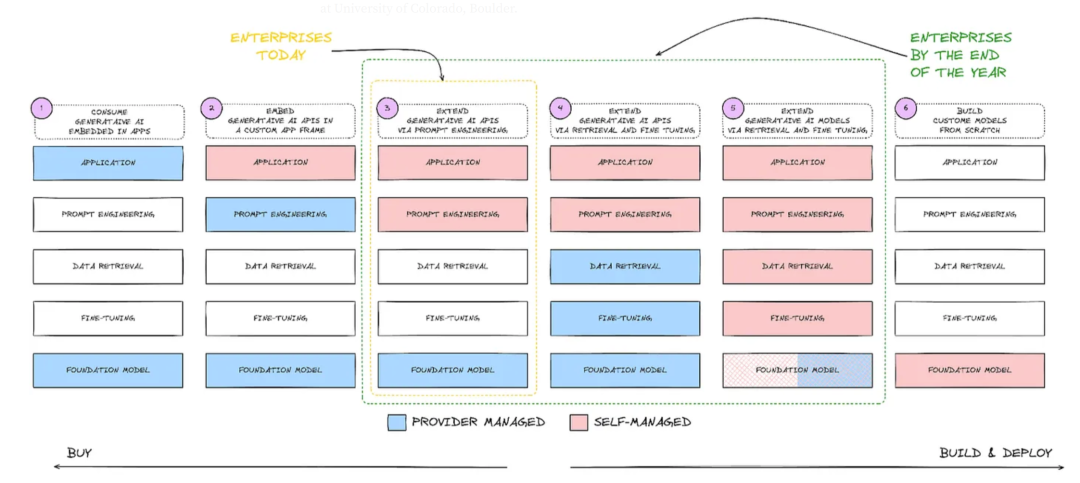
阶段1 - 消费型生成AI(Consume Generative AI Embedded in Apps):
通过使用现成的模子满足广泛的用例。在这一阶段,企业通过购买服务来消费嵌入应用中的生成AI,这是提供商管理的。
阶段2 - 嵌入生成型AI(Embed Generative AI in Custom App Frameworks):
根据用户定义的应用步伐使用模子。此阶段的企业在其定制应用框架中嵌入生成AI。
阶段3 - 通过提示工程扩展生成AI(Extend Generative AI via Prompt Engineering):
使用提示工程训练模子以产生所需的输出。在这一阶段,企业开始通过提示工程来扩展AI的功能,这通常还是提供商管理的。
阶段4 - 通过数据检索和微调扩展生成AI(Extend Generative AI via Retrieval and Fine-Tuning):
在用户端使用提示工程,同时深入了解数据检索和微调,这些仍然主要由LLM提供者管理。企业进一步扩展AI应用,通过数据检索和微调来增强模子的功能,仍然是提供商管理。