扫描与文字识别技术实现与项目案例
文末有免费工具可在线体验,或者网络搜索关键词“思通开源AI本领平台”
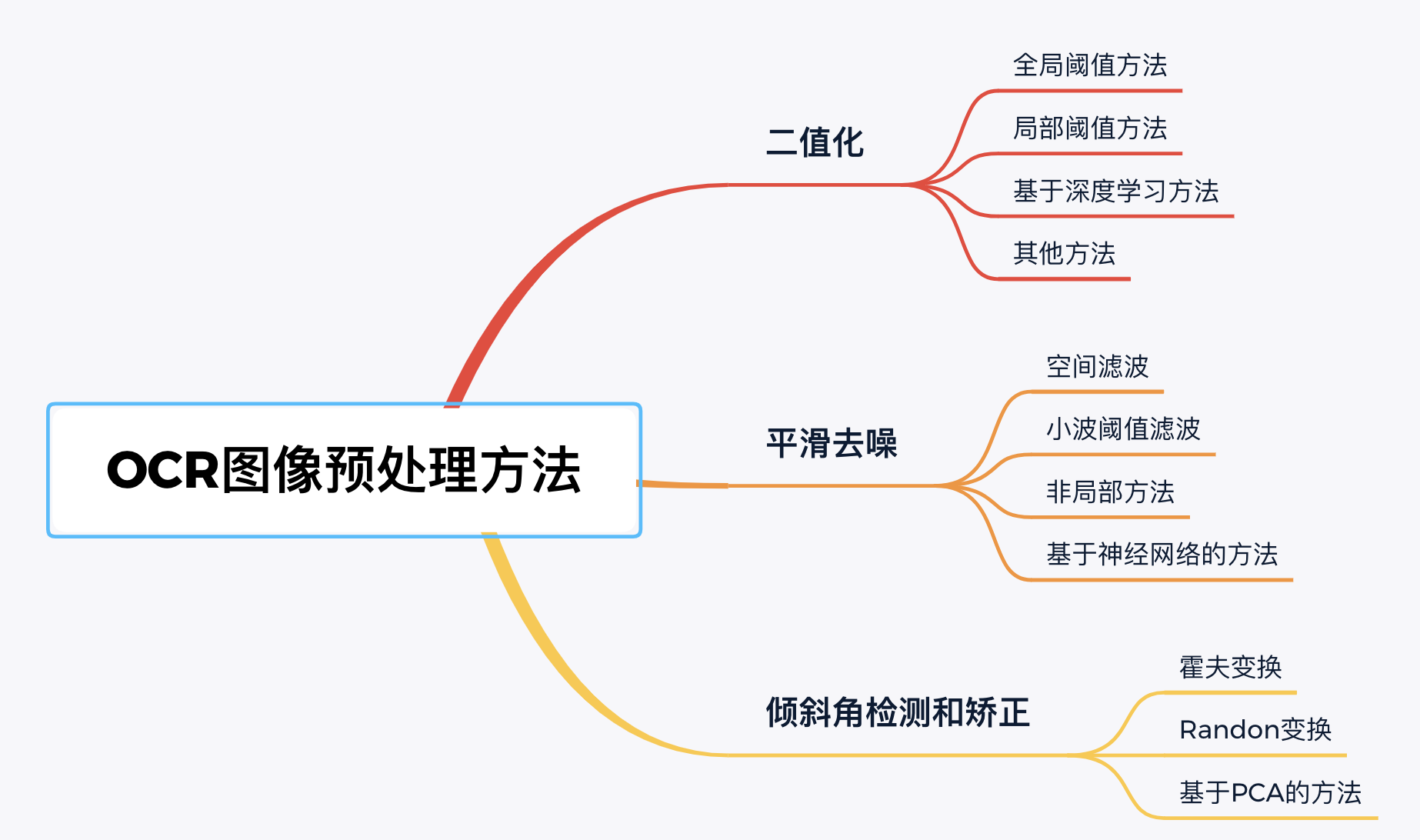
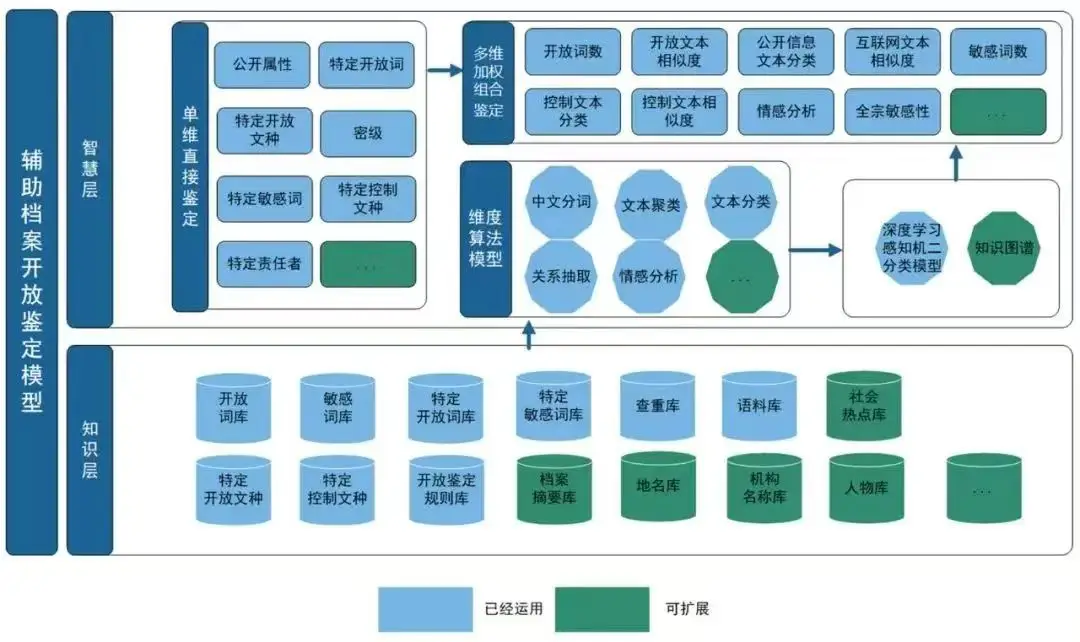
一、扫描与图像预处置惩罚
技术实现过程
在纸质档案的数字化过程中,起首需要使用高精度扫描仪对纸质文档进行扫描,生成高清的数字图像。这一步骤是整个OCR流程的基础,图像的质量直接影响到后续识别的准确性。图像预处置惩罚技术包括去噪、增强对比度、校正倾斜和图像增强等,这些操作有助于进步图像质量,减少识别错误。
如图所示,这是图像增强对比之前的照片
如图所示,采用直方图平衡化算法对图像增强对比之后的照片
核心技术要点
图像质量提拔
:在数字档案馆中,图像质量提拔是确保OCR识别准确性的关键。通过去噪声、灰度化和二值化处置惩罚,以及对比度调整等步骤,可以有用进步图像的清晰度和可识别性。例如,使用中值滤波器和高斯滤波器去除图像中的尘土和划痕,将彩色图像转换为好坏两色以区分文字与背景,并通过直方图平衡化技术增强文字对比度,这些措施共同为OCR识别提供了高质量的图像基础。
自动化预处置惩罚
:数字档案馆采用了自动化预处置惩罚流程,该流程包括图像校正、去除噪声、对比度调整以及自动边界检测与切割等步骤。这一流程可以大概自动适应差别质量的原始文档,通过消除倾斜、优化图像清晰度、增强文字对比度以及精准切割文字区域,有用提拔了OCR识别的精度和速度,使得纸质档案的数字化转换更为高效和准确。
二、自动边界检测与切割
档案馆中的文件有时包含多个部分,如表格、文字和图片。AI平台使用边界检测算法来自动识别文档的边沿,从而准确地截取文件中的文字区域,并过滤掉空缺边沿或杂物(例如钉孔、污渍等)。边界检测功能在对单张大幅度的档案文件进行识别时,能自动检测出各个需要识别的区域,有用避免误识别和多余信息干扰。
技术实现过程
在自动边界检测与切割的过程中,起首通过图像二值化强化文字与背景的对比度,然后使用轮廓检测算法如cv2.findContours识别图像中的文本行轮廓,接着通过cv2.boundingRect等算法拟合边界矩形以精确定位文本区域,末了根据这些边界矩形从原始图像中切割出文字区域,为后续OCR识别做好准备。
核心技术要点
智能切割
:通过上述算法精确识别并切割出文档中的文字区域。这一步骤的关键在于可以大概准确地区分和定位文本区域,以便进步识别服从和准确性。
多区域识别
:对于包含多个内容区域的文档,如表格、多栏文本等,算法需要可以大概准确识别并分别处置惩罚每个区域。这通常涉及到更复杂的图像分析技术,如结构分析,以识别图像中的文本区域、非文本区域以及文本的结构信息,如列、行、块、标题、段落、表格等。
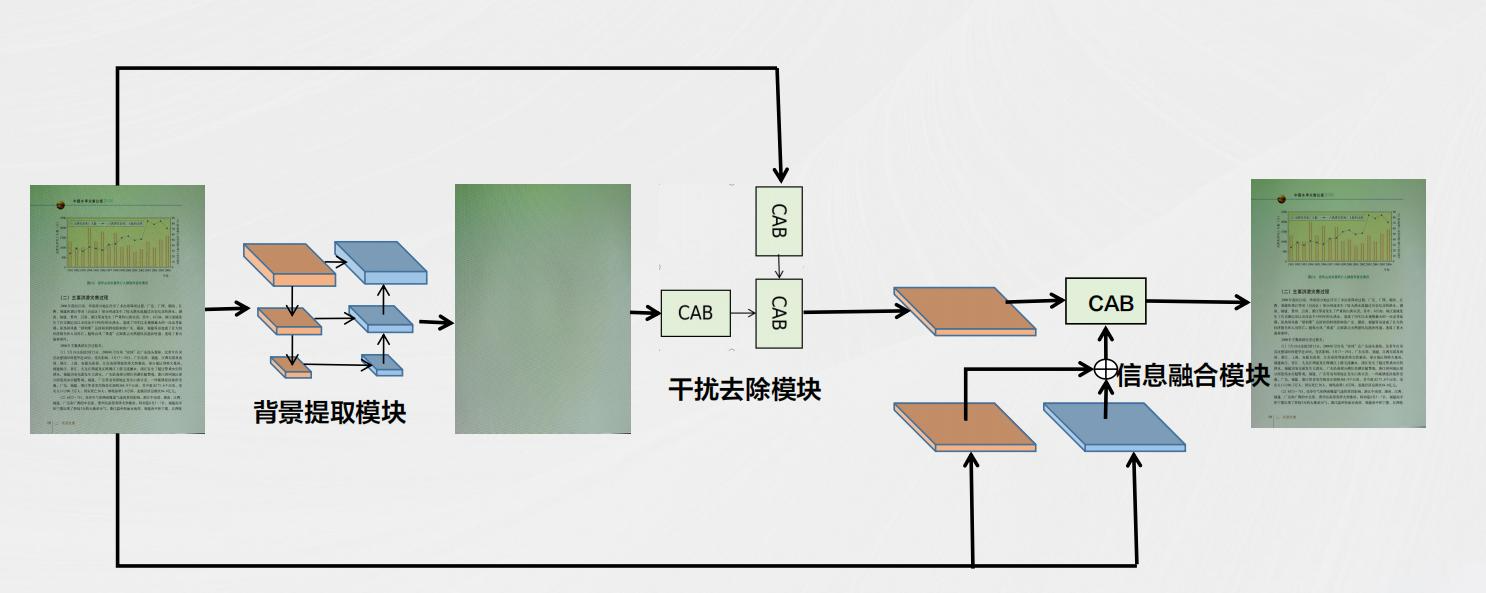
三、文字与图片分离抽取
档案文件中通常包括文字和图片(例如签名、图示等),而OCR识别更适用于文字。AI平台可以先对图像进行分析,使用图像识别技术区分出文字部分和非文字部分,自动屏蔽图片区域或标签区域,以便专注于文字识别。通过这种方式,可以避免图像干扰,提拔文字提取的精度。
技术实现过程
通过图像识别技术,区分文档中的文字和图片(如签名、图示等)。这一步骤的目的是在OCR识别前,将非文字元素从处置惩罚流程中排除,以减少干扰。
核心技术要点
图像内容分析
:使用图像识别技术,准确区分文字和非文字内容。
区域屏蔽技术
:自动屏蔽非文字区域,确保OCR识别的准确性。
四、档案识别与文本提取
在完成预处置惩罚后,系统会对图像中的文字部分进行OCR识别,提取出文档内容。OCR模子可以支持多种字体识别,包括手写体、打印体以及一些汗青文档中的复古字体。别的,平台的OCR识别支持大批量自动处置惩罚,可以设定使命流水线,使得大量文档能在短时间内处置惩罚完毕。识别后的文本可以进一步结构化存储,便于后续的查找和管理。
技术实现过程
在图像预处置惩罚和区域切割之后,系统将对图像中的文字部分进行OCR识别,提取出文档内容。这一步骤涉及到多种字体的识别,包括手写体、打印体和复古字体等。
核心技术要点
多字体识别
:OCR模子需要支持多种字体的识别,以适应差别汗青时期和类型的文档。
批量处置惩罚本领
:平台需要支持大批量文档的自动处置惩罚,以进步工作服从。
五、识别结果自动生存
识别完成后,系统会将结果转化为数字文档,并存入档案管理系统中。这些数字化的文本不仅可以生成PDF或Word文档,还可以直接生存为结构化数据库格式,便于后续的检索和分析。同时,系统可以为每个数字化文件自动生成日期、类型等元数据信息,便于后续的查询和档案整理。
技术实现过程
识别完成后,系统将把识别结果转化为数字文档,并存储到档案管理系统中。这些文档可以是PDF、Word格式,也可以直接生存为数据库格式,以便于后续的检索和分析。
核心技术要点
结构化存储
:将识别后的文本结构化存储,便于管理和检索。
元数据管理
:为数字化文件自动生成和管理元数据,如日期、类型等,以便于档案的整理和查询。
六、相干案例介绍
在江西省某地质资料档案馆的项目中,档案数字化需求尤为迫切,涉及大量贵重的汗青文件,这些文件承载了紧张的地质文化专业信息,但同时面对着因纸质老化而难以长期生存的挑战。思通数科AI平台的引入,极大地提拔了档案数字化的服从和质量。
具体应用流程
在该项目中,档案馆起首通过高精度扫描装备对档案进行数字化,随后平台自动进行图像预处置惩罚,去除图像中的噪点和不清晰区域,确保档案文字在后续OCR识别中保持高度清晰。在OCR识别过程中,平台支持多种字体,包括汗青档案常见的仿宋体、行书体和部分手写体,确保档案馆中各类文件的识别准确性。识别出的文字和数据以结构化方式生存到档案管理系统,系统会自动生成文件日期、文档类型等元数据。
应用成效
1.
大规模批量处置惩罚
:平台的批量处置惩罚功能让馆方可以大概快速高效地处置惩罚上万页档案文献,识别速度提拔至每小时500页,极大地节省了人力资源。
2.
智能化检索与管理
:识别后的档案文档可通过关键词、时间段、文档类型等字段快速检索,支持全文搜索功能,为研究人员提供了便捷高效的在线查阅体验。
3.
生存汗青遗产
:通过思通数科平台,档案馆得以完整保留汗青文档的内容与细节,不仅保护了贵重的文化遗产,也为公众提供了可持续的档案使用服务。
七、产品体验
产品体验地点:语音视频&文本图片多模态AI本领引擎平台
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4